Open source
Applying flame graphs outside of performance analysis
By
Wednesday, 11 August 2021
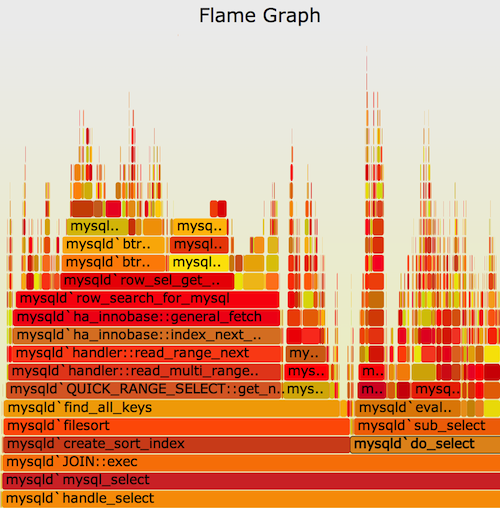
Flame graphs have become an industry standard for CPU performance analysis. This visualization excels at showcasing the distribution of a sample (percentage of time a stack was on CPU) with hierarchical structure (call stack depth). However, flame graphs have seen sparse adoption outside of performance related use cases [1].
1For those unfamiliar with flame graphs and their CPU profiling application, Brendan Gregg (the creator) has a great introduction on his website.
The Observability team at Twitter develops our in-house time series database (MetricsDB), which has seen tremendous growth over the past year. Twitter’s metric usage typically increases 30-40% annually, but recently we’ve been tracking 60% annual growth. This has put strain on our systems and staying ahead of this growth is a constant focus for our team. To improve our capacity planning, we wanted to determine which scaling factors were significant contributors to the increases in metric ingestion.
Before diving into our investigation, it helps to understand how metrics are ingested at Twitter. Every service runs a side-car process, which scrapes a service’s metrics endpoint every minute, and sends the data to our ingestion service as illustrated below.
The first attempt to identify these scaling factors was to find the largest services, collect their /admin/metrics.json endpoint output, and analyze what trends were present. The metrics endpoint returns JSON, where the keys are the metric names and the values are the metric values as seen below.
{
"clnt//s/stratostore/stratoserver/pending" : 0.0,
"clnt//s/stratostore/stratoserver/pending_io_events" : 0.0,
"clnt//s/stratostore/stratoserver/protocol/thriftmux" : 1.0,
"clnt//s/stratostore/stratoserver/read_timeout" : 0,
"clnt//s/stratostore/stratoserver/received_bytes" : 131871,
"clnt//s/stratostore/stratoserver/request_latency_ms.count" : 0,
"clnt//s/stratostore/stratoserver/requests" : 0,
"clnt//s/stratostore/stratoserver/retries/budget" : 100.0,
"clnt//s/stratostore/stratoserver/retries/budget_exhausted" : 0,
"clnt//s/stratostore/stratoserver/retries/cannot_retry" : 0,
"clnt//s/stratostore/stratoserver/retries/not_open" : 0,
"clnt//s/stratostore/stratoserver/retries/request_limit" : 0,
"clnt//s/stratostore/stratoserver/retries/requeues" : 0,
"clnt//s/stratostore/stratoserver/retries/requeues_per_request.count" : 0,
"clnt//s/stratostore/stratoserver/sent_bytes" : 131983,
"clnt//s/stratostore/stratoserver/singletonpool/connects/dead" : 0,
"clnt//s/stratostore/stratoserver/singletonpool/connects/fail" : 22,
"clnt//s/stratostore/stratoserver/success" : 0,
"clnt//s/stratostore/stratoserver/tls/connections" : 0.0,
"clnt//s/stratostore/stratoserver/write_timeout" : 0,
...
}
The problem with this approach is that this JSON can contain over 100,000 metrics for large services (each JSON key corresponds to a unique metric). The Stratoserver service shown above exports over 172,000 metrics for a single instance. The following command demonstrates the metric count:
$ curl -s 'localhost:31033/admin/metrics.json?pretty=true' | wc -l
172691An important thing to note about Twitter metrics is that they typically have a hierarchy delimited by ‘/’ characters. For example, the Stratoserver seen above has a top level clnt/ keyspace. This contains all the metrics about the downstream services it uses. The command below shows that Stratoserver is using over 200 clients:
$ cat strato.json | jq 'keys
| map(select(startswith("clnt/")))
| (map(split("/"))
| map(nth(2)))
| sort
| unique' | wc -l
230We were able to draw conclusions with jq and other Unix tools, but the process was time consuming and lacked a more holistic view.
To derive the insights we were looking for, we needed answers to the following questions:
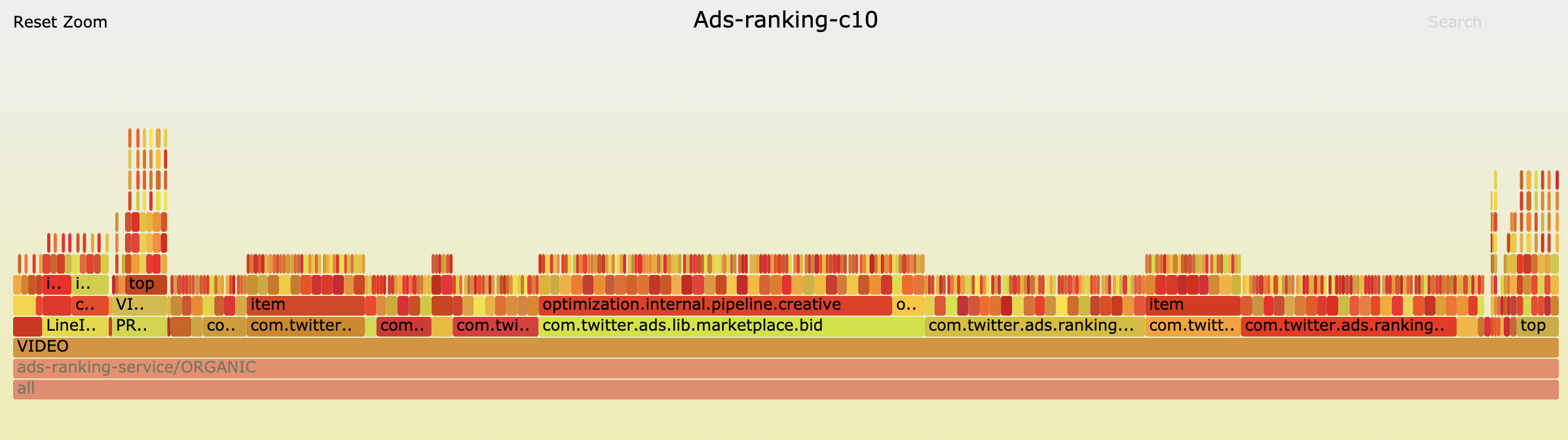
We realized that flame graphs could provide the answers to these questions. For example, below you will find a flame graph of the ads-ranking-c10 service. Each sample in the flame graph corresponds to an individual metric showing which features account for the largest metric usage.
The visualization below reveals that the following metric keyspaces:
These account for roughly 83% of this service’s metric footprint.
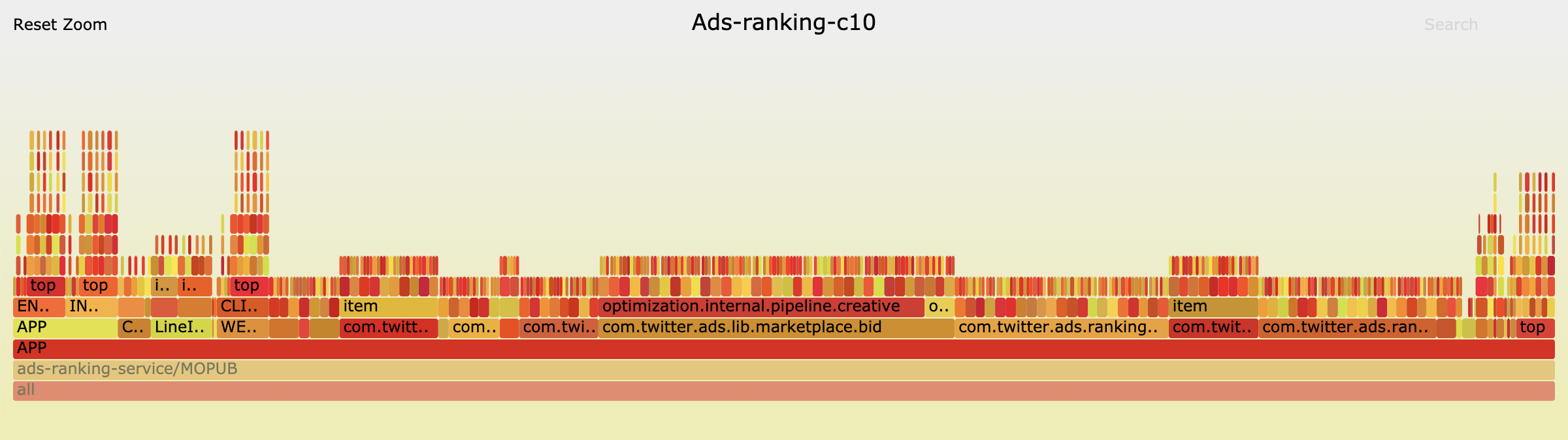
Zooming into the APP and VIDEO towers reveals a closer look at the similar features they contain.
This identified that ads services have a “display location” concept, which represents the different ad products Twitter offers. These 15 display locations cause a 15x multiplier for 83% of their metrics. Since this service is responsible for 3.2 billion metrics, adding a new display location will cause an increase of 180 million metrics.
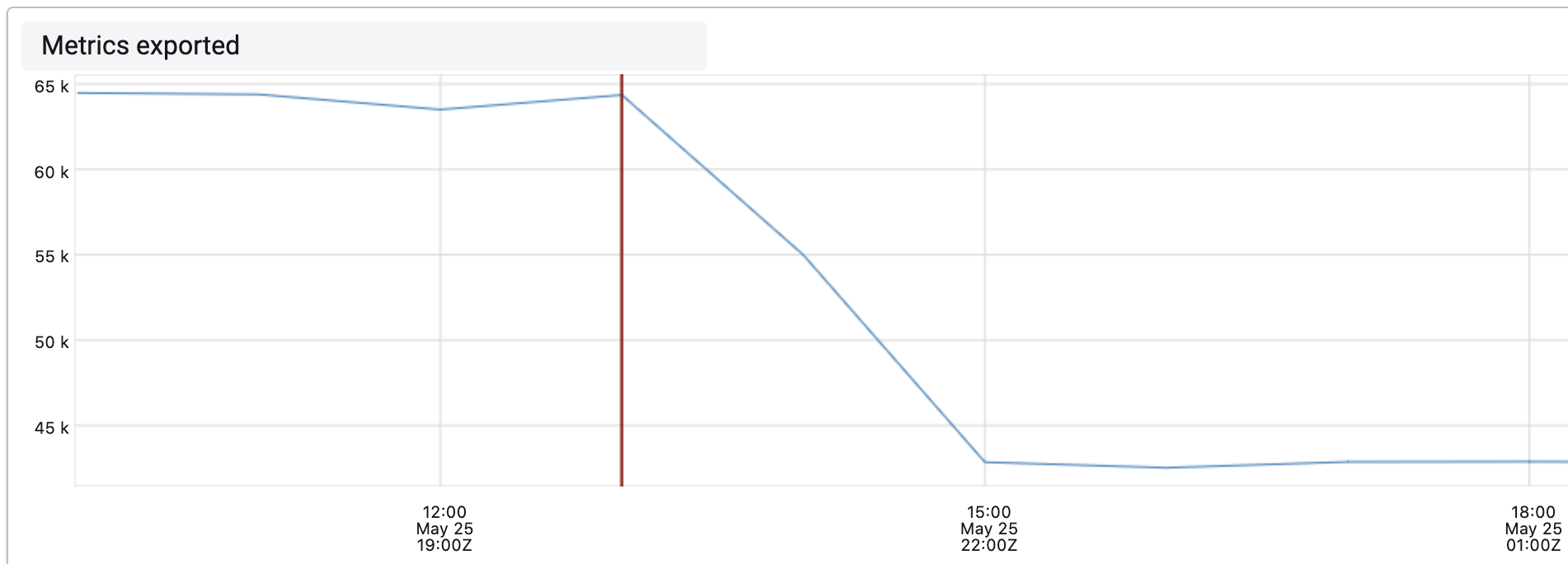
These flame graphs allowed our Ads team to identify what metrics were abundant but low value. These insights led to a 33% reduction in the Ads team’s metric usage. Since they run some of the largest services at Twitter, this reduction eliminated 1 billion metrics (7% of Twitter’s total metrics). Without flame graphs, the Ads team would not have had confidence in what metrics to focus on or the magnitude of the optimization.
This ad hoc flame graph generation is just the start for providing service owners with metric analytics and predicting the Observability team’s future capacity needs. We are currently proposing adding these flame graphs to Twitter’s internal infrastructure billing system, which provides teams with their weekly metric utilization cost. Prior to this, it was difficult to investigate why utilization changed. Future additions could include coloring the flame graph towers based on whether metrics are queried or read. For example, blue could represent unused metrics; orange, infrequently read metrics; red, frequently read metrics.
Flame graphs are an underutilized tool outside of performance, and abundant use cases could benefit from them. If your data has a hierarchical structure and you are interested in the distribution of the samples, flame graphs can provide powerful insight.
[1] Brendan Gregg maintains a list of flame graphs use cases (in the “Updates” section on his website). This highlights two use cases outside of performance analysis (one of which is Brendan’s). Even though this isn’t the first application, it is very rare to see it used elsewhere.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.