Open source
Reinforcement Learning for Torch: Introducing torch-twrl
By
Friday, 16 September 2016
Advances in machine learning have been driven by innovations and ideas from many fields. Inspired by the way that humans learn, Reinforcement Learning (RL) is concerned with algorithms which improve with trial-and-error feedback to optimize future performance.
Board games and video games often have well-defined reward functions which allow for straightforward optimization with RL algorithms. Algorithmic advances have allowed for RL to be in real-world problems, such as high degree-of-freedom robotic manipulation and large-scale recommendation tasks, with more complex goals.
Twitter Cortex invests in novel state-of-the-art machine learning methods to improve the quality of our products. We are exploring RL as a learning paradigm, and to that end, Twitter Cortex built a framework for RL development. Today, Twitter is open sourcing torch-twrl to the world.
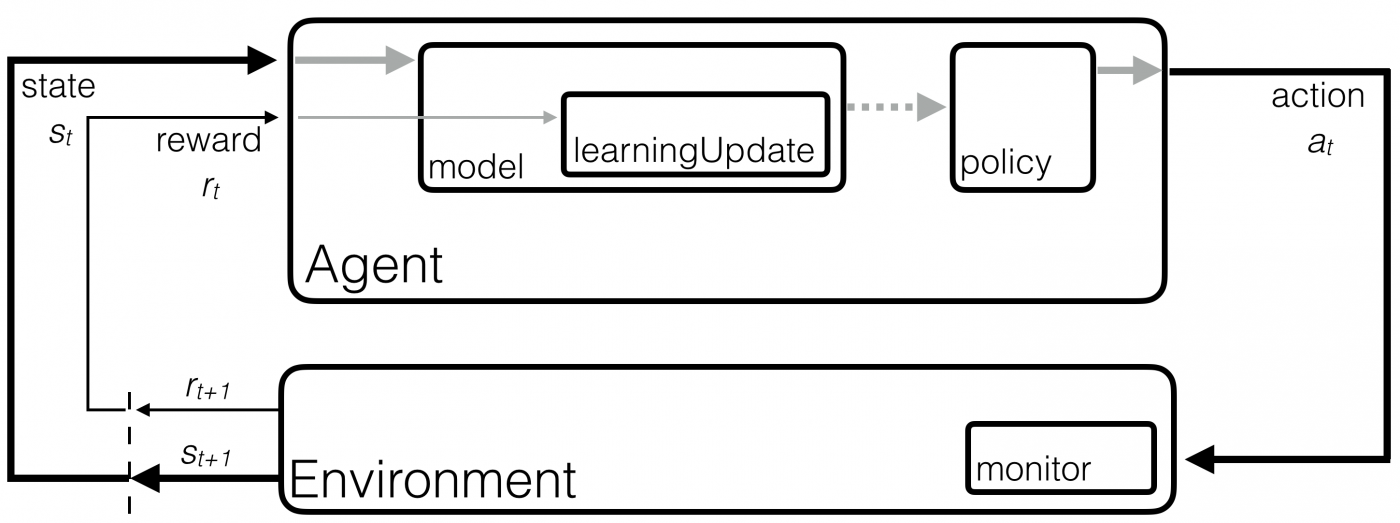
RL algorithms (or agents) aim to learn to perform complex, novel tasks through interaction with the task (or environment). To develop effective algorithms, rapid iteration and testing is important, torch-twrl aims to make implementing and innovating fast and easy.
Inspired by other RL frameworks, torch-twrl aims to provide:
Gym provides an extensive collection of RL environments; torch-twrl interacts with these environments through the HTTP API. torch-twrl provides a simple and modular way for developers to start working with RL within their existing Torch / Lua code.
If you want to start playing with torch-twrl, you can find the main package at https://github.com/twitter/torch-twrl, follow the installation instructions and you will be solving RL problems in no time.
git clone -- recursive ssh://[email protected]/twitter/torch-twrl.git
cd torch-twrl
luarocks maketorch-twrl makes developing and testing RL algorithms and environments easy. Here is a working example to take you through solving a classic RL control problem. To give you a feel for how easy it is, we have included a convenient script to run a basic policy gradient [Williams, 1992] agent for the classic RL Cart Pole task [Barto et al., 1983]:
th testScript.lua -env 'CartPole-v0' \
-policy categorical -learningUpdate reinforce -model mlp \
-nSteps 1000 -nIterations 1000 -video 0 \
-uploadResults true -renderAllSteps falseTo run an experiment, set your environment and agent experimental parameters. Agents require a policy, a model, and a learning update with relevant parameters.
The results above are from the OpenAI Gym Leaderboard. When you run an algorithm using torch-twrl there is an option to automatically upload your results to the Leaderboard which automatically creates a nice results plot, and builds a short GIF of your results.
The leaderboard is also valuable for comparing your results with other implementations.
The basic RL framework has an agent interacting with an environment. The agent is composed of:
Note:Many other parameters can be set which may be specific to policies, learning updates, models, and monitoring and are thus more completely described in the documentation.
We are hoping torch-twrl continues to grow as an RL framework, similar to RLLab [Duan et al. 2016], for developers working in Torch and Lua. RL research is an active field and includes a wide variety of environments and implementations of state-of-the-art algorithms; we plan to grow our library of new RL algorithms.
While there are other good RL frameworks based on torch [rl-torch], [Kaixhin/Atari], we wanted a framework built from scratch with minimal external dependencies so that it is easily compatible with our internal stack at Twitter.
To help you get started, we include a minimal random agent, a Policy Gradient agent based on REINFORCE [Williams 1992], and TD(Lambda) with SARSA and Q-Learning [Sutton and Barto, 1998]. If you want to contribute, we accept pull-requests and issues at torch-twrl on GitHub.
Enjoy torch-twrl. We are excited for your feedback and future development.
The core work on torch-twrl was done by Kory Mathewson, an intern with Twitter Cortex. A big thank you to Arjun Maheswaran, Clement Farabet, and Hugo Larochelle for development and testing support.
Barto, A. G., Sutton, R. S., & Anderson, C. W. (1983). Neuronlike adaptive elements that can solve difficult learning control problems. Systems, Man and Cybernetics, IEEE Transactions on, (5), 834-846.
Sutton, R. S., & Barto, A. G. (1998). Reinforcement learning: An introduction. Cambridge: MIT press.
Williams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning 8.3-4:229-256.
Duan, Y., Chen, X., Houthooft, R., Schulman, J., Abbeel, P (2016). Benchmarking Deep Reinforcement Learning for Continuous Control. Proceedings of the 33rd International Conference on Machine Learning (ICML).
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.