Insights
Next generation data insights using natural language queries
By
Thursday, 10 February 2022
At Twitter, we process approximately 400 billion events in real time and generate petabyte (PB) scale data every day. There are different ways in which various teams at Twitter harness this data to build a better Twitter for everyone.
Taking a broad view, we could cluster the infrastructure and tools of a comprehensive and robust big data platform into three categories - data processing, data storage, and data consumption. Across the industry we have powerful infrastructure for processing petabytes of data (such as Spark, Cloud Dataflow, Airflow) and storing voluminous data such as distributed blobstores (GCS, S3, Hadoop, Columnar DBs, BigQuery). However, non-trivial challenges still exist in gathering timely, meaningful, and actionable insights from these exabyte-scale data platforms through dashboards, visualizations, and reports.
One of the biggest hurdles with current data-consumption products used in the industry is that there is a need for backroom processing where engineers and analysts need to create dashboards, reports etc. before consumption. This leads to challenges:
Over the past 20 years, insight products have come a long way from crosstab reporting (late 90’s) and dashboards (2000’s), to immersive visualizations (2010’s). With the recent advancements in natural language processing and machine learning, there is a unique opportunity to make consumption of data, from exa-scale platforms for insights, both intuitive and timely.
A similar thought was shared by E.F. Codd, in his paper, ‘Seven Steps to Rendezvous with the Casual User’, as he wrote, “If we are to satisfy the needs of casual users of data bases, we must break through the barriers that presently prevent these users from freely employing their native languages (e.g., English) to specify what they want.”
We built an in-house product called Qurious which allows our internal business customers to ask questions in their natural language. They are then served the insights in real time without the need to create dashboards. The product includes a webapp and a Slack chatbot, both of which are integrated with BigQuery and Data QnA APIs.
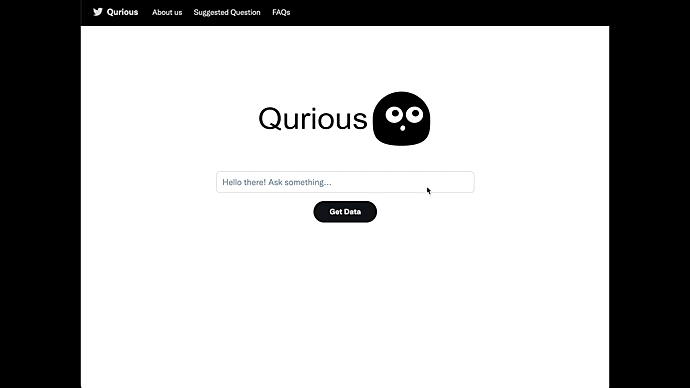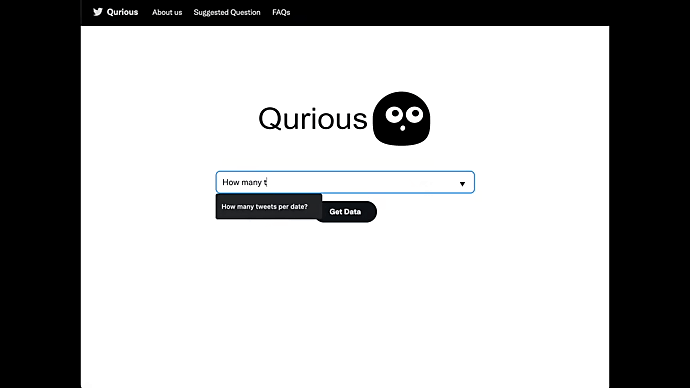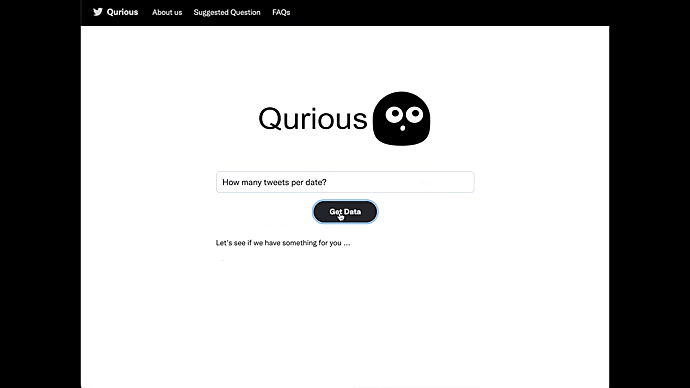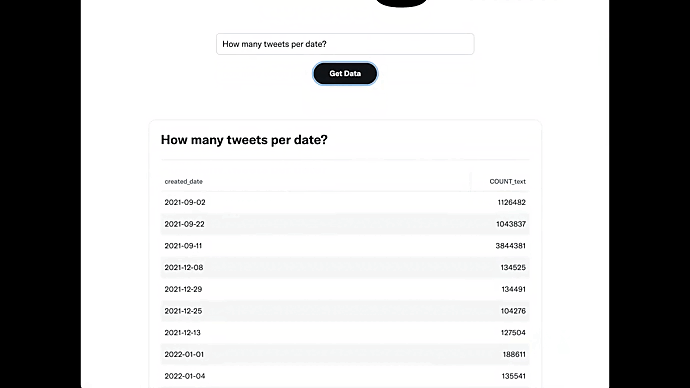
Below is the demo of the first version of Qurious that provides an autocomplete search box for our internal business customers to type a question. The user is able to click a ‘Get Data’ button to get the answer in a datatable.
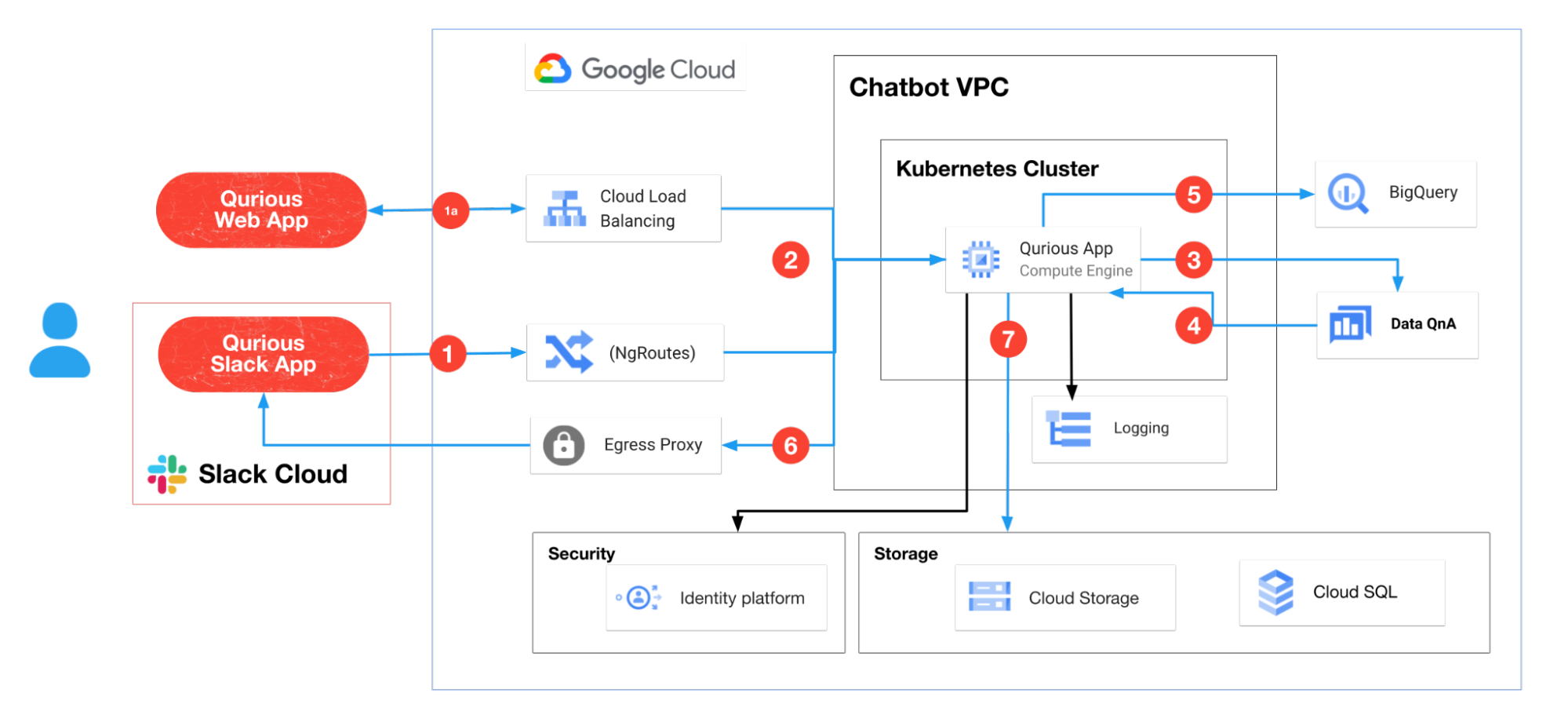
The process shown in the above image is described below:
The user enters a question in one of the following:
- The Slack chatbot
- The webapp
The question is routed to the Google Kubernetes Engine from Google Cloud Load Balancer or NgRoutes
The question request is forwarded to Data QnA
Data QnA returns the response containing the suggested SQL query translation of the user question
The SQL query translation is sent to BigQuery for execution
Egress Proxy routes the data from query execution to the Qurious Slack App. The cloud load balance returns the data from query execution to the Qurious webapp
The user’s question and the returned responses are stored in Google Cloud Storage/Cloud SQL. Additionally, logging and identity management is enabled
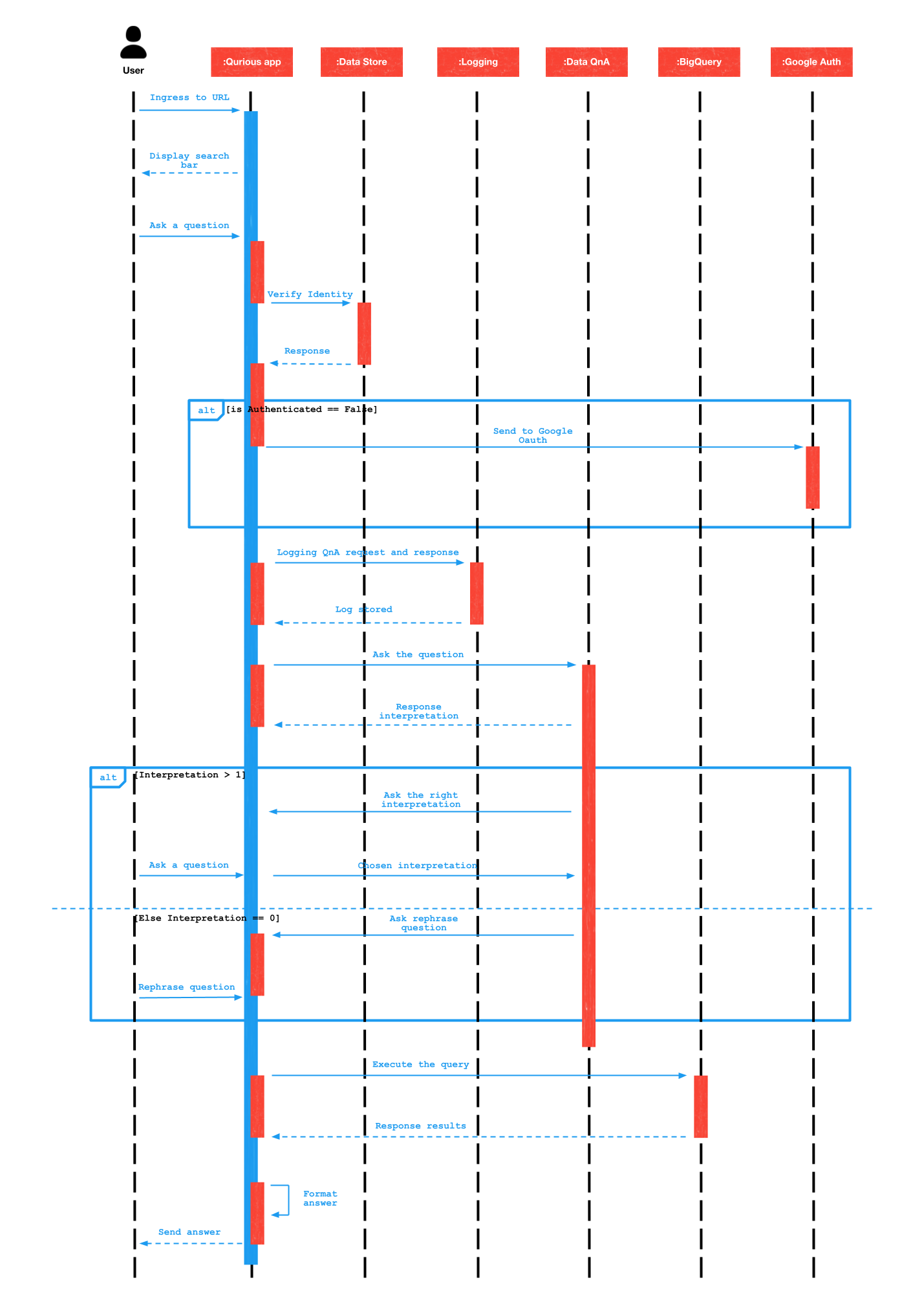
The following sequence diagram describes the interactions between the user and various components of the application. The user request flow includes:
We used Google Cloud Platform and internal Twitter services to build the application. We used the stack described below:
Google Kubernetes Engine (GKE)
GKE is Google Cloud’s fully managed Kubernetes service that implements the full Kubernetes API. It provides the mechanisms through which we interact with our cluster. Kubernetes commands are used to deploy and manage our applications, perform administration tasks, set policies, and monitor the health of our deployed workloads. It follows an automated process that allows us to scale the platform based on the workload. It also ensures that the information is found through secure communication channels by following all the processes, policies, and security standards of Twitter services.
Twitter Puppet
Puppet is the configuration management system used at Twitter. The service is provided by hosts under the puppetserver role. It allows us to set a new image based on Twitter templates with a default setup that we customized based on our use case.
Google Cloud load balancing
External HTTP(S) load balancing is a proxy-based Layer 7 load balancer that enables us to run and scale our services behind a single, external IP address. External HTTP(S) load balancing distributes HTTP and HTTPS traffic to backends hosted on a variety of Google Cloud Platforms (GCP) (such as Compute Engine, GKE, Cloud Storage), as well as external backends connected over the internet or via hybrid connectivity.
It is responsible for forwarding the requests to the servers available in GKE. If the load increases, a new server will be deployed and the load balancer will be in charge of directing the traffic to that new server. This is also due to the fact that we cannot create servers with public IP's. A connection point is required between the GCP services and the outside world through the internet.
SSL certificate
TLS certificates are used to secure connections to TLS servers. They are used to request certs from a publicly-trusted certificate authority (CA) appropriate for use with web servers. Since our application contains sensitive information, we want to ensure a secure connection using an SSL certificate.
Google Cloud APIs
Google Cloud SQL
Google Cloud SQL was used as the backend for storing information such as user interactions, app-level metadata and frequently asked questions.
Google Cloud logging infrastructure
We enabled logging for search queries to understand the questions being asked by the customers, along with tracking several user actions. Currently, we store these logs in a BigQuery table because the alpha version of Data QnA API has not yet released access to the logging functionality.
Frontend components
We employed several components from the Twitter Feather Components Library, including Navigation Bar, Buttons, Charts, Tables, Progress Spinners, using CSS style sheets and React.
Backend components
This includes services on GCP that send various Remote Procedure Calls (RPCs) including:
Both the webapp and Slack chatbot use common services to facilitate easy maintenance of the code. It also allows easy flow between the two surfaces, for example, for some questions we may provide the user with a URL to the webapp. Some of the common services are:
- Check if the token is in the datastore
- If the token exists, check if it is valid
- If the token is expired, ask for re-authentication
- Asks Data QnA the question
- Handles multiple interpretation handlers to the /interpret endpoint
- Asks the user what interpretation they want. If there are no interpretations, it means Data QnA did not understand the question
- Executes the question, formats the answer, and sends it to the user
Additionally, we created secession on both Slack and the web app to keep the user logged-in for a certain period of time based on the channel model:
Slack Chatbot
The Slack chatbot was built on top of a Google Data QnA reference implementation using node.js with Express Framework. We followed the Slack guidelines below to handle and maintain the integrity of the session:
This is the start of our journey and our work is far from done. Google Cloud Data QnA is currently in alpha stage, and, as the product evolves, we will continue to build more features in our product. This will truly democratize access to data for all our customers, regardless of their level of data literacy. We are excited about the future of a truly ‘No-SQL’ world.
We would like to thank the following contributors and reviewers:
Arnaud Weber, Luke Simon, Roman Dovgopol, Wini Tran, Vrishali Shah, Carlos Alejandro Aguilar Castañeda, Shevy Lindley, Eric Shen, Saurabh Shertukde, and the Google Cloud Data QnA Team
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.