Insights
A new approach: Metric learning for SplitNet
By
Monday, 8 June 2020
Connecting to the right audience.
With the right message.
At the right time.
That’s how Twitter helps advertisers grow their businesses.
Every second on Twitter, machine learning models are performing tens of millions of predictions to better understand user engagement and ad relevance. Ads ranking is foundational to creating this value between Twitter’s users and advertisers.
Although Twitter’s ads stack is designed to handle this large amount of ad requests in real time, rapid growth in the number of active users and advertisers on Twitter presents a massive learning challenge. Knowing that, how might the team scale its machine learning techniques while maintaining the reliability and performance of Twitter’s service for over 125 million monetizable daily active users around the world?
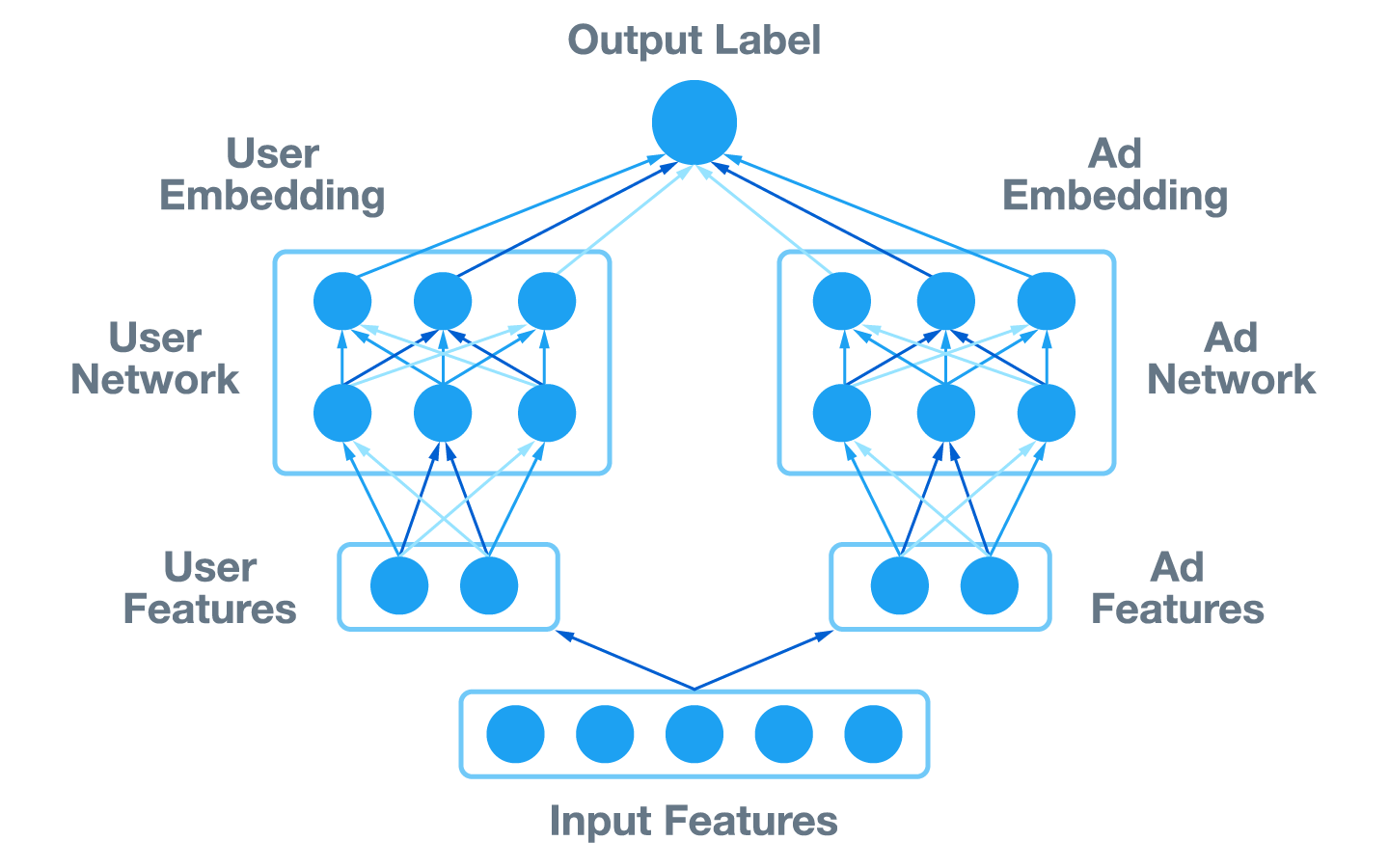
To tackle this challenge, our team designed a lightweight ranking stage in the ads pipeline, using a computationally efficient model that filters out less-relevant ad candidates before reaching the heavy ranking stage, where more intensive calculations are performed. We also recently deployed a SplitNet model in the light ranking stage, where information on user requests and ads are represented by fixed-length embeddings.
Exploring cutting-edge metric learning techniques helps us learn a similarity function instead of manually crafting a similarity function. Online A/B tests show that metric learning has contributed significant gains to our top line metrics, and we have fully launched this state-of-the-art technique to production.
Let’s step back and define mathematically what we mean by a similarity function. The similarity function measures how related two objects are, in our case, an advertisement and a user. The objects are usually represented as feature vectors, or in our case, learned embeddings. We can represent the similarity function as a matrix, S, that relates a user embedding, u=[u1, u2, ... , un], and an ad embedding, a=[a1, a2, ... , an]. Here is an example:
We would like the output of our function, p, to capture the likelihood that a user will click the ad, which we consider a good indicator of ad relevance.
The red matrix S is the learned similarity matrix . Each entry sij in this matrix relates the i-th dimension of the user embedding to the j-th dimension of the ad embedding via the formula uisijaj.
One way to devise a similarity matrix is to hand-craft one based on some assumptions about the problem at hand. For example, we might assume that only the pairs (ui, ai) contribute to the similarity, and their contributions are equal. In this case, our similarity function is the dot product, as represented by the special-case similarity matrix shown below in red:
This represents the similarity function chosen in the first iteration of our SplitNet model. We further learn a scalar parameter on the dot product of two embeddings, namely
Comparing Equation (1) to Equation (2), the similarity matrix in Equation (1) makes the model more expressive by adding more parameters. Note that the similarity matrix can be learned from data. To implement Equation (1), we modify the last layer of the SplitNet model to add more parameters to facilitate learning a similarity matrix. This technique is called metric learning. With metric learning, we are able to jointly learn user embedding, ad embedding, and the similarity matrix from the data.
It’s important to keep in mind that SplitNet is used in our online ads system with strict time constraints. Let us revisit the computational cost at the time of prediction with metric learning Equation (1). Assume the embedding dimension is n. The learned similarity function has n^2 parameters. At the time of prediction, we are doing n^2 multiplications for metric learning, compared to the nmultiplication for dot product. From past experience, we know such an increase in computational complexity is a significant overhead in the ads system.
In order to maintain system performance, we further simplify the similarity matrix in Equation (1) by assuming it is a diagonal matrix shown below
The similarity matrix in Equation (3) eliminates the interaction between ui and aj, when i is not equal to j. This compromise between model expressiveness and system efficiency still results in material improvement overall.
We use quality factor (q) as an indicator of system performance, where a low q means the system is under heavy load, and fewer ad candidates will be processed as a consequence. The figure below plots q during A/B testing, where the orange line is the control experiment and the blue line is the treatment experiment. As you can see, the system performance of metric learning is on par with that of a simple dot product.
We have found that metric learning is especially good at finding high-value ad candidates with intrinsically low monetizable probability. This is because SplitNet is trained on ad candidates across all Twitter campaign objectives. For example, a Video View ad usually has a view probability around 30%, while the conversion probability of an App Install ad is significantly lower. In this case, the single-parameter dot product method in Equation (2) is easily biased by the high correlation examples (Video View ads) and thus struggles to differentiate low correlation examples (App Install ads).
Results from the online A/B experiment show that the metric learning technique improves the conversion rate for App Install ads by 11%. This means that the SplitNet model with metric learning does a much better job at finding relevant app install ads to serve—a win-win for Twitter’s users and its advertisers.
We have fully launched this state-of-the-art technique to production, and plan to continue pushing the limit of the SplitNet model in light ranking. We’re working on improving the model’s quality by adding more features, while maintaining efficiency through distributed training. Regarding metric learning, we’re exploring the possibility to eliminate the diagonal assumption on the similarity matrix while maintaining system efficiency.
Revenue Science is the core Machine Learning team that drives Twitter’s revenue engine. We are committed to the advancement of ML technologies and architectures. If you’re interested in the intersection of machine learning and monetization, and want to work on the most immense technical challenges confronting Twitter and our industry today, consider joining the flock!
Metric learning for SplitNet is developed by Hongjian Wang, Jiyuan Qian, and Rui Zhang. We would like to thank Chris Chon, Corbin Betheldo, Deepak Dilipkumar, Michael Rael, Sandeep Sripada, Ye Liu, and the rest of Goldbird for their contributions to the project and this blog, and a special shoutout to leadership for supporting this project - Steven Yoo, Srinivas Vadrevu and Luke Simon.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.