Infrastructure
Twitter’s Blobstore Hardware Lifecycle Monitoring and Reporting Service
By
and
Thursday, 23 February 2023
Blobstore is Twitter’s low-cost, high performance, easy to use, scalable storage system built. It stores photos, videos, and other binary large objects - also known as blobs.
A majority of Twitter’s Blobstore is hosted in Twitter’s on-premise data centers on bare metal servers. When we first started Blobstore, these hardware servers moved in and out of Blobstore clusters during their lifecycle with no clear visibility and, as a consequence, with very little oversight from operators. Trying to understand the state of Blobstore infrastructure used to take several manual queries. These queries were run ad-hoc and not on a regular basis. So, machines would sit indefinitely, with no alerting, in a given state. Moreover, our physical storage capacity had no alerting, with most indications of impending capacity crunches being signaled by other alerts or manual intervention.
With the scale of blob data at Twitter, managing Blobstore hardware became harder and it became apparent to us that we need to build a better hardware lifecycle management service for Blobstore. The goals included:
High level overview of Blobstore’s hardware lifecycle:
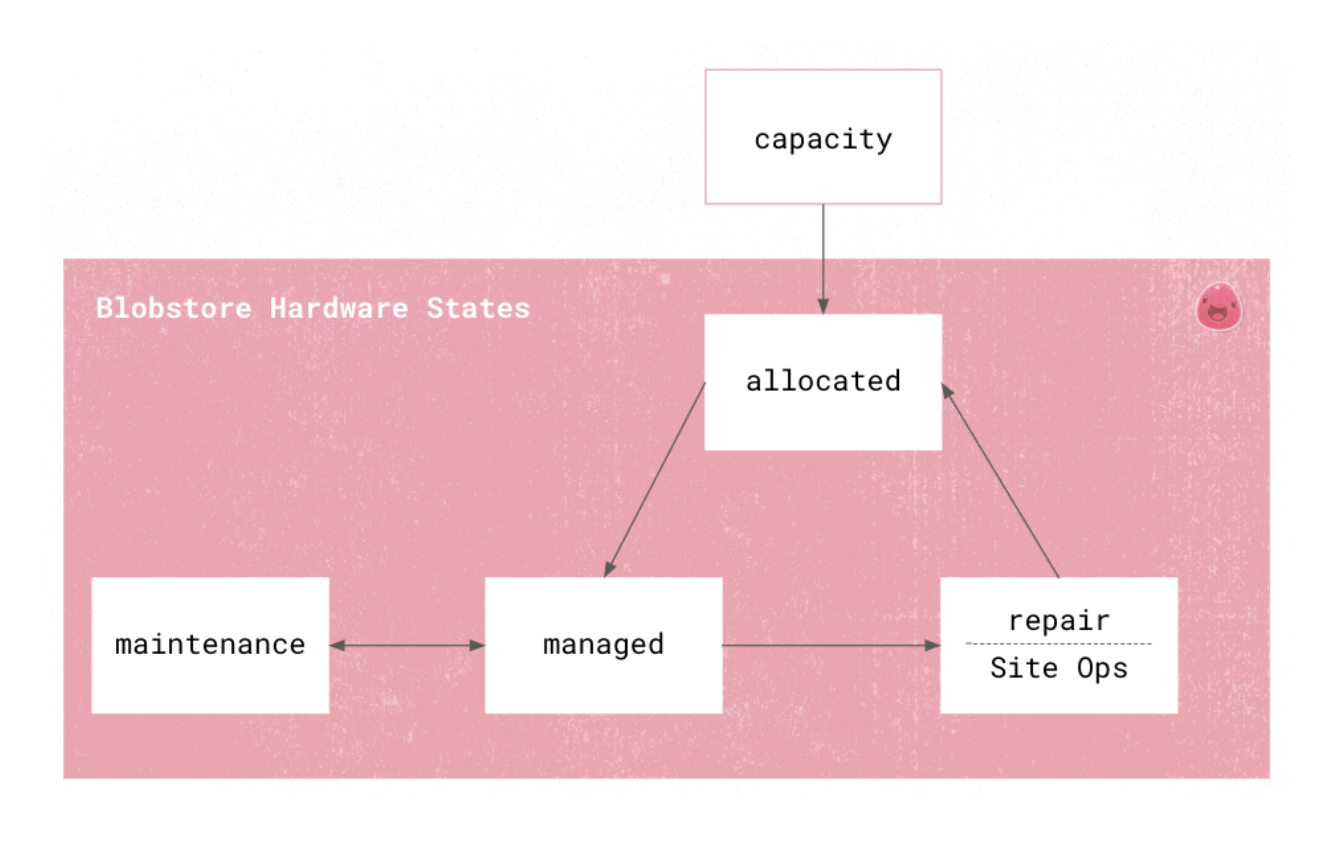
Blobstore Hardware States
Blobstore utilizes four fundamental lifecycle states to indicate hardware status:
Hosts typically start in allocated; in this state, hosts have either been recently allocated from the Capacity Management team or are coming back from repair after being freshly re-imaged. Machines move from allocated state to the managed state once the host state is consistent with expected ‘in-production’ configuration and formats. Once in the managed state, a machine is moved to maintenance if it needs a Kernel update, firmware update, or if the machine begins to experience critical errors including bad hardware health, for example a bad disk with an I/O error. In the latter case, the host will then be sent to the repair state, which is owned by Twitter’s Site operations team. If the repairs are successful, the host will send a freshly wiped host into the allocated state - completing the wilson lifecycle.
Below are individual diagrams and descriptions of the processes that transition our hardware between each state.
Provisioning
Provisioner service runs every 24 hours on each host, at a randomly scheduled time, and attempts to transition Blobstore hardware from the allocated to managed state, performing disk provisioning if necessary. First a machine goes through a series of validation checks to ensure that the host has been properly constructed after being reimaged or allocated to the role. If the host has been successfully validated, the data disks are formatted (getting new uuid, adding fat files, setting top-level files/directories) and then Puppet is run (to ensure all software is laid out on the machine as needed). If that’s all successful, the state is set to managed and the host is added into the data center.
Twitter uses Airflow and Airflow-Compliance as a scheduler and an operation component, which scan for and operate on hosts running outdated firmware or kernel. For checking/ensuring firmware compliance operation, a healthy host’s monitoring alerts are silenced and the host is moved into the maintenance state. Once in maintenance, the firmware is upgraded. Upon completion, the machine is moved back to the managed state, unsilenced, and released. Blobstore is notified about the operation being performed via Slack (which is a tool we use for system/employee to employee communications) if there are any failures during the Airflow operation. If a host fails a firmware update it will still always release its lease to prevent erroneous alerts, and the failure will be handled by other automation or manual inspection.
Adding operation and lifecycle metrics to Blobstore’s current agents was the easiest and most achievable goal to quickly assist engineers in managing bare metal. A new team precedent was set, so each future Blobstore tool would emit metrics where Blobstore engineers deem most effective.
From a high level, we’re interested in the number of hosts being provisioned, hosts in an allocated state, number of hosts sent to or already in repair, number of hosts moved to managed, and a list of hosts that are rebooted.
Twitter’s metrics library does not collect stats from cron jobs that last less than two minutes, reliably. To work around this constraint, a short-lived Python service runs on the machine which uses CuckooScribePublisher to send data to a local Scribe daemon. Data is sent to a local Scribe daemon that then routes the data over the network to Cuckoo. Cuckoo receives the data from a scribe server which is then collected and displayed in dashboards.
To transition the broken hosts from managed state to repair state, Blobstore utilizes automation. A list of failed, and now unused, nodes are collected using Blobstore’s mapping service. Hosts that are either in maintenance or are already assigned a repair ticket are removed from the collection. Machines in maintenance may be down for a reason and should not be rebooted. If a host contains too many bad statuses in its history (a heuristic like more than 6 in a month || more than 3 in a week || more than 2 in a day) the host is removed from use, silenced, sent to the repair state, a site-operations ticket is created, and the host history is cleared. Otherwise, the host is rebooted and its history is pruned by 1 month because that part of it is fixed.
In addition, the tool finds the number of dead disks in the fleet, takes hosts out of production, and controls the rate in which hosts are sent to site operations. As a previously manual process, automating the steps to shuttle hosts to repair were key in reducing engineer toil, increasing visibility into disk repair, and mitigating the lack of hot swapping disks.
The automation’s logic, at a high level, is :
This has helped the Blobstore site reliability engineers, Blobstore software engineers, capacity engineers and the hardware design, development and validation teams by improving the reliability of the hardware and thereby, the Blobstore service and also providing insights into capacity management, thereby increasing the accuracy of capacity planning.
Blobstore wouldn’t be what it is today without amazing engineers. Those include Alex Angelo, Anie Jacob, Ashwin Poojary, Bogdan Spaiuc, CJ Buresch, Charlie Carson, David Rifkind, Hakkan Akkan, Hamid Tahsildoost, Kevin Merrick, Morgan Horst, Nic Giusti, Octav Mitrofan, Salih Karagoz, Santtu Voutilainen, Seda Unal Calargun, Yuke Liang, and many engineers from several teams who have aided in the design, development, and deployment of Blobstore at Twitter. Thank you for making Blobstore awesome!
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.