Infrastructure
Accelerating ad product development at Twitter
By
and
Monday, 3 August 2020
Conway’s law states that “organizations design systems that mirror their own communication structure.” Twitter Ads is no exception to this rule. The Ads team grew from ~15 engineers in 2010 and $28M in revenue to hundreds of engineers and ~$3.4B revenue in 2019, increasing the functionality and complexity of Twitter Ads systems, while not dramatically changing the model of operation of teams or services.
The early software model was well suited to the structure of a startup - trying to move fast, without any baggage from previous design decisions. The Ads Backend team was broadly split into three teams: Platform, Science, and Product, to achieve the ultimate goal: build and iterate quickly on Ad products that would help make Twitter profitable.
Twitter’s ad platform consists of infrastructure and core components including Ad Serving, Billing, Data Infrastructure, Analytics and peripheral support systems. One of the main focuses of the Platform team was to ensure reliability, deployment, oncall and performance of a monolithic AdServer - the heart of Twitter’s ads platform. The focus of the Product team was to make all the changes required by Twitter’s Front-end Product team to AdServer, which would serve their ad product to consumers. By its very nature, the Platform team was a gatekeeper with a global view of changes, and total control over services. The Product team was more fragmented, yet nimble to make code changes over distributed touch points, relying on the Platform team for shepherding.
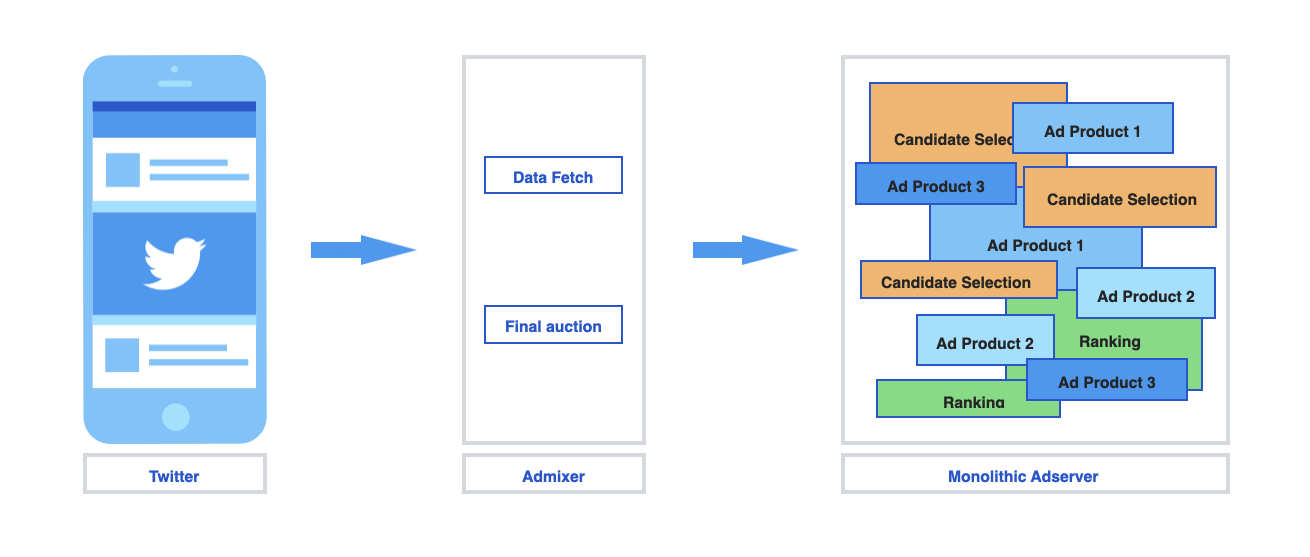
The teams built a small cohesive single monolithic service (AdServer) that would get an ad request from the Twitter services, fetch eligible ads based on advertiser targeting configuration, rank them, run a second price auction and send the “best” Ads for the user as the response.
Using this paradigm, Twitter built several successful ad products with varying objectives and increasing complexity. We started ads with brand campaigns using Promoted Tweets to reach a vast audience and spread awareness about their product. We then launched a sponsorship based ad product called Promoted Trend to take over the explore tab and serve to all users on Twitter for a day. It later launched Mobile App Promotion (MAP), which helped advertisers connect with highly interested users, and Website Clicks to help drive people to visit and take action on a website. Promoted Video is another ad product which makes it easier for brands to use this storytelling medium, as well as measure the reach and effectiveness of its content.
This model worked really well with a small set of engineers -- with teams that were iterating fast -- but as the business and the teams started to grow, the Platform team, which was the force multiplier for the nimble Product team, started to become a bottleneck. To help illustrate this better, the following section outlines the flow of an ad request.
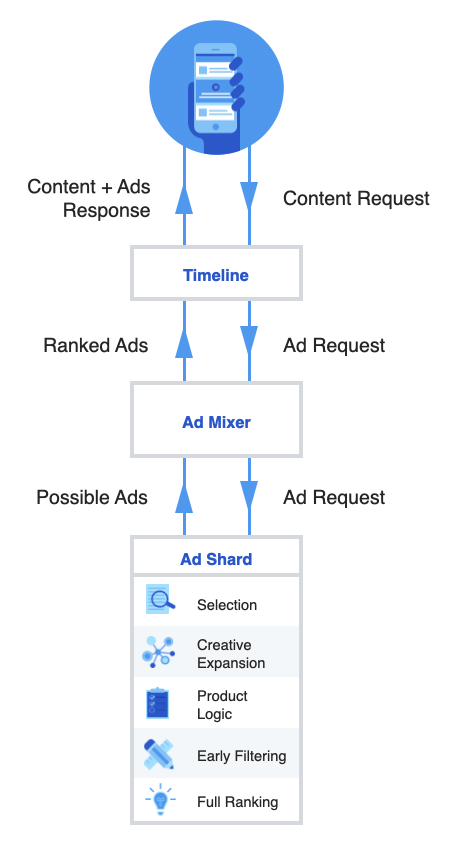
In order to serve the most relevant ads, we use the following two components in the ad request path:
AdMixer, the service that is the gateway for the ad serving pipeline, when given a request:
Monolithic AdServer, which is responsible for considering every eligible ad, for every request and returning the “best” ad candidates to AdMixer. Due to the scale of Twitter Ads, the service is partitioned or sharded such that each shard considers only a subset of the possible ad candidates. This sharding scheme also enables parallel computation, which helps meet the strict latency requirements for an ad request (200-500 ms based on type of request).
For its subset of ads, each shard of the monolithic AdServer, computes a set of “Processors” responsible for:
In 2010, each processor was a single incremental change, but by 2018, each of these stages had become distinct. When we start with a simple system and begin to add pieces, one by one, small decisions have long term consequences. Having hundreds of changes per deploy became unmanageable for every team involved specifically because the owners of the services (the Platform team) weren’t the main contributors of changes (the Product team) to the service.
Moreover, as these stages were not strictly defined, there was nothing that stopped “Product Logic” processors from being added to “Candidate Selection” or “Candidate Ranking” pipelines. For an engineer in the Product team, this resulted in additional complexity since they would be dealing with a black box (the monolithic AdServer) where they only understood a few pieces. Each distributed piece had to work with the others to make the final product function. Testing the changes was also difficult due to this lack of visibility. It sometimes took as much as a month to get a simple change from development into production.
In 2018, a general lifecycle of product change (Eg. Video Ads), with the above Platform + Product team structure would include the following steps by the Video Ads Product team and challenges they would encounter:
This is a step where an engineer attempts to find out what the existing state of the world is and how to make sense of the intertwined platform and product components. The complexity grew exponentially over time due to combinatorial explosion of intersecting product and platform features.
One of the challenges for an engineer in the Product team was finding their footing in a large codebase (with hundreds of thousands of lines of code) that they don’t own. Even after making the code changes, it wasn’t obvious which ad requests would finally hit the new code path without a clear API between business logic and infrastructure components.
In this step, a Product engineer would identify the changes needed to the system to ensure their requirements were met. Challenges here included not fully understanding the impact of the Video Product changes on other products running in the same monolithic AdServer. Performance implications of their changes would also be hard to estimate.
Once the design was ready, the next step would be to engage with the Platform team. Since they own the service and are responsible for its reliability, performance, and oncall support, they are on the hook for any changes that might affect the system. The process here included shepherding and code reviews. Even with distributed ownership rights, the two team’s incentives did not align. This led to many design shepherding requests being hotly debated or denied, resulting in disappointment and frustration in both teams.
Once the code was reviewed and merged, the Product team once again relied on the Platform team for deployments. The testing of a successful feature was much more difficult, sometimes including as many as ~200 changes per deploy. Also, because logic for multiple products ran in the same monolithic AdServer, one product’s change had the ability to block the entire deploy, affecting other Product teams due to the increasing coupling. Final testing could not be done until after shipping so the turnaround time for fixing surprise bugs was also unpredictable due to the various teams involved.
Our solution for the problems was multifold. We began by separating out horizontal infrastructure components that serve different ad products (more information in our previous blog post). Following that, the key idea for increasing the Product team’s iteration speed was the introduction of “Product Bidders”. This included decomposing the monolithic AdServer by Product Verticals while still having a common framework across all decomposed services, to maintain the multiplier effect.
During such a decomposition, it is relatively easy to seperate all services to ensure the Product team’s iteration speed is increased, but as a consequence, changes across the decomposed services would be much harder. Hence we decided to maintain a balance and to take a two pronged approach:
Sets of processors were logically grouped into an Enricher or Filter stage of a “pipeline”. The structure of these pipelines and the execution mechanics belonged to the common Bidder Framework and each Product Bidder could customize the code that runs in these stages by choosing to add or remove processors using a plug and play model.
This achieves decomposition of service and ownership in a controlled manner, such that the Platform team continues to own the Bidder Framework, maintaining the same standards across all bidders. The benefit is maximum agility and speed, while retaining multiplier effects like framework upgrades happening at once for all services, and common analytics data for every Product Bidder.
Having independent Product Bidders also allows for independent resource allocation among different products based on their needs. For example, the Video Product Bidder could choose to scale or allocate its latency budget independently and at a different time frame as compared to other products if a new video feature requires additional compute resources.
The other major benefit of the product decomposition was the isolation of each product vertical. In this microservice architecture, engineers are empowered to make changes to specific products like Video without the risk of affecting a completely orthogonal product.
In the beginning, the monolithic AdServer was one cohesive service, so changes were made such that any processor could be run anywhere without enforcing specific standards. Hence there was no clear way to identify dependencies and shared components of a processor. To help resolve this, Twitter Ads developed its own Data Dependency Framework, and updated the monolithic AdServer to use this framework. This made dependencies explicit and removed the mutation of common data structures from the processors, making each of them totally independent, given their predefined inputs. This explicit contract helped us form meaningful logical APIs and boundaries for any new libraries.
In the previous system, we had one layer (AdMixer) that fetched data (Like user data, interest, activity, etc.) once per request and federated it to the monolithic AdServer shards. However, for feature development to be independent between decomposed services, we had to decouple the data fetches as well. To avoid each decomposed service making its own data fetch (potentially increasing fetches by 400x per request), we used two approaches:
Before we decomposed it, the monolithic AdServer was still largely responsible for Twitter’s $3B business. While doing the decomposition we had to keep the existing business running, as well as support ongoing product development.
During the project, we performed extensive A/B experimentation, where we enabled the decomposed system in production for a small percentage of traffic and conducted robust impact analysis on product metrics. This ensured thorough vetting of the fundamental changes to maintain revenue and product metric parity as well as minimize any surprises when we launched to production.
We also staggered the rollout over 4 weeks, enabling an increased percentage of traffic each week, so that we were able to monitor and catch issues early without affecting all of production. We additionally deployed ~20% more capacity per Ads Product Bidder and enabled a mechanism to rollback within 30 seconds. Lastly, we ran the monolithic AdServer (previous architecture) on a small percentage of traffic for one quarter so we could have a holdback to evaluate the long term impact based on seasonality.
The decomposition entailed a tremendous amount of code complexity. We had to question parts of the code base not touched in years. In order to gain meaningful logical boundaries and separation of concerns, we tried to categorize each of the processors into platform components core to “Candidate Selection”, “Candidate Ranking”, etc. but also into smaller functional groups of shared logic like “spend calculation”, “frequency cap enforcement”, etc. However, due to slow tech debt creep, this wasn’t easy.
Most of the projects involving the monolithic AdServer have been incremental changes, which have helped to refine and perfect it over the past 8 years. But these kinds of changes don’t expose large bugs. This decomposition was a fundamental change to how we serve and pick the “best” ads for users at Twitter. This helped surface latent bugs in our software stack. We used the quarter-long holdback to identify, diagnose and fix these issues for an overall healthier system.
As part of any large initiative, several trade-offs have to be considered and hard decisions made to ensure perfection doesn’t hinder progress. The final solution isn’t a silver bullet but collectively our team acknowledged the risks as well as the benefits to make this choice. Some of those trade-offs were:
Lack of a global view in Ranking Ad Candidates
When we decomposed the monolithic AdServer into Vertical Product Bidders, we also lost the ability to rank all the product ad candidates in a pseudo-global manner within a single AdServer. The previous monolithic system allowed us to easily shift the balance of the portfolio of ads-considered based on the ad request. Our vertical product split makes it harder to dynamically adjust that product mix per request as the ranking is done within the confines of a single bidder. This was an explicit choice we made and we compensated for it by increasing the number of ad candidates we consider for the final auction to ensure we don’t drop ad candidates that would have otherwise been eligible.
Increased capacity cost for downstream services
Due to the scale of the monolithic AdServer, we were under a lot of pressure to get capacity planning right as soon as we started the project, as we needed to give the infrastructure team a 6 month heads up on our requests. We used prototyping techniques as well as extensive load testing to ensure accurate estimates.
Going from a monolithic AdServer to a Product Bidder architecture meant with each new Bidder, we would increase the number of requests to the downstream services. This has a ripple effect on the capacity needed to add a new Bidder, across all downstream services, and adds to overall costs. Keeping this trade-off in mind, we carefully chose the product verticals to split such that we would get maximum return of investment.
While it is beneficial to be able to make platform-level changes only once for all Product Bidders, it introduces more operational toil in the testing and rolling out of those changes to production, as they have to be done per Product Bidder. This was a trade-off we were willing to make as bidder framework changes are a one-time cost.
Despite the trade-offs outlined above, after launching the bidders, we are seeing some of the benefits of product isolation. A concrete example was a latency reduction in our Promoted Trend product suite, which was acheived by adding specialized caches for selection service responses only in an isolated bidder. We also saw that most planned product features were not blocked by the Platform team, alleviating one of our major pain points.
All laws have limitations and Conway’s law is no exception. It applies to all organizations, but we can also make a concerted effort to break it and to ensure that both services and organizations suit the needs of the future and aren’t beholden to the past. Decompositions are not the solution for every problem, but they do have positive effects on teams as well as services. The result: a simplified workflow for a Product engineer adding features in the new architecture. When we started this project, it seemed like a near-impossible task, but looking back, it has not only helped build healthier systems, but also helped spread the understanding of how they work, setting up Twitter Ads for its next ambitious goal.
If you're interested in solving such challenges, consider joining the flock.
Such a large scale effort would not have been possible without the cooperation of multiple teams. We’d like to thank those who contributed to this blog: Corbin Betheldo, Dharini Chandrasekaran, James Gao, Karthick Jaganathan, Kavita Kanetkar, Pawan Valluri, Raunak Srivastava, Rembert Browne, Sandeep Sripada, Troy Howard and Tanooj Parekh.
We would also like to thank those who worked on this project: Andy Wilcox, Ankita Dey, Annie Lin, Arun Viswanathan, Bhavdeep Sethi, Brian Kahrs, Catia Goncalves, Chinu Kanitkar, Dan Kang, Eric Chen, Eugene Zax, Grace Huang, J Lewis, James Neufeld, Jean-Pascal Billaud, Jinglu Yan, Joe Xie, Julien Delange, Marcin Kadluczka, Mark Kent, Mehul Vinod Jain, Michal Bryc, Mohammad Shakil Saiyad, Nick Pisarro, Nikita Kouevda, Nina Chen, Parichay Johri, Paul Burstein, Prabhanjan Belagodu, Rachna Chettri, Rui Zhang, Sheng Chang, Smita Wadhwa, Srinivas Vadrevu, Su Chang, Sudhir Koneru, Vinod Loganathan, Yixuan Zhai and Yong Wang.
We would also like to thank the Revenue SRE team, Core Reliability Tooling team, Revenue Product and Engineering leadership team and Revenue QE team for their constant support.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.