Infrastructure
Streaming logging pipeline of Home timeline prediction system
By
Monday, 22 June 2020
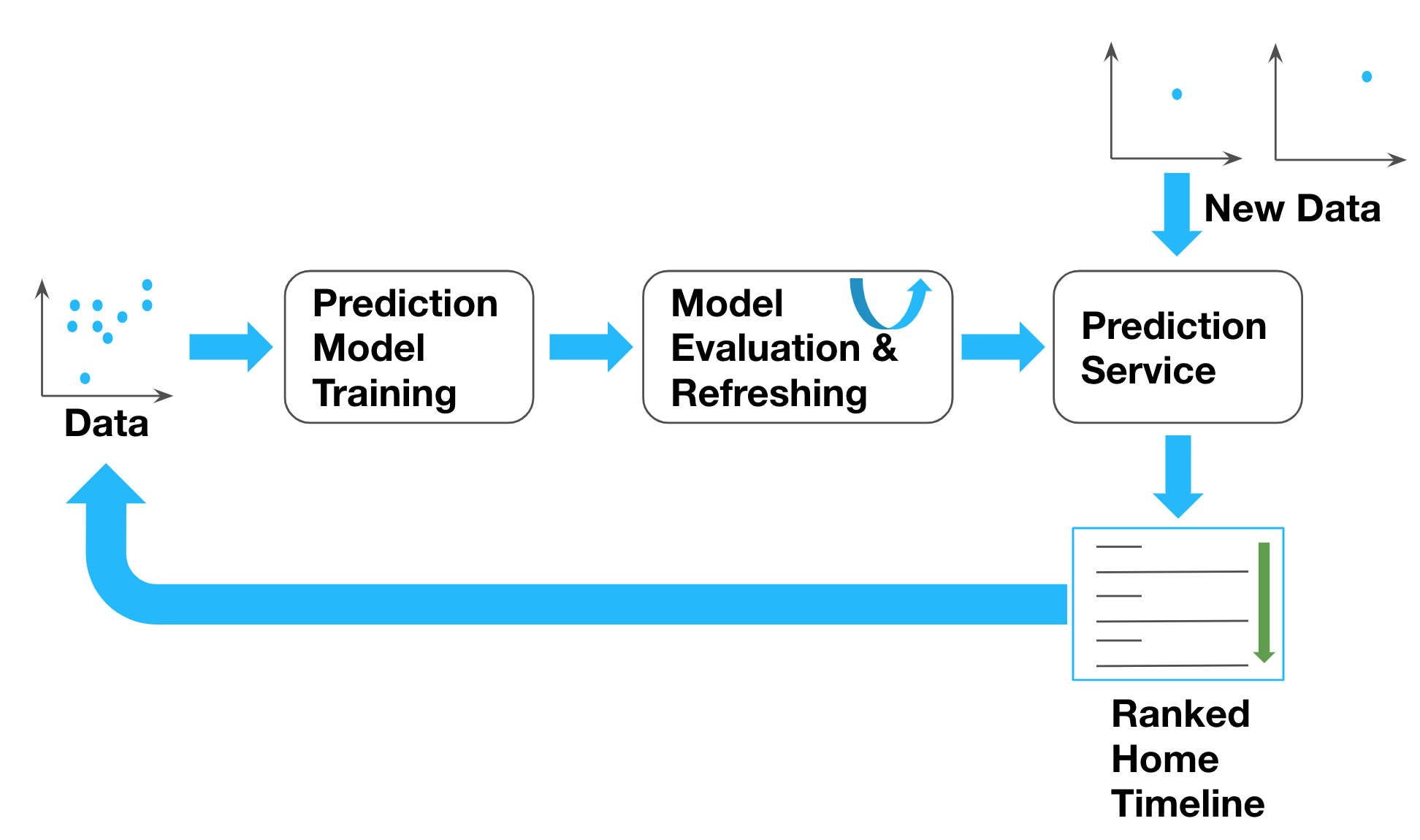
In the default configuration, a Twitter user's home timeline will show the top Tweets first. Top Tweets are ones you are likely to care about most, and we choose them based on accounts you interact with most, Tweets you engage with, and much more. The system that picks the top Tweets uses a dynamic algorithm known as a machine learning model to predict what Tweets you will be most interested in. The model learns how to make these predictions in a process called training, where it analyzes large amounts of data, and forms an understanding of user interests, based on their previous behaviour.
However, since user interest is constantly changing, this model must be updated regularly in a process called refreshing the model. In a recent effort, we have successfully reduced the time to refresh this model from 7 days to about 1 day via a redesign of our data logging pipeline.
This makes the model more responsive and adaptive to changes in your interests, providing top Tweets that change as quickly your interests do. Additionally, this change has helped the internal systems that back the Home Timeline ranking to be more agile, robust, and resilient.
It will be helpful to have some background information about how this prediction system works. The lifecycle of the prediction system consists of the following stages (as shown in Figure 1):
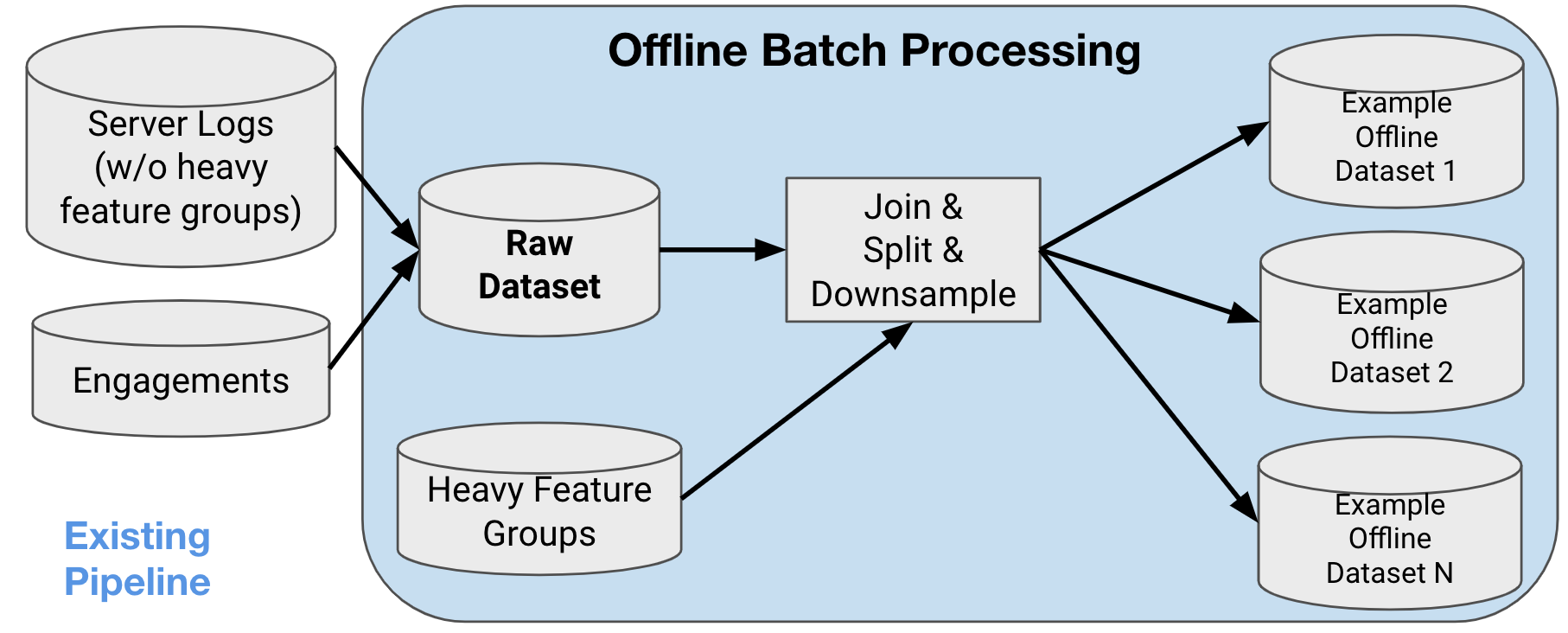
The Home Timeline’s existing prediction system, or more specifically the data collecting and preparation logging pipeline, does its work with batch offline processing. As shown in Figure 2, Server logs (the features) and users engagements (the labels) are first logged to offline storage as the "Raw Dataset". The features and labels are joined to become examples and are then downsampled. Finally, the examples are further split into multiple example datasets based on the engagement types (Favorites and Replies for example) and these datasets are ready to be fed to the model trainers.
Currently, the entire prediction system suffers from two main problems, latency and data quality.
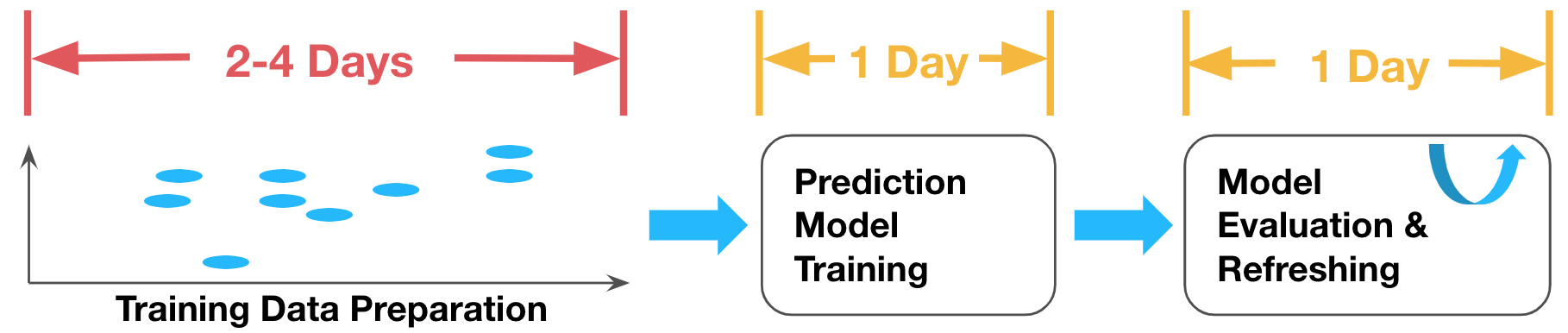
From the Time/Latency dimension, it takes 4-6 days from the time the data was logged until the newly trained model is refreshed in the prediction system (shown in Figure 3 below). The slow turnaround time to refresh the model is hurting the user experience.
This latency is rooted in several components:
Why does a stale model hurt though? This might be intuitive: Twitter is well known for its ever-changing environment -- user behaviors evolve quickly; trends are dynamic and inconstant; special and emergent events occur unexpectedly at any time. A stale model that is trained from old data, even a couple of days old, can be irrelevant. The freshness of the model is especially vital to a responsive, adaptive and successful prediction system that eventually leads to user satisfaction.
Table 1 also provides some practical evidence: Each column in Table 1 indicates the model performance on day T if we were to use the model that was trained on T-1 (i.e., one day ago), T-2 (i.e., two days ago), T-3 and T-4 for the prediction respectively. We can see that if we could update the model in a more timely fashion, we will be able to make a considerable gain of prediction model performance.
T-4 |
T-3 |
T-2 |
T-1 |
|
RCE (Relative Cross Entropy) |
38.81 |
38.82 |
38.84 |
39.12 |
From the Data Quality dimension, there are two sub-issues, data collection and join windows.
There are discrepancies between the data logged and the data actually used for prediction. Only partial data is directly logged by the existing pipeline since the complete raw data is too huge. Some large feature groups are reproduced offline and are joined with the directly logged features. As a unfortunate result, there is a lot of room for errors during the join which are extremely difficult to debug (this is what Google’s paper called “pipeline jungles”).
The main logic during training data collection is joining the Tweet features with their engagement labels. Ideally, for each served Tweet the data collecting system waits for user engagements for some time and decides whether a Tweet is a positive example or a negative example. The waiting time is called the join window.
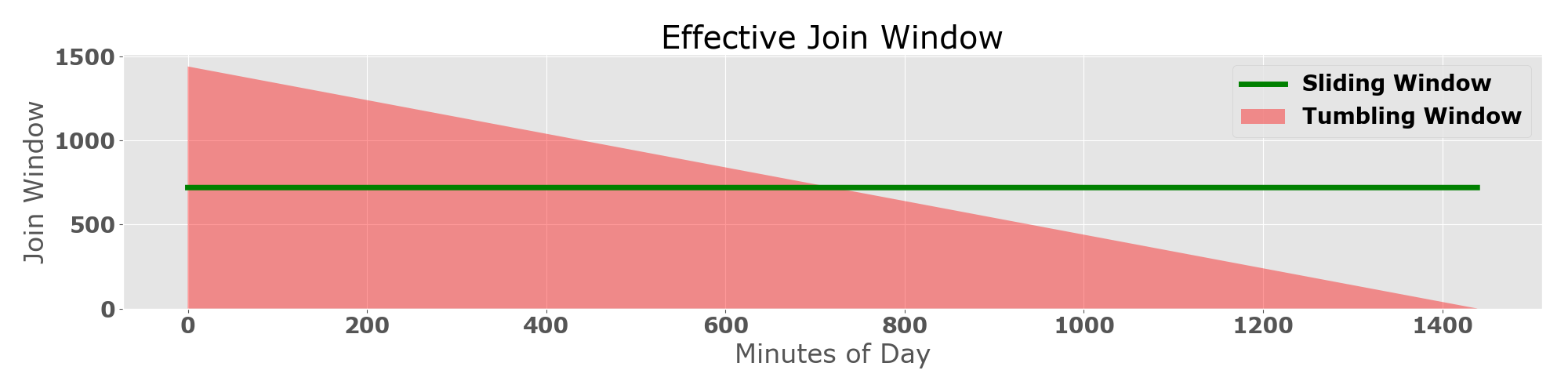
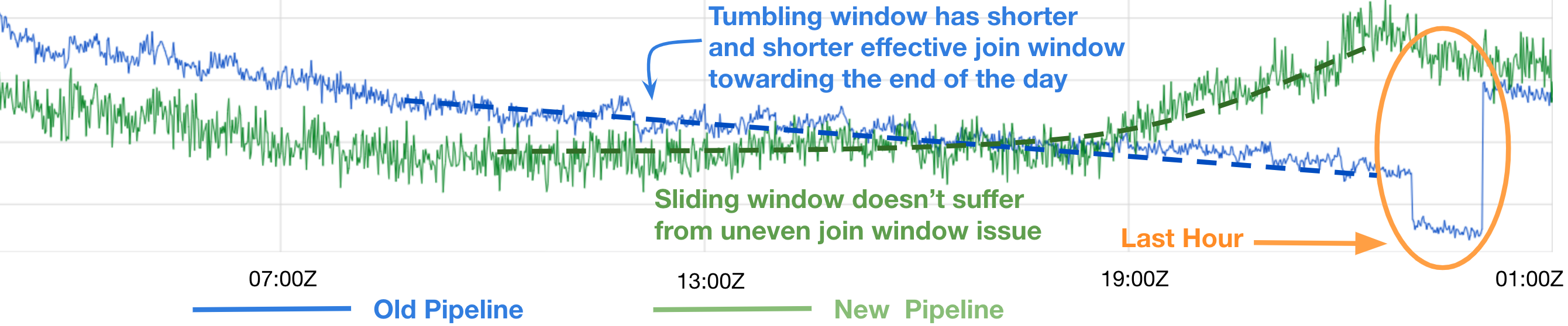
There are typically two types of join windows, namely Tumbling Windows and Sliding Windows (see Figure 4). A tumbling window aligns to the epoch and it introduces an uneven join window phenomenon: the first half of the data has a longer joining window than the second half of the data (see Figure 5 for an illustration). Our existing system uses a tumbling window but what we really need is a sliding window that is created for each record.
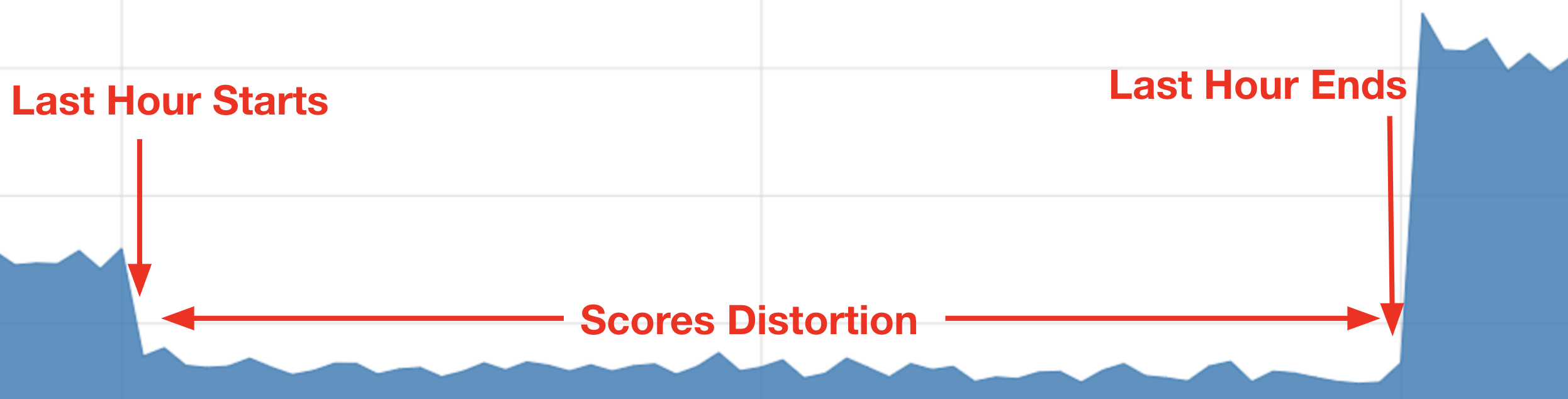
The extreme case occurs during the last hour in a day, where the served data has only minutes to match the potential labels and usually fails to do so. We also have a “UTC hour” feature, which together with the lesser amount of labels during the last hour, lead to a steep drop of the ranking scores (see Figure 6 below.)
To solve the problems mentioned above, we recently built and shipped a new streaming logging pipeline for the home timeline prediction system.
At a high level, our solution is to adopt the so-called Kappa streaming architecture, to move from offline batch processing to a streaming-first logging pipeline. That is, all the training data is collected and prepared in realtime without any delay. We chose Apache Kafka and the KafkaStreams processing library as our stream processing engine to build the core part of the pipeline. Kafka and its eco-system is not new to Twitter: This blog post discusses the move toward Apache Kafka from in-house EventBus (which builds on top of Apache DistributedLog); Twitter also integrates KafkaStreams into Finatra -- its core web server stack.
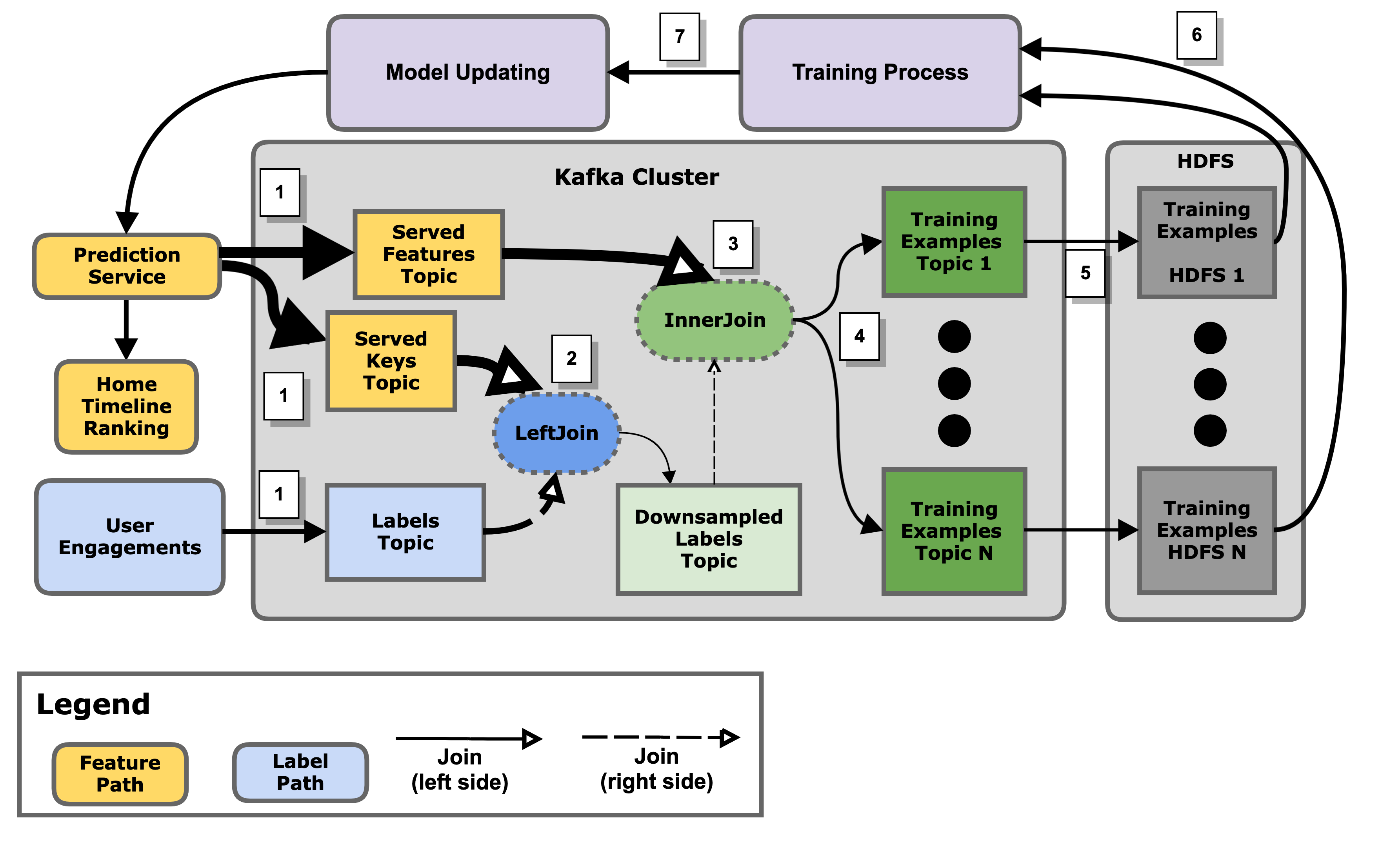
A simplified architecture of the proposed logging pipeline is shown in Figure 7. There are multiple sequential steps of the pipeline, as described below:
Although at a high level the system is not too complicated, we encountered several engineering challenges during the implementation. For example, the default join function in KafkaStreams does not serve our exact needs, so we invested in building our own join library. Also, the amount of the traffic we are handling on the Twitter Home Timeline causes both the KafkaStreams-backed joining and the Kafka cluster producing/consuming to struggle.
We will discuss how we tackle these issues in the following sections.
At its core, the processing logic of the logging pipeline is to join served Tweet features with engagement labels. KafkaStreams comes with a default join functionality where:
For our use case, we will keep using the local RocksDb state store and the sliding joining window. However, we have some special requirements:
Timestamps |
Left |
Right |
InnerJoin |
LeftJoin |
|---|---|---|---|---|
1 |
null |
|||
2 |
null |
|||
3 |
A |
|
||
4 |
a |
(A, a) |
||
5 |
B |
(B, a) |
||
6 |
b |
[(A, b), (B, b)] |
||
7 |
A |
[(A, a), (A, b)] |
||
Window Expire |
[(A, [a, b]), (B, [a, b]), (A, [a, b])] |
Twitter’s Home Timeline evaluates candidate Tweets from billions of Tweets to select, organize and deliver the best timeline to users on a daily basis. An interesting challenge of building the new streaming logging pipeline is to gracefully handle the monstrous traffic.
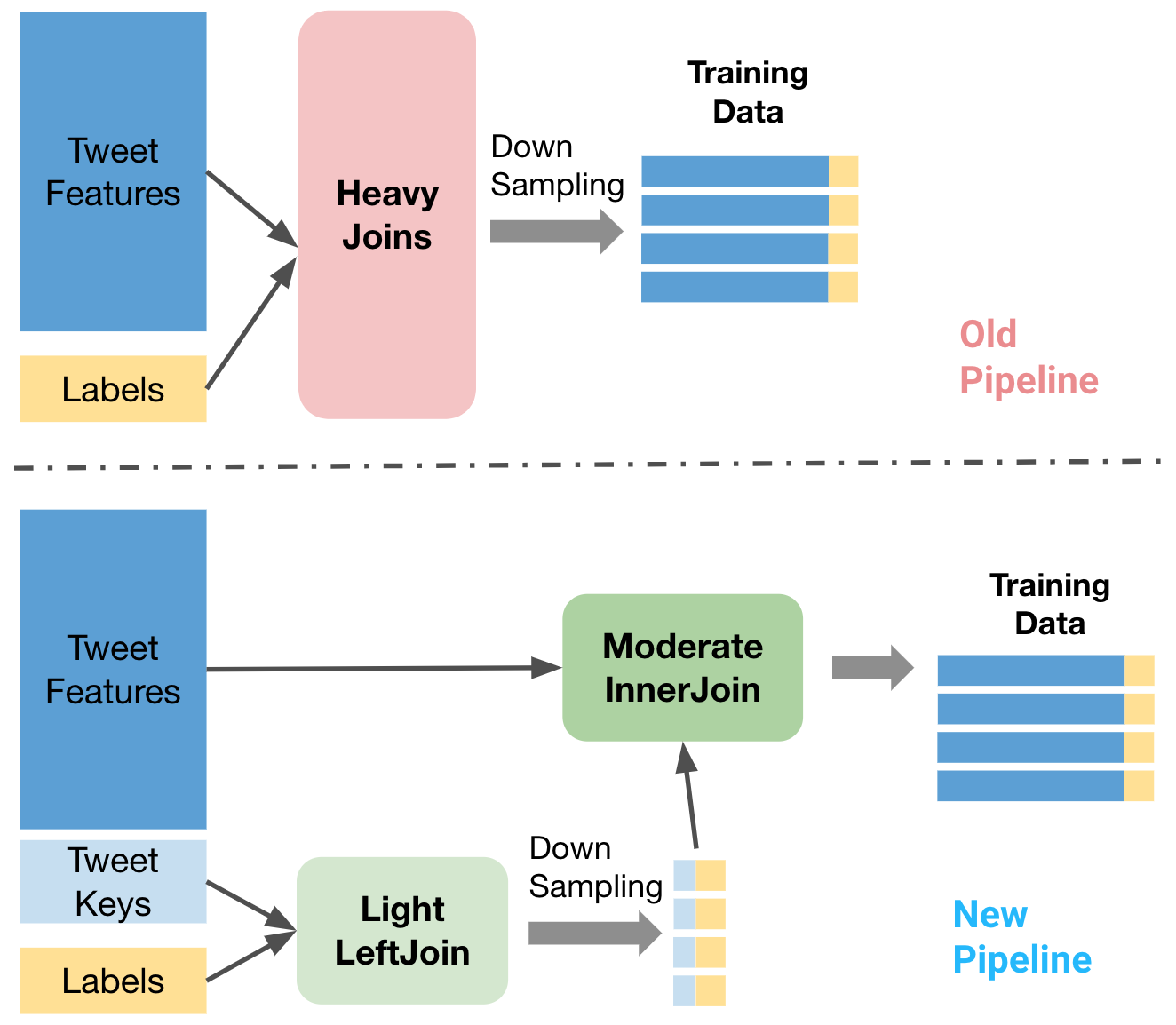
One critical strategy is to split the streams and do the downsampling that we have briefly mentioned In Figure 6. Here we want to emphasize the advantage of aggressively downsampling in the early stage of the pipeline: We could significantly reduce the burden for later InnerJoins that deal with heavy record payloads (all features). In contrast, directly joining all Tweet features with all labels would often cause problems since the memory footprint of such heavy joins is too huge. We found the split joins make the topology significantly more scalable and resilient (see Figure 8).
Splitting the streams is not the only knob we tuned. Over the course of the development, we gradually figured out the best configuration for the Kafka cluster as well as the Kafka services to make sure everything works as expected.
In the beginning of this post we mentioned two main problems with the existing pipeline: Latency and Data Quality and we will go over them and showcase the results one by one.
From Latency perspective:
For Data Quality:
In the future, we plan to first train the model on an hourly basis using warmstarting (e.g. initializing a model with weights from a previously trained model). We will also explore streaming training to replace the batch training. So please stay tuned.
Home Timeline’s Streaming Logging Pipeline is developed by Peilin Yang, Ikuhiro Ihara, Prasang Upadhyaya, Yan Xia and Siyang Dai. We would like to thank Arvind Thiagarajan, Xiao-hu Yan, Wenzhe Shi and the rest of Timelines Quality for their contributions to the project and this blog, and a special shoutout to leadership for supporting this project - Xun Tang, Shuang Song, Xiaobing Xue and Sandeep Pandey. During the development, Twitter’s Messaging team provides tremendous help with Kafka and we would like to thank Ming Liu, Yiming Zang, Jordan Bull, Kai Huang, Julio Ng for their dedicated support.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.