Infrastructure
Scaling data access by moving an exabyte of data to Google Cloud
By
and
Tuesday, 17 May 2022
Twitter has been serving the public conversation for over 15 years. In those 15 years, much has changed from a technological perspective as we’ve continued to evolve with the times. One evolution, which we’ve previously discussed on the blog, is the history of data warehousing at Twitter and what’s next.
In 2019, we embarked on a mission to democratize data analysis for our employees by making it easier for our Tweeps to analyze and visualize data while enabling faster machine learning. To achieve this, we partnered with Google Cloud to migrate parts of our data infrastructure to the Google Cloud Platform (GCP) and began leveraging their Big Data tools, including BigQuery, Data Studio, and Dataflow to expand the internal group of customers at Twitter who could use that information to gather insights.
This blog post is a technical dive into how we approached our migration to BigQuery, what we learned, and how it’s going.
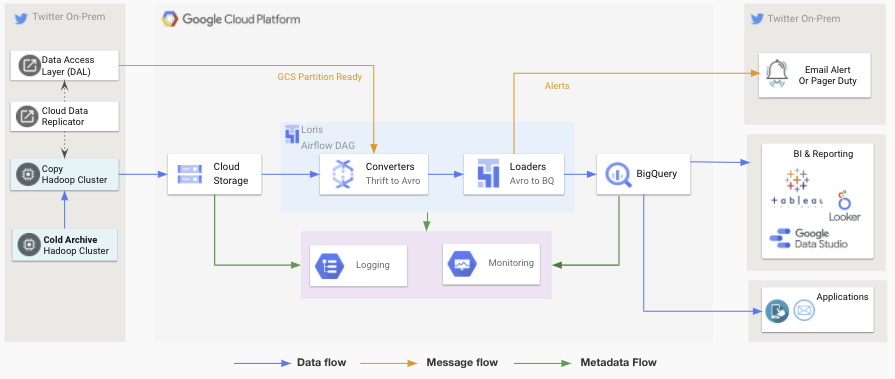
After making the decision to use Google Cloud Platform as our central data warehouse, which is the foundation for our data analytics and machine learning work, the first step we had to take in democratizing our access to data for Tweeps within the company was to answer the question, “How do we get our Hadoop on-premise data into BigQuery in the most efficient way?”
Prior to our use of BigQuery, much of our data was stored in HDFS in Thrift format. At first, we approached the migration process by using a point solution where individual teams carried out the task of manually ingesting their data from our on-premise Hadoop filestore into BigQuery using Scalding libraries we provided. This solution had technical challenges, including proxy limitations of 77gbit/s of bandwidth from ingesting data from our data centers into GCP’s, and increased processing time due to technical limitations of map-reduce and nuances of job optimizations that came with it.
However, this approach was not very convenient for our Tweeps due to the amount of time that was spent onboarding, getting the right permissions, and learning the tooling before teams could begin the ingestion process. This meant less coverage in the availability of our data due to long development times for each dataset, with each dataset requiring roughly two weeks of development time. Additionally, each data pipeline - a Scalding job - was self-managed, which meant we lacked a holistic picture of the quantity of data sets, job progression, and other systematic issues associated with the data ingestion process.
Ultimately, this presented two key challenges: intensive time spent on behalf of our teams through increased operational burden and inefficiency in our use of computing resources.
The way we solved for these challenges was by creating a managed solution that’s centralized, automated, and designed to reduce the burden of individual teams to ingest their own data.
Rather than continue to have our teams ingest their own data manually, we wanted to build an automated framework that could shift our data pipelines from a self-managed model while reducing barriers to getting data into a consumable format. We did this by building our automated framework on top of existing services, such as Dataflow and Airflow, to ultimately ingest more than 1,000 datasets with a simple configuration file. The objective of this framework was to get our data into Google Cloud Platform and Big Query in the most efficient way.
Here’s how we approached designing this framework:
Because we generate and ingest large amounts of data into BigQuery daily, our data processing work is very CPU intensive. This required us to be intentional in how we consumed these resources as our Scalding jobs were previously limited by our on-prem capacity. One way we’ve overcome this challenge is by tapping into the tuning and auto scaling aspects that Google Cloud Platform provides.
Prior to our adoption of Google Cloud Platform, we manually managed cluster tuning and provisioning of our on-premise resources. This meant that we needed to very carefully plan in order to ensure we had enough capacity for data processing. However, now that we’ve migrated to cloud services, we can partner with GCP to get the capacity we need and parallelize the processing of data while creating a uniform solution across all jobs.
Moving our data processing from Scalding jobs to Dataflow required flexibility in the format of the data as we had many features, formats, and legacy code. Through the development of our automated data processing solution into Google Cloud Platform, we were able to migrate complex processing logic from Scalding to Dataflow and in turn scale our ability to process data by alleviating the limitations of on-premise capacity. Total ingested datasets increased, as failure rate of our service was lowered because of auto-schema detection and hourly partitioning.
The result of this work is that this solution powers Twitter’s Core Ads product analytics, ML feature generation, and portions of the personalization models.
This approach enables Twitter employees to run over 10 million queries a month on almost an exabyte of data in BigQuery. By developing an automated framework, we were able to:
This successful partnership with Google Cloud allowed us to leverage Open Source libraries to enhance the productivity of our teams with the release of our first iteration, which we achieved in under three months. Additionally, our work with BigQuery provided out-of-the-box solutions for orchestration, monitoring, and dynamic resource allocation. Automating the ingestion of datasets unlocked our ability to provide data at scale with lower onboarding costs and less engineering work for all product teams. This allowed our engineers to focus on data processing logic and abstraction of configuration to automate the ingestion of 1000s of datasets, and ultimately allows us to move faster and serve more relevant content to the people who use our service every day.
For more of the story about how Twitter is using BigQuery, read this blog from Google Cloud.
We would like to thank the following contributors for all they’ve done to further this work:
Tushar Arora, Yang Xu, Michael Gonzalez, Bi Ling Wu, Zhenzhao Wang, Dongjae Kim, Abhishek Bafna, Eduardo Ohe, Josh Peng, and Vrishali Shah.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.