Infrastructure
Powering real-time data analytics with Druid at Twitter
By
and
Friday, 13 May 2022
An important characteristic of Twitter is its real-time nature. Consequently, many of Twitter’s projects need real-time analytics as a platform service. In recent years, Twitter’s data platform team has evolved Druid as a real-time centralized analytics platform at Twitter. Druid is a real-time analytics database designed for fast slice and dice analytics on large datasets. It is most often used as a database for powering use cases where real-time ingestion, fast query performance, and high uptime are important.
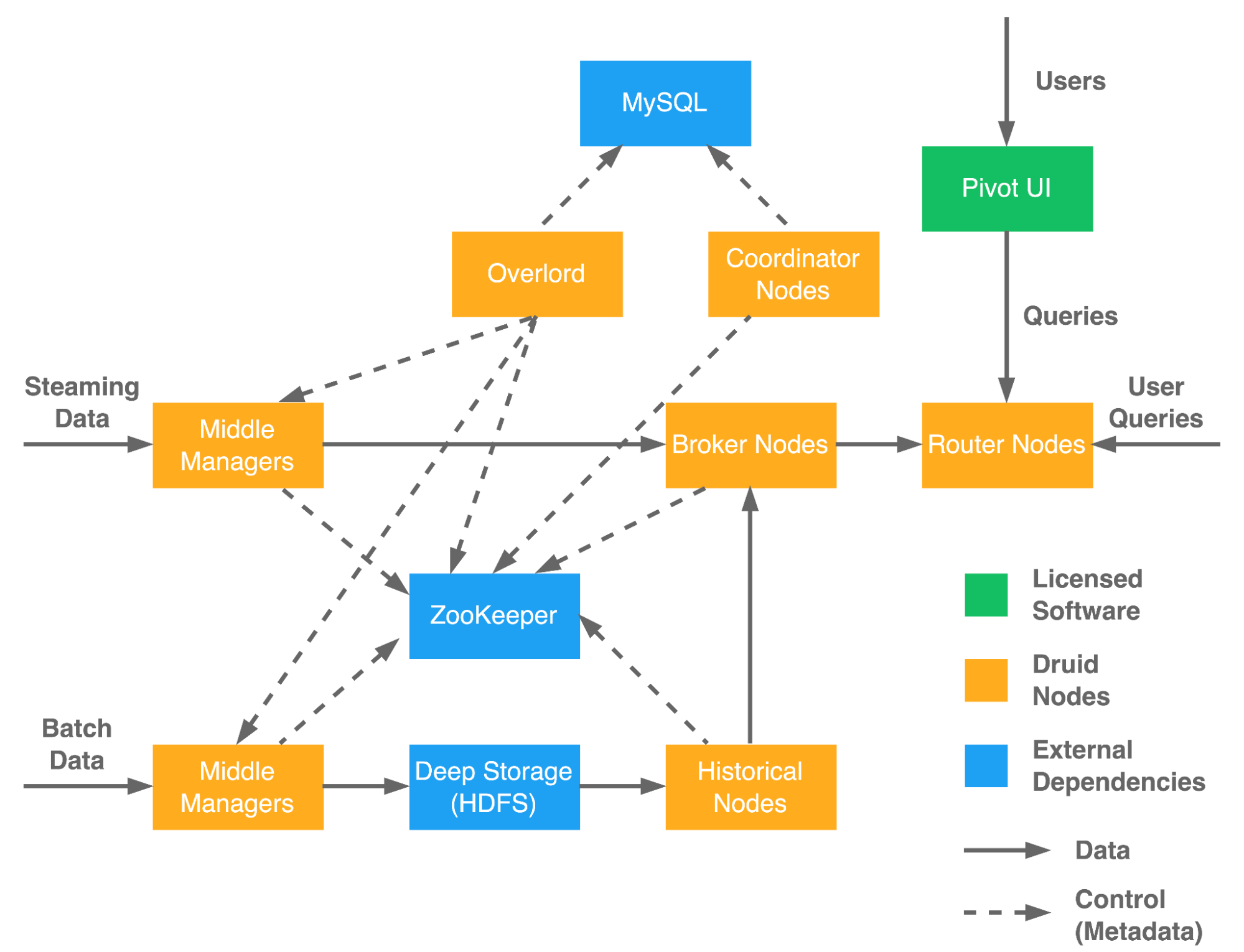
Currently, we are operating 7 Druid clusters in production setup on-premises and on Google Cloud Platform (GCP) under the Partly Cloudy strategy. Our biggest Druid cluster is serving Petabyte-scale data to internal customers. The infrastructure for the biggest Druid cluster consists of more than 5,000 nodes in a multi-tenant setup. To balance performance and cost, we have set up fast (1:2 memory:disk), slow (1:4 memory:disk), and cold (1:16 memory:disk) historical tiers. We keep the most frequently-used datasets in the fast tier for 90 days, all other datasets for 90 days in the slow tier, and older data in the cold historical tier.
Twitter’s Druid platform supports the following use cases:
In Twitter’s Druid platform, the daily/hourly batch jobs generate output data on Hadoop Distributed File System (HDFS) and Google Cloud Storage (GCS) in JSON/Avro/Parquet/Thrift formats which can be consumed by Druid. If the data source is a BigQuery table, the table will be exported to GCS first in Avro format. Meanwhile, streaming ingestions consume data from Kafka topics, generated from upstream services. Middle managers are responsible for loading data from external data sources and publishing new Druid segments, which are files partitioned by time. The overlord node watches over the middle managers, handles ingestion task management, and maintains a task queue that consists of customer-submitted data ingestion tasks.
Customers leverage various tools such as Pivot and Looker to query and visualize Druid datasets via the router node. The queries are forwarded to broker nodes, which fetch subquery results from historical nodes and middle managers. Broker nodes understand the metadata published in ZooKeeper about which segments are queryable and where those segments are located.
Data ingestion is one of the most challenging problems to handle in Druid because the solution can significantly change based on the service hosting platform, current data location, ingestion type, and SLA requirements.
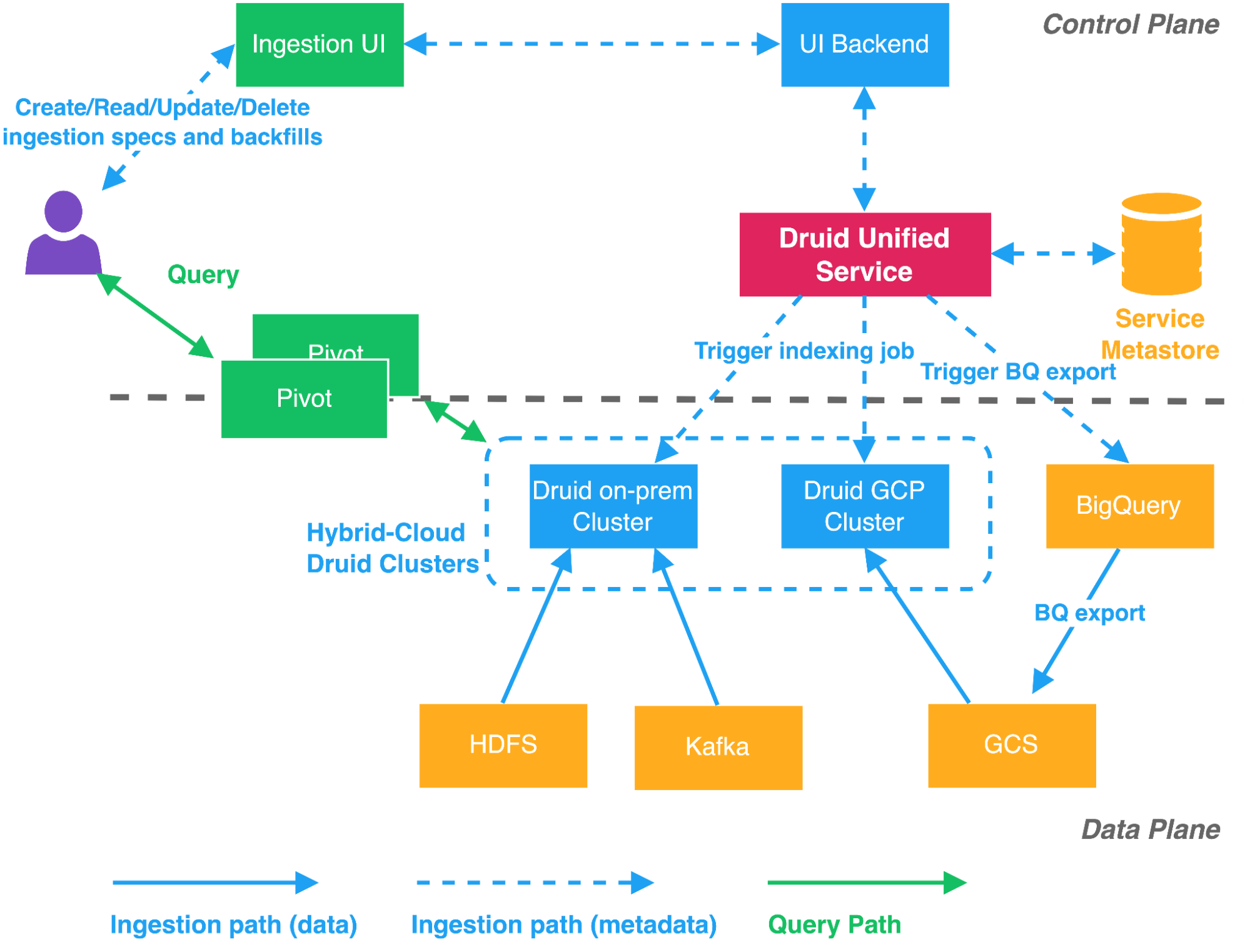
Dating back to 2018 when Druid was initially adopted at Twitter, the Druid Ingestion framework was integrated with the Twitter data processing tools and technologies like Scalding, DAL (Data Access Layer), and Statebird, the service to track states of batch jobs. As the number of customers and datasets grew, the onboarding process was extremely time-consuming and required lots of data processing ecosystem knowledge. To overcome this, we developed unified services to load data into Druid from various input sources like HDFS, Kafka, BigQuery, GCS, and Druid (reindexing).
We implemented a Druid Unified Service that reads ingestion metadata from the metastore and periodically submits it to the Druid overlord node after suitable modifications. The unified service aims to significantly reduce the customers’ burden of complicated data ingestion. We also created a Druid ingestion UI integrated with our internal UI “EagleEye”, a tool for exploring Twitter's Data Pipeline, including finding and managing data sources.
In the new ingestion workflow:
After data is ingested into Druid, customers can always query the datasets loaded from various data sources including HDFS, GCS, and Kafka. The unified ingestion workflow also supports backfills and reindexing of existing Druid segments. It enables Twitter Engineers, Data Scientists, Data Engineers, and Product Managers to easily and reliably conduct sub-second interactive analytics on real-time and batch data without writing a single line of code anywhere data exists, such as in the GCP and on-premises environment.
With the successful adoption of Druid, Druid has powered a wide spectrum of use cases at Twitter and proven its capability as a real-time analytics platform. Due to the complexity of data ingestion into Druid, we developed a unified ingestion service to dramatically reduce the burden of data ingestion. The unified service paves the path towards a unified Druid ingestion experience.
Meanwhile, we are continuously improving Twitter’s Druid platform to meet our scale and new use cases:
Twitter’s Druid platform is a complicated unified project that has been evolving for years. We would like to express our gratitude to Zhenxiao Luo, Yao Li, Mainak Ghosh, Nikhil Kantibhai Navadiya, and Anneliese Lu for their contributions to the Druid platform. We are also grateful to Prateek Mukhedkar, George Sirois, Vrushali Channapattan, Maosong Fu, Daniel Lipkin, Derek Lyon, Srikanth Thiagarajan, Jeremy Zogg, and Sudhir Srinivas for their strategic vision, direction, and support to the team. Finally, we thank Huijun Wu, Bethany Lechner, Brenna Sanford, Shrut Kirti, Jessica Friedman, Leah Karasek, and Dunham Winoto for their insightful suggestions that helped us significantly improve this blog.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.