Infrastructure
Data transfer in Manhattan using RocksDB
By
Monday, 28 February 2022
Manhattan is Twitter’s internally-developed distributed key-value store. It’s the default storage solution at Twitter for persistent real-time serving needs. It is used to serve all core nouns at Twitter including Tweets, Users, and Direct Messages (DMs). Previously, we wrote about Manhattan’s pluggable storage engine design and how we adopted RocksDB as the storage engine for all its read-write workloads.
In this post, we’ll talk in more detail about a performance and stability problem we encountered during the migration and how we solved it.
Data transfer between storage machines is a typical process in any distributed system that stores persistent data. There are typically two reasons why this data transfer occurs:
When you remove nodes from a cluster. For example, the hardware of a machine starts failing and it needs to be taken out of the cluster for maintenance. The data that was previously served by the node being removed needs to be transferred and served from a different node now.
When you add nodes to a cluster. For example, the cluster is getting overloaded with traffic/data and needs additional capacity (that is nodes) to handle the workload. There is a transfer of data from the existing nodes to the newly added nodes to evenly distribute the data across all the nodes in the cluster.
The faster a database cluster is able to handle this data transfer, the sooner it will be in a healthy state. This is because you don’t want bad hardware to linger in your cluster for too long while removing nodes. Similarly, you want the ability to add capacity to your cluster quickly in the event of large traffic spikes.
In Manhattan, we refer to the process of transferring data from one node to another as streaming. Streaming can typically be done in two ways:
Optimized Streaming (File-based transfer): In this case the source node generates and sends over ingestible [1] data files to the destination node. The destination node ingests those files and becomes the new owner of that piece of data.
Generic Streaming (Record-based transfer): In this case, the source node iterates through all its data and sends over individual records to the destination node. The destination node writes these records to its storage as it receives them and at the end of the transfer it becomes the new owner of that piece of data.
While the optimized streaming can be better and more efficient, if the cost of generating the ingestible data files is high, then generic streaming becomes the more viable option. This was exactly the case for us, and we’ll expand more on this in the next section.
During the RocksDB adoption, we started with generic streaming when we migrated data from our older SSTable/MhBtree storage engines to the RocksDB storage engine, as mentioned in an earlier blog post. As each storage engine stores data differently (in that it uses different file formats), optimized streaming wouldn’t work as the files wouldn’t be ingestible at the destination node.
However, generic streaming speed was slow and it took a long time to add and remove nodes from the cluster. We sped it up as much as we could until we started encountering write-stalls on the destination node. This was because generic streaming is similar to a spike in frontend write traffic as the data arrives in the form of individual write requests. We thought that using optimized streaming, after the data migration was complete, would speed this up and prevent us from running into blockers such as write-stalls. Unfortunately, we faced other issues while implementing optimized streaming.
RocksDB recommends creating ingestible SST files by iterating over the entire database and creating them using rocksdb::SstFileWriter. This is because the live SST files that the database uses are not directly ingestible by other databases. Instead, RocksDB iterates over the database to produce a set of SST files that contain all the data in increasing order. These files can then be transferred over to another database for ingestion. Ingesting such SST files improves load-time considerably as there are no duplicates and all the data is sorted. However, since the file generation time was considerable we decided to invest in our existing generic streaming solution first while prototyping optimized streaming for RocksDB.
Let’s lay some background before we jump into how we optimized our existing solution.
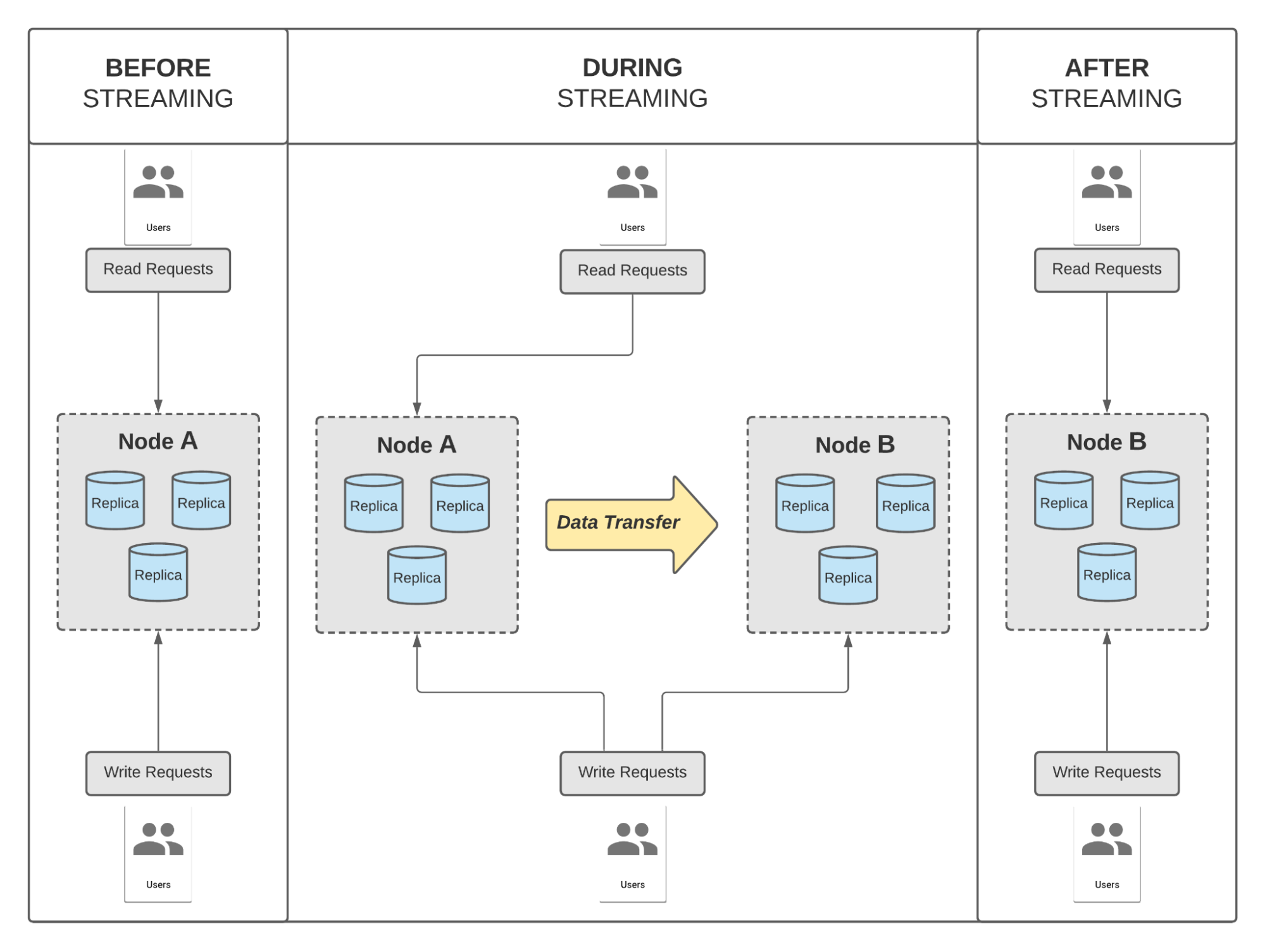
As you can see above, during streaming from node A to node B, we’re performing live writes to both nodes but reading only from node A (a typical practice during migrations).
There is a key takeaway here:
Until the transfer is complete, we’re not serving any reads from node B. Hence, we don’t care about the read performance of node B.
Thinking back to the blocker we hit earlier while trying to speed up generic streaming - we saw write-stalls on the destination node. One of the main purposes for RocksDB to stall writes is to allow compaction to keep up with the write rate. This prevents the build up of stale records by regularly getting rid of older values that have been overwritten. This reduces the number of files we need to query for a single read, that is read amplification, and therefore keeps the read performance from degrading. However, since we don’t care about the read performance of node B (destination node), we should not be stalling writes as there’s nothing [2] to protect.
Therefore, we came up with the following algorithm (simplified version):
Nodes A and B acknowledge that certain data will be transferred from A to B.
Node B disables write-stalls by setting the write-stall thresholds to extremely large values.
Streaming occurs at a high speed from node A to B.
After all the data has reached node B, B initiates a manual compaction of the entire database. This reduces space and read amplification that might have increased during streaming. This compacts all the data to the last level.
After manual compaction is finished, we reset the write-stall thresholds that were modified in step 2 to their original values.
Finally, we mark the data transfer from A to B as complete.
This allowed us to remove any artificial limits that RocksDB put on the streaming speeds. This meant we were able to speed up generic streaming until we hit other resource constraints such as CPU usage and disk I/O.
We saw major performance improvements in generic streaming using the above algorithm. Compared to our speeds before, we were able to make the overall data transfer speed anywhere from 200% - 700% faster.
We could speed this up further, but we encountered the following constraints:
Manual compaction in step 5 of the algorithm is hard to speed up as we don’t use sub-compactions.
We host multiple RocksDB databases on a single machine, so eventually there was contention of CPU and memory resources with other RocksDB instances that weren’t streaming.
We hit other forms of rate-limiting that are meant to protect the node from scenarios like network bandwidth saturation, hotspots, hotkeys, etc.
Finally, we conducted a performance comparison test between the sped-up generic streaming solution and the prototype optimized streaming solution. We found that the time it took for optimized streaming to generate ingestible SST files, transfer them over the network, and ingest into the new database was quite similar to generic streaming’s performance overall.
If RocksDB is able to provide support for a feature like checkpoints for generating ingestible SST files efficiently, it might make a strong case for us to implement optimized streaming in the future. However as of now, we decided to not invest further in productionizing the optimized streaming solution as the performance gains were insignificant.
Special thanks to Sowmya Pary and Vijay Teja Gottipati for their contributions to this feature.
[1] By “ingestible” we mean data files that can be read by the database directly without any major processing.
[2] Write-stalls also protect disk usage by keeping space amplification in check. For our purpose, most nodes were not storage-bound so this is not something we needed to worry about.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.