Infrastructure
Kafka as a storage system
By
Wednesday, 16 December 2020
When developers consume public Twitter data through our API, they need reliability, speed, and stability. Therefore, some time ago, we launched the Account Activity Replay API for the Account Activity API to let developers bake stability into their systems. The Account Activity Replay API is a data recovery tool that lets developers retrieve events from as far back as five days. This API recovers events that weren’t delivered for various reasons, including inadvertent server outages during real-time delivery attempts.
In addition to building APIs that will provide a positive developer experience, we also optimize for:
For these reasons, when building the replay system on which this API relies, we leveraged the existing design of the real-time system that powers the Account Activity API. This helped us reuse existing work as well as minimize the context switching and training that would have been required had we created an entirely different system.
The real-time system is built on a publish-subscribe architecture. Therefore, in keeping to these goals, building the storage layer we would read from drove us to rethink a traditional streaming technology -- Apache Kafka.
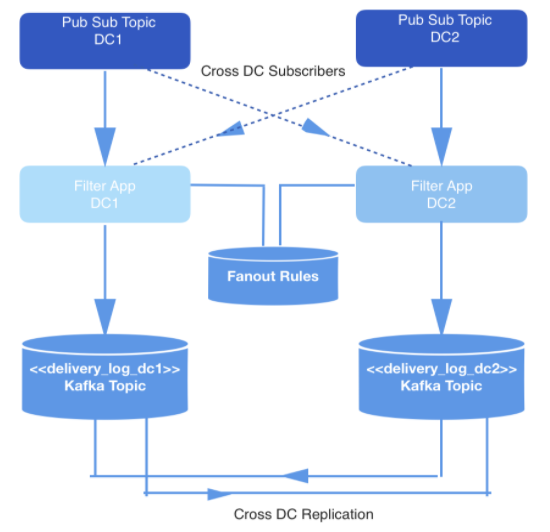
Real-time events are produced in two datacenters (DCs). When these events are produced, they are written into pub-sub topics that are cross-replicated across the two DCs for redundancy purposes.
Not all events should be delivered so they are filtered by an internal application which consumes events from these topics, checks each against a set of rules in a key-value store, and decides whether the event should be delivered to a given developer through our public API. Events are delivered through a webhook, and each webhook URL owned by a developer is identified by a unique ID.
Ordinarily, when building a replay system that requires storage like this, one might use an architecture based on Hadoop and HDFS. We chose Apache Kafka instead for two reasons:
We leverage the real-time pipeline to build the replay pipeline by first ensuring that events that should have been delivered for each developer are stored on Kafka. We call the Kafka topic the delivery_log; there is one in each DC. These topics are then cross-replicated to ensure redundancy which allows for serving a replay request out of one DC. These stored events are deduplicated before they are delivered.
On this Kafka topic, we created multiple partitions using the default semantic partitioning mechanism. Therefore, partitions correspond to the hash of a developer’s webhookId, which is the key for each record. We considered using static partitioning but decided against it because of the increased risk of having one partition with more data than the others if one developer generates more events than others. Instead, we chose a fixed number of partitions to spread out the data with the default partition strategy. With this, we mitigate the risk of unbalanced partitions and don’t need to read all the partitions on the Kafka topic. Rather, based on the webhookId for which a request comes in, a Replay Service (referenced below [Requests and Processing]) determines the specific partition to read from and spins up a new Kafka consumer for that partition. The number of partitions on the topic does not change because this affects the hashing of the keys and how events are distributed.
We use solid-state disks (SSDs), given the amount of events we read per time period. We chose this over the traditional hard drive disks for faster processing and to reduce the overhead that comes with seek and access times. it’s better to use SSDs for faster reads because we access infrequently accessed data and thus we don’t get the benefits of the Page Cache optimizations.
To minimize storage space, this data is compressed using snappy as the compression algorithm. We know most of our processing is on the consumption side. We chose snappy because it's faster when decompressing than the other Kafka-supported compression algorithms: gzip and lz4.
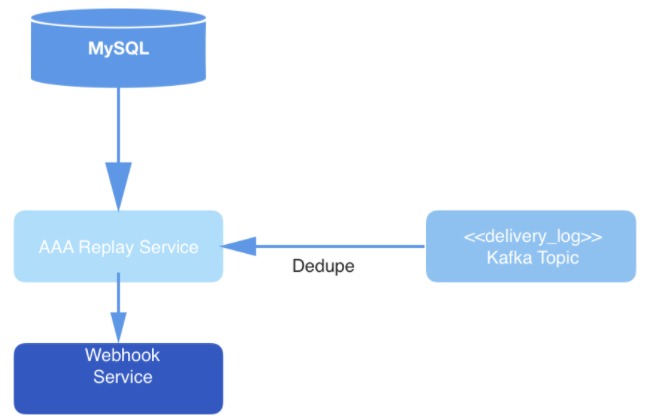
In the system we designed, an API call sends replay requests. As part of the payload in each validated request, we get the webhookId and the date range for which events should be replayed. These requests are persisted into MySQL and enqueued until they are picked up by the Replay Service. The date range on the request is used to determine the offset on the partition to start reading from. The offsetForTimes function on the Consumer object is used to get the offsets.
Replay Service instances process each replay request. The instances coordinate with one another using MySQL to process the next replay entry in the database. Each replay worker polls MySQL periodically to know the pending job that should be processed. A request transitions between states. A request that has not been picked to be worked on is in an OPEN STATE. A request that was just dequeued is in a STARTED STATE. A request that is being processed is in an ONGOING STATE. A request that is done transitions to a COMPLETED STATE. A replay worker picks only a request that hasn't been started (that is, a request in an OPEN state).
Periodically, after a worker has dequeued a request for processing, the worker heartbeats the MySQL table with timestamp entries to show that the replay job is still ongoing. In cases where the replay worker instance dies while still processing a request, such jobs are restarted. Therefore, in addition to dequeuing only requests that are in an OPEN STATE, replay workers also pick up jobs that are in either a STARTED or ONGOING STATE that got no heartbeat for a predefined number of minutes.
Events are eventually deduplicated from the topic while being read and then published to the webhook URL of the customer. The deduplication is done by maintaining a cache of the hash of the events being read. If an event with the same hash is encountered, it isn’t delivered.
In summary, our solution isn't a traditional real-time, streaming use of Kafka as we know it. However, we successfully used Kafka as a storage system in building an API that optimizes customer experience and data access in recovering events. Leveraging the design of the real-time system makes it easy to maintain our systems. In addition, the speed of recovery for our customers is as we envisaged.
Building a service as this would not have been possible without the help of people like Owen Parry, Eoin Coffey, Lisa White, Andrew Rapp, and Brent Halsey. Special thanks to Lisa White, Chris Coco and Christopher Hogue for reading and reviewing this blog.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.