Infrastructure
Native secondary indexing in Manhattan
By
Thursday, 20 December 2018
Manhattan is Twitter’s multi-tenant, distributed, real-time database. Check out our previous blog posts about architecture, strong consistency, and Manhattan’s deployment process. In this post, we explain why and how we built native secondary indexing support in Manhattan, and the different approaches that were considered with their pros and cons.
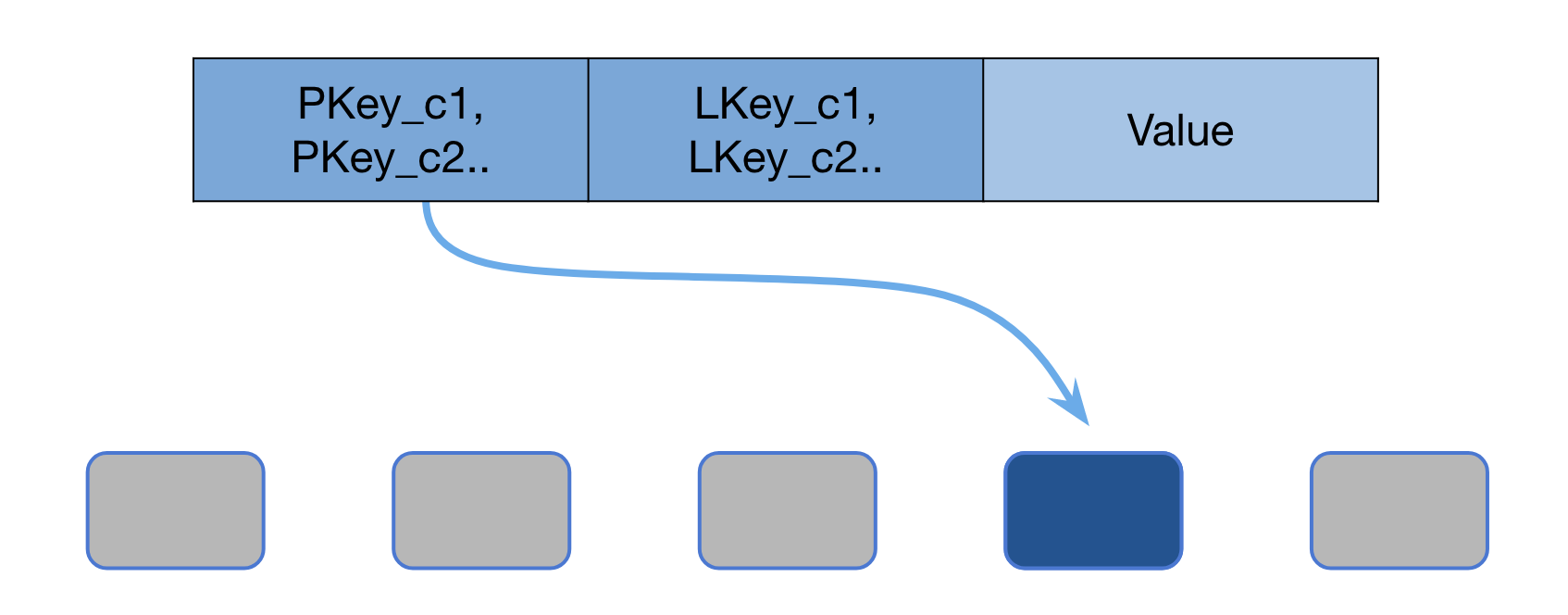
A Manhattan cluster can contain one or more datasets. Manhattan provides a data model where each record contains a partition key (PKey) and a local key (LKey) mapping to a value. A partition key, as the name suggests, is used to partition a record onto different nodes. A partition key can have multiple local keys that are sorted. Given a PKey, users can perform range queries to fetch many LKeys. PKeys and LKeys can contain multiple components. Apache Thrift is used extensively at Twitter. As a result, many datasets store thrift blobs as values. We will refer to the different components in keys or fields of thrift blobs as fields of a record.
As the number of use cases for Manhattan increased within the company, some applications needed different ways to fetch the data. Applications started solving their needs by duplicating the data into a new dataset with different partition and local keys. Maintaining correctness of index dataset was a challenge as Manhattan doesn’t have transaction support.
Manhattan supports two types of secondary indexing:
We will use the following hypothetical example dataset to demonstrate how global secondary indexing works in Manhattan.
Dataset: user_contact
PKey: UserId
LKey: Label
Value: struct Contact {
1. optional string email,
2. optional string street,
3. optional string city,
4. optional string state,
5. optional string country,
6. optional i32 zip_code
}We need to support queries like
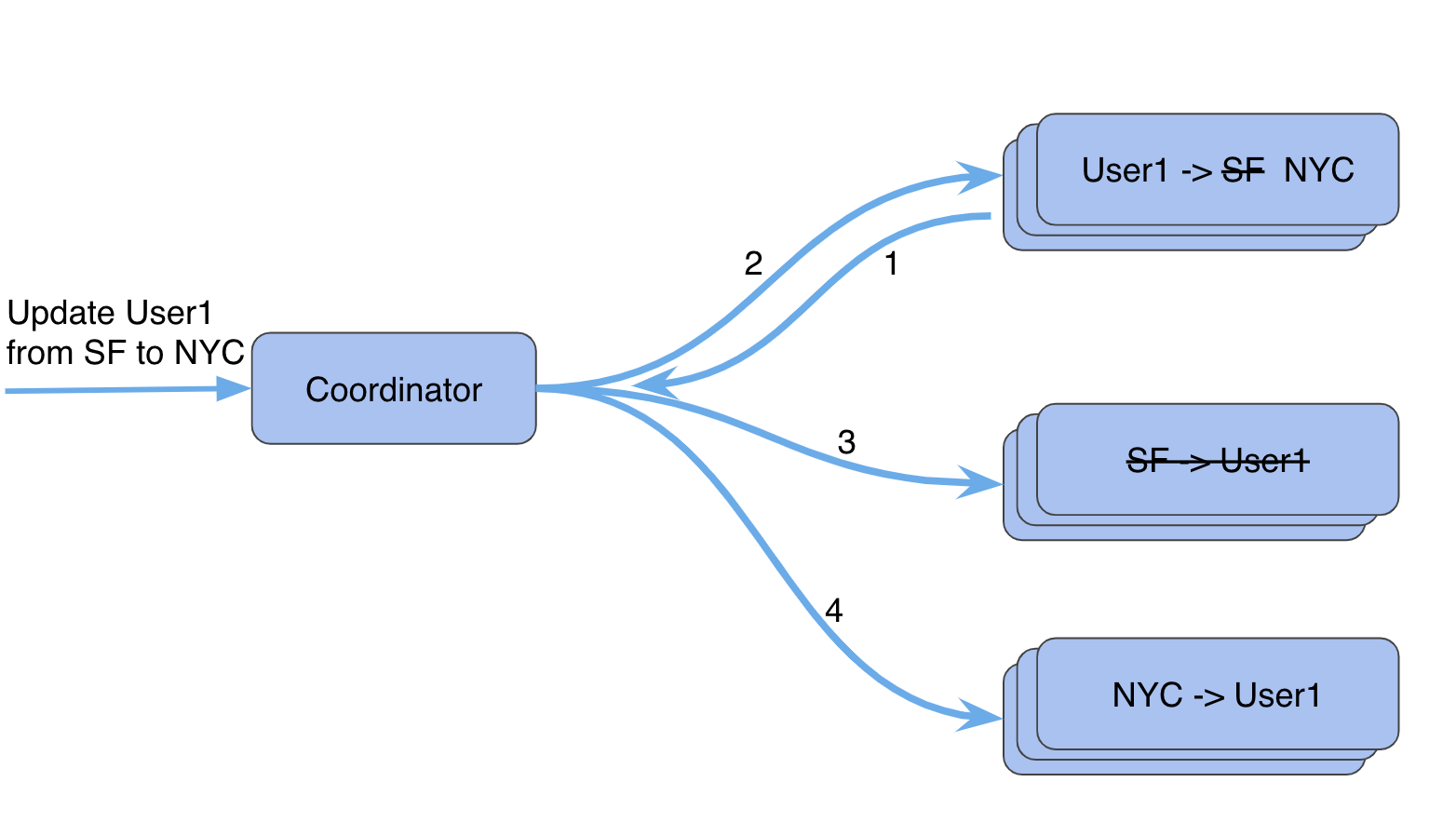
To build a secondary index on “City”, we can use a hidden dataset to store these index records with “City” as the PKey, base record’s PKey, LKey as index LKey, and optionally duplicate the value. An index record should be inserted/updated along with changes to the base record. In an update scenario, a total of four operations need to be performed.
In our example query, when a user1 moves from San Francisco to New York, we need to:
There are several ways to approach this problem
We chose not to implement transactions in Manhattan. We have implemented strong consistency on a key level as described here and wanted to build indexing on top of existing architecture rather than making significant changes. If we were to implement this option, the write latency would increase significantly. Index read latency would be similar to a normal read if we materialize the value in the index or be twice if we only store pointers and retrieve the value from the base record.
We can insert a base record, queue the task of updating indexes, and do it asynchronously. This can be done either at coordinator or on backend nodes using a distributed message queue. With this option, the impact on write latencies will be very low. Index reads will be eventual with respect to the base record. Which means:
While this solution might be acceptable for some use cases, it is not acceptable for the applications that heavily rely on Manhattan’s read-my-own-writes guarantee within a region.
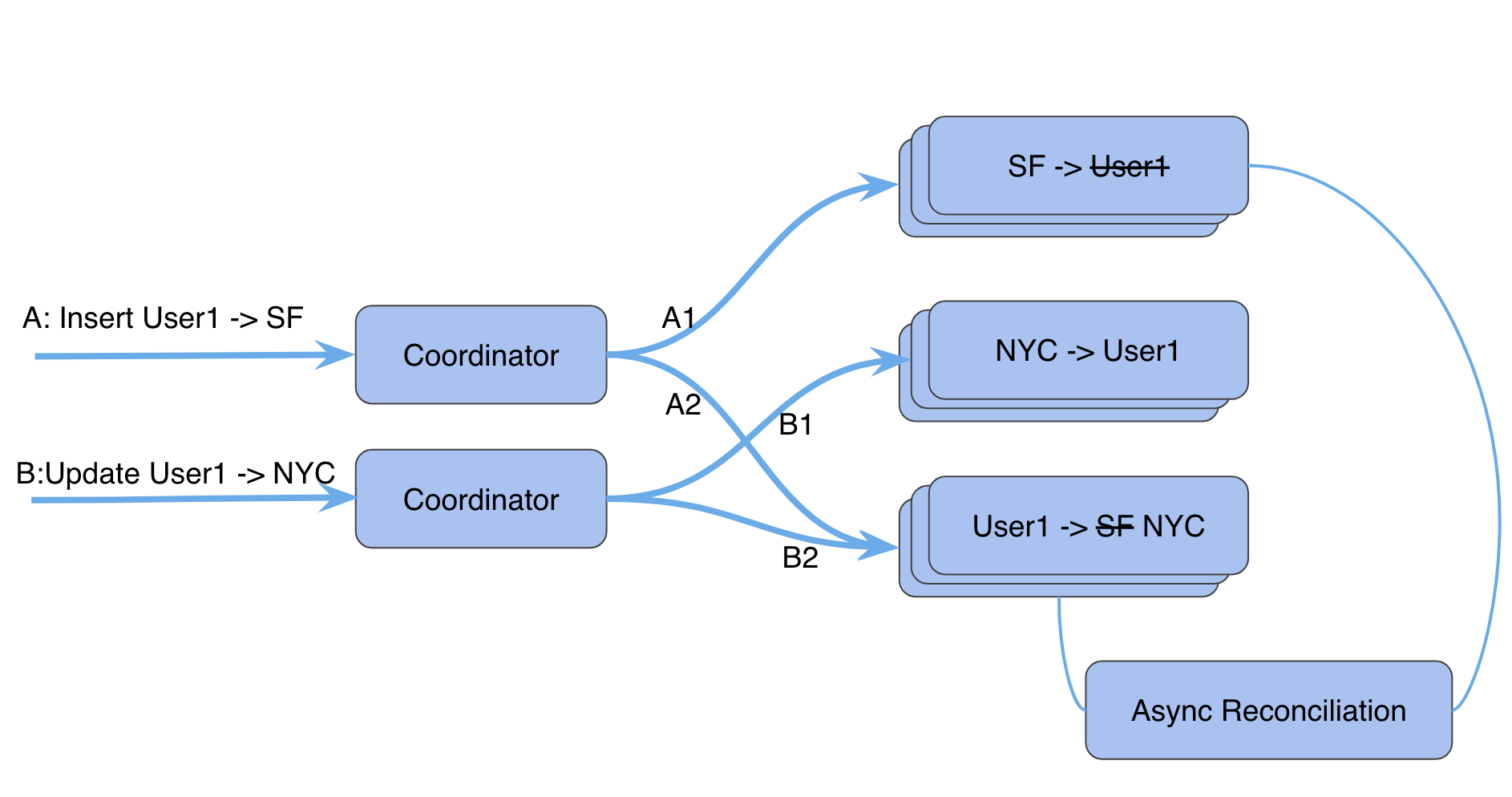
We looked for a solution that guarantees read-my-own-writes in a region with a tradeoff of increased latency.
Write the new index record (or multiple in parallel), only if it succeeds, write the primary record. Updates can result in stale index records as we do not delete the old ones, which required a sequential read followed by a delete. In the read path, send an additional request to verify if every index record fetched is still pointing to the valid primary record. These requests are sent in parallel when an index read results in multiple records. An asynchronous background job periodically cleans up the stale index records.
This solution guarantees read-my-own-writes within a region and works within a bounded latency increase of 2X for both reads and writes. An index read on a field like “Email” will require a single or very few extra reads to verify and populate the value. When a use case needs to read many records from an index (ex: index on “City” in our example), the performance will suffer due to many parallel reads. We added an ability to specify a custom ordering on the results by prefixing the field to the index key. For example, one can order results by timestamp to fetch the most recently updated values first. The application can slowly iterate over the results (a few tens at a time) sorted by a custom field.
We will use the following hypothetical dataset as an example to demonstrate how local secondary indexing is implemented.
Dataset: user_events
PKey: UserId
LKey: EventId
Value: struct Event {
1: optional string location,
2: optional i64 timestamp
..
}
We need to support queries like:
We use a similar approach, create a hidden index dataset, and store inverted lookup. Since the partition key is the same, the index records will map to the same partitions as the base records. We use the combination of the index key and base record’s local key as the local key for index record. This allows us to prefix match on index keys and read multiple LKeys.
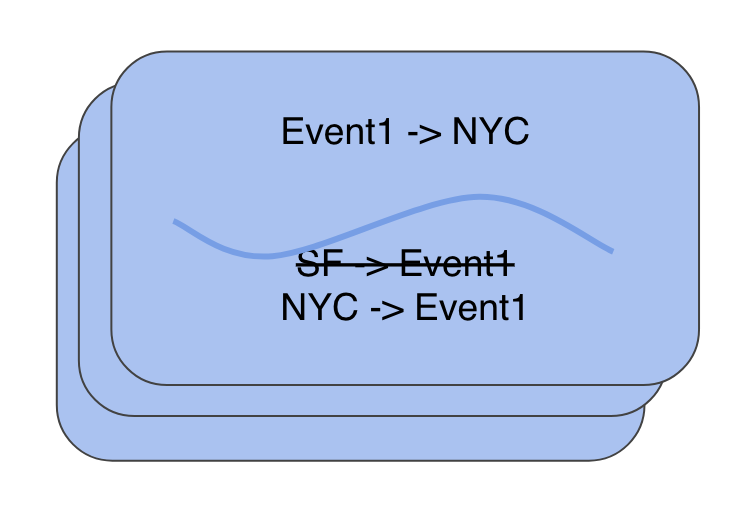
On a single node, we can synchronously update index records in a transaction. Index reads can either directly read from index dataset if the value is materialized or populate it from the base record.
This seems like it should guarantee read-my-own-writes in a region. Though this is true in most cases, there is a possible sequence of events in which synchronous updates in a storage node does not guarantee that the updates are always reflected in a quorum read. Consider the following example:
The chances of this sequence of events happening increases during a rolling restart/upgrade of the cluster. The data will be repaired in a matter of hours and the reads will eventually become consistent, but there is a window during which an index read can return stale data.
For use cases that need 100% read-my-own-writes guarantees, we need to do a quorum read to verify if the results of index read have a corresponding active base record. When this option is chosen, we need not materialize the value. As mentioned before, this is a rare scenario and we only need to verify when one of the storage nodes return an empty result for a key. Customers can choose between eventual consistency vs. read-my-own-write guarantee by opting to avoid this additional verification.
Native secondary indexing in Manhattan was built in close collaboration with our customers, other developers at Twitter. It is a powerful addition to the list of features supported in Manhattan. Here are a few important design and implementation choices we made:
Special thanks to Jigar Bhati, Xiao Chen, Yalei Wang, Boaz Avital, Peter Schuller, and Unmesh Jagtap for their contributions to the project.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.