Infrastructure
Dynamic configuration at Twitter
By
Tuesday, 20 November 2018
Dynamic configuration is the ability to change the behavior and functionality of a running system without requiring application restarts. An ideal dynamic configuration system enables service developers and administrators to view and update configurations easily, and delivers configuration updates to the applications efficiently and reliably. It enables organizations to rapidly and boldly iterate on new features, and empowers them with tools to reduce the risk associated with changing existing systems.
In the early years of Twitter, applications managed and distributed their own configurations, commonly using ZooKeeper to store them. However, our previous experience with operating ZooKeeper had shown that it did not scale when used as a generic key-value store. Other teams turned to Git for storage, combined with custom tooling to update, distribute, and reload the configurations. As Twitter grew, it became clear that a standard solution was needed to provide scalable infrastructure, reusable libraries, and effective monitoring.
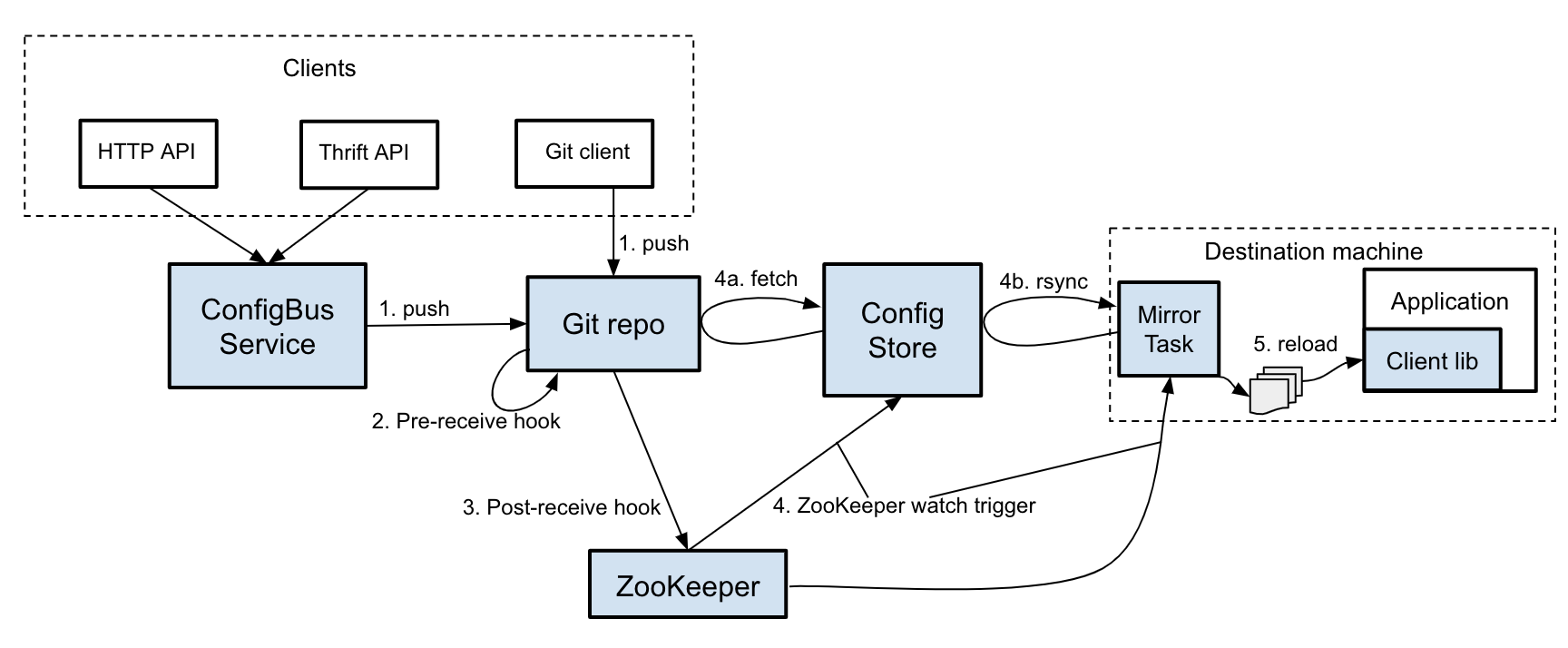
In this blog post, we will describe ConfigBus, Twitter’s dynamic configuration system. ConfigBus is made up of a database for storing configurations, a pipeline to distribute the configurations to machines in Twitter’s data centers, and APIs and tools to read and update them.
At a high level, you can think of ConfigBus as a Git repository whose contents are pushed out to all machines in Twitter’s data centers. A configuration change goes through a series of steps before reaching its destination:
Eventually, the system quiesces so that the files changed in step 1 are synced to all destination machines and reloaded by all client applications that depend on them.
Using Git allows developers to reuse many of the same commands and workflows that are available for source repositories. Mainly, Git and the ecosystem around it provide the following features:
Once the configurations are safely stored, we need a way to make them available to software running on Twitter’s infrastructure, including services running in our Mesos cloud as well as those running directly on bare metal. This is achieved by pushing the files out to all the machines via rsync. Applications that need to access the configurations can simply read from the local filesystem. The advantages of this are:
One of the main benefits of a dynamic configuration system is to be able to deploy and reload a configuration change independently from the software that uses it. Moreover, a fully dynamic configuration system should be able reload changes without restarting application processes to minimize disruption to the overall application. ConfigBus provides libraries to allow clients to register interest in specific files and invoke callbacks when these files change. While applications can also directly read from the filesystem, using well-tested, conveniently wrapped client libraries has the following advantages:
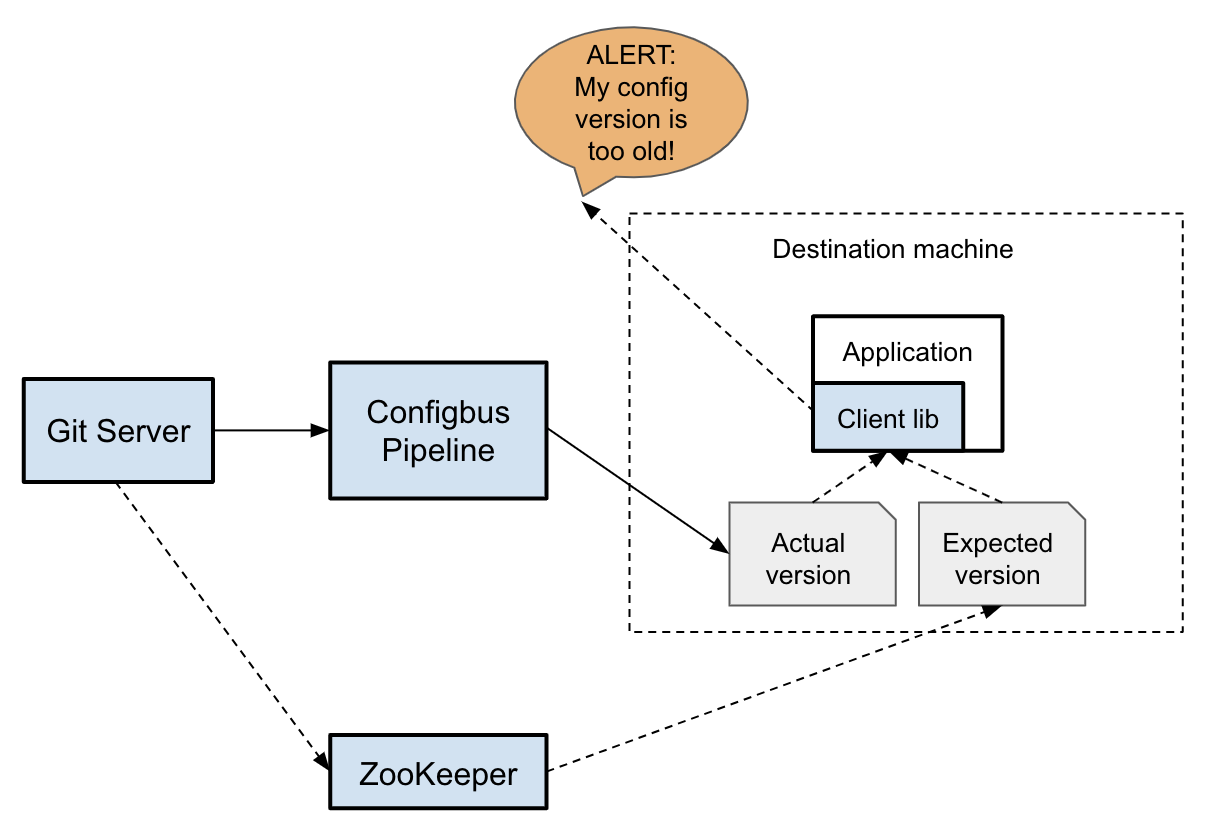
ConfigBus is a complex distributed system with many moving parts. We monitor the system at various levels to gather statistics and create alerts if irregular behavior is detected.
Traffic routing: ConfigBus is used to store routing parameters for services at Twitter. This can be used to control request routing logic (e.g., if a developer wants to route 1% of service requests to a set of instances running a custom version of the software).
Meta service discovery: Services at Twitter discover each other through a service discovery service. However, they must first discover the service discovery service itself. This is achieved via ConfigBus. The advantage of using ConfigBus versus something like, say, ZooKeeper, is that having the information available on the local filesystem on every machine makes the system more resistant to faults (that is, service discovery still works if ConfigBus or ZooKeeper goes down).
Decider: Decider is the feature-flag system used by services at Twitter to enable and disable individual features dynamically at runtime. The system is layered on top of ConfigBus. Decider is key-value oriented (“what is the value of cool_new_feature?”) whereas ConfigBus is file-oriented (“what are the contents of file application/config.json?”). Individual feature flags are called “deciders.” Once embedded in code, deciders can change the behavior of a running application without requiring code changes or redeployment. Among other things, deciders can be used to:
The ‘isAvailable’ method enables developers to switch between code paths like this:
Feature Switches: Feature Switches at Twitter provide a complex and powerful rule-based system for controlling the behavior of applications. Feature Switches control exposure of features as they progress through initial development, team testing, internal dogfooding, alpha, beta, release, and finally sunsetting. Like Decider configurations, Feature Switch configurations are stored in ConfigBus. However, there is a key difference in how the configurations end up on mobile devices. The final leg of the distribution involves mobile applications periodically pulling these configuration updates via a service running in Twitter’s data centers. Feature Switches also provide much more granular controls compared to Decider. Typical Decider configurations are simple, e.g., “Enable 70% of requests in datacenter X to write to the new database.” Feature Switch configurations are higher-level and much more complex, e.g., “Enable this new feature for anyone in team X and also these particular users on this platform.”
Library toggles: Feature Switches and Deciders are designed to help application developers release features safely. Library developers sometimes need similar gating mechanisms when rolling out changes. Finagle, Twitter’s open-source RPC framework for the JVM, provides a toggle mechanism that can be used by library developers to safely release changes, while also providing service owners some level of control. A Twitter-internal implementation of this API uses ConfigBus to provide dynamic control of these toggles.
Perform A/B testing: Running product experiments efficiently requires rapid iteration and easy tuning capabilities. Experimentation frameworks at Twitter use ConfigBus to allow application developers to easily set up and scale experiments, as well as quickly turn them off if needed.
General application configuration: The most typical use of ConfigBus is to store general application configuration files and have them be reloaded dynamically when a change is committed.
We have run ConfigBus in production for close to four years now. Here are some things we learned from running it at Twitter scale:
While near real-time distribution is a goal of ConfigBus, a bad configuration change checked into the repository will quickly propagate everywhere. To minimize the impact of such a change, an optional feature recently added to ConfigBus provides a staged rollout feature that rolls out the change incrementally. This is achieved by pushing both the old and new versions of the configuration along with some additional metadata about the stage of the rollout. Individual application instances then use the stage metadata to dynamically load the appropriate version of the configuration.
As the Git repository grows in age, it also grows in size. A larger repository size slows down operations such as `git clone` and `git add`. The repository size is affected not only by large files being checked in, but also large changes. Here are some of the tactics we use to solve this problem:
We disallow non-fast-forward pushes on the Git repository to protect commits in the master branch from being overwritten by force pushes. The effect of this setting is to require that any push to the repository be made with the most up-to-date copy of the repository. If two committers race to push to the repository, one of them will win and the other will have to pull the latest changes and retry. This increases the latency of the configuration update operation. For frequent committers, this increased latency presents a huge problem. We solve this by partitioning out heavily updated namespaces into separate, dedicated repositories under the hood. Clients that use APIs to make configuration updates notice no difference.
Disallowing non-fast-forward pushes effectively means that ConfigBus is linearizable at the repository level. If two developers are racing to push changes at the same time, one of them will “win” and the other must pull the latest changes and retry. This is true even if the two developers are updating completely different files. For repositories that are constantly updated, this imposes an undue burden on clients. Therefore, we designed the ConfigBus Service to automatically pull updates and retry pushes upon failure. This provides the veneer of file-level linearizability, ensuring that clients only see failures if there is a file-level update conflict.
`git pull` is effectively `git fetch` + `git merge`. The merge step can fail if the clone site on the ConfigStore machines is corrupt or somehow out of sync with the remote server. The safest and cleanest way to get updates from the server in an automated fashion is to run `git fetch` + `git reset --hard FETCH_HEAD` so that it overwrites whatever local state exists at the clone site.
We chose to have a small number of ConfigStore machines fetch from Git and serve as a source for other machines to synchronize from via rsync. We run rsync with the -c option, which forces it to ignore timestamps and compute checksums for files of equal size. This is fairly CPU-intensive and therefore limits the number of concurrent rsync operations each ConfigStore machine can serve. This in turn increases overall end-to-end propagation latency. Partitioning namespaces into separate repositories reduces the number of files that rsync needs to compare for each commit. A possible alternative is to run a Git server on each ConfigStore machine and have all destination machines run `git fetch`, which would simply download the latest ‘HEAD’ without any comparison overhead (because the Git server knows exactly what changed).
ConfigBus’ use of rsync means that files get synced to the destination machine individually. As a result, if a commit happens to change multiple files, it is possible that the filesystem on the destination machine transiently contains a mixture of old and new files. A potential workaround is to sync to a temporary location and then use an atomic rename operation to complete the change. However, this is complicated by the presence of symlinks at the deployment location due to the need to support partitioned namespaces in a backward compatible manner. A more feasible solution is to continue distributing the main Git repository as we do today, but switch to atomic deployments for future partitioned repositories.
We built ConfigBus to be a robust platform for dynamic configuration at Twitter. As existing use cases evolve and new uses cases emerge, ConfigBus has to change to accommodate them. In particular, these are our areas of focus:
Git has many advantages for end users, but it represents a constant operational challenge. We are open to questioning whether it remains the right solution going forward. Alternatives include key-value stores such as Consul, but then we’d have to solve the opposite problem of too little history.
The use of rsync for distribution from a small pool of ConfigStore machines limits the speed of the distribution pipeline. It would be interesting to explore a peer-to-peer distribution model where each machine acts as a source for further transfers once it has some or all of the data.
Currently, we discourage the use of ConfigBus for large blobs, mainly because of Git but also because storing large blobs on every single machine is inefficient. A potential solution is to store the blobs in a regular blob store and simply store the active version in ConfigBus and download them on demand.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.