Open source
Optimizing Twitter Heron
By
Thursday, 16 March 2017
We designed Twitter Heron, our next generation streaming engine, because we needed a system that scaled better, was easier to debug, had better performance, was easier to deploy and manage, and worked in a shared multi-tenant cluster environment. Heron has been in production at Twitter for more than two and a half years and has proven to deliver against our design criteria. We were so thrilled we open-sourced it in May 2016. While Heron immediately delivered on its promise of better scalability compared to Storm (as we reported in our SIGMOD 2015 paper), we’ve recently identified additional lower-level performance optimization opportunities. Since improvements in performance directly translate to efficiency, we identified the performance bottlenecks in the system and optimized them. In this blog we describe how we profiled Heron to identify performance limiting components, we highlight the optimizations, and we show how these optimizations improved throughput by 400-500% and reduced latency by 50-60%.
Before we can discuss our performance optimizations, let us revisit some of the core Heron concepts. A Heron topology consists of spouts and bolts. Spouts tap into a data source and inject data tuples into a stream, which is processed by a downstream topology of bolts. Bolts are processing elements that apply logic on incoming tuples and emit outgoing tuples. A Heron topology is an assembly of spouts and bolts that create a logical processing plan in the form of a directed acyclic graph. The logical plan is translated into a physical plan that includes the number of instances for each spout and bolt as well as the number of containers these instances should be deployed on.
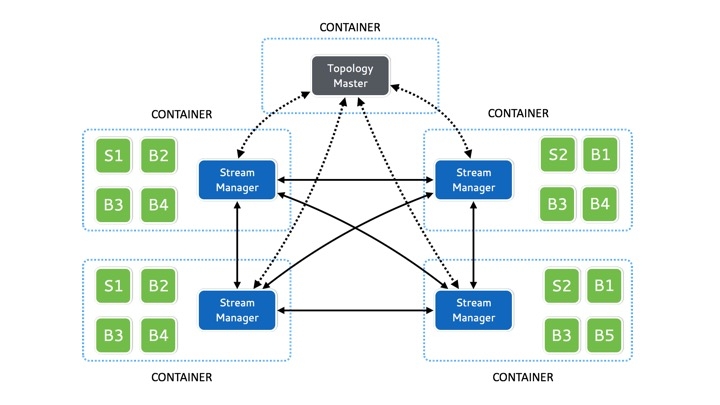
Heron provides parallelization by utilizing a process model, as opposed to a thread model used by most other streaming systems. Such a model provides isolation between different tasks or operators of a topology, which simplifies debugging and profiling. Heron runs each topology as a job on the underlying scheduler with the specified number of containers. The master container runs a process called the Topology Master which manages the entire topology. The remaining containers, each run a Stream Manager, and a number of processes called Heron Instances.
The Topology Master is responsible for resource allocation and serving metrics related with the topology. The Stream Manager in the container is responsible for routing tuples to other containers and to the instances in it’s container. Heron instances run the actual spout and bolt code. Intra-process tuple communication is done using Protocol Buffers. Heron currently integrates with several schedulers including Mesos/Aurora, Mesos/Marathon, SLURM and YARN/REEF. Figure 2 illustrates the physical realization of the topology shown in Figure 1.
Our motivation for optimizations were to reduce the cost and improve the overall performance of Heron. On investigation, we identified that improving the stream manager performance directly impacts the overall performance of the topology since it is in the path of all tuple communications.
We tested the performance using the Word Count Topology running locally on a single machine. To understand key bottlenecks in the stream manager, we used the Perf tool in CentOS. This tool gave us visibility into how much time was spent in each function call. Based on this, we identified the following key observations:
Furthermore, profiling provided a detailed breakdown on how much time was spent on those aspects that are as follows:
Based on these observations, we refactored the stream manager as follows and re-tested:
In order to see how these optimizations affect the overall throughput and latency, we did several experiments. We considered two variants of the Word Count topology, one with acknowledgements enabled (i.e., at least once semantics), and the other with no acknowledgements (i.e., at most once semantics). The spout tasks generates a set of ~175k random words during initialization. In each “nextTuple” call, each spout picks a word at random and emits it. Since spouts use fields grouping for their output, they send tuples to every other bolt in the topology. Bolts maintain a map in memory to count words.
All experiments were run on machines with dual Intel Xeon [email protected] CPUs, each consisting of 12 physical cores with hyper-threading enabled, 72GB of main memory, and 500GB of disk space. The experiments ran for several hours to attain steady state before measurements were taken. Table 1 describes the specifics for each of the experiments.
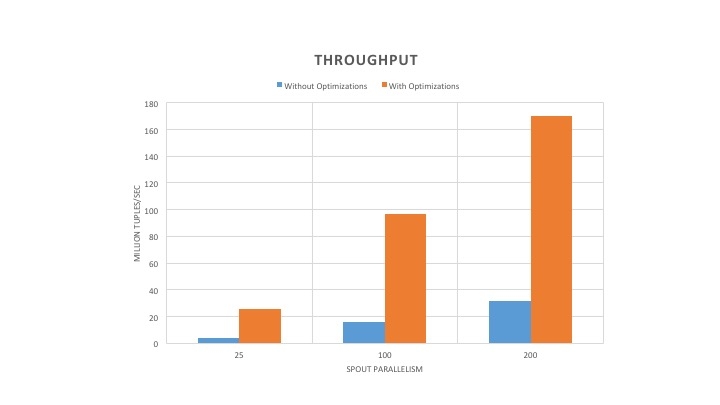
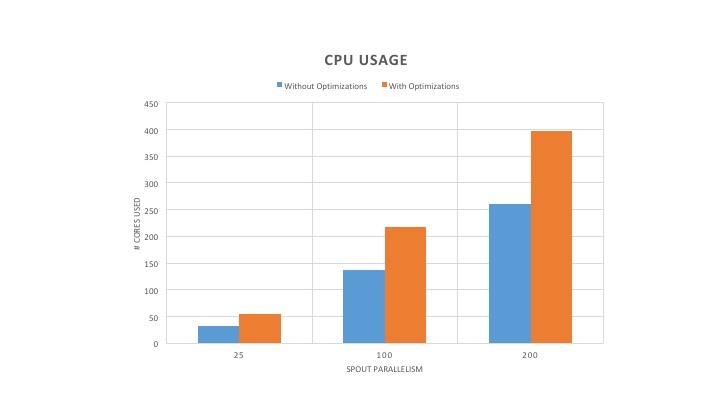
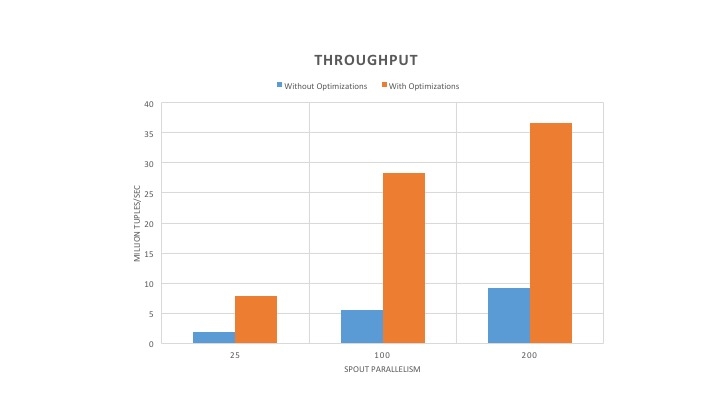
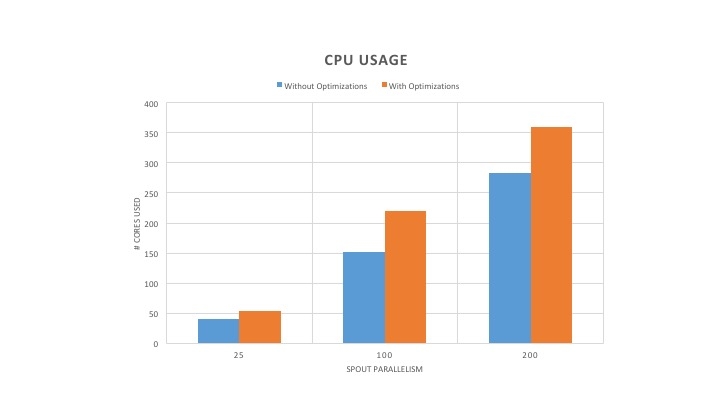
The performance numbers for throughput and CPU usage for Word Count topology without any acknowledgement is shown in Figure 3 and Figure 4. The throughput with optimized version of Heron increased by 5-6x compared to the unoptimized version of Heron. Furthermore, the throughput increased with the increase in spout parallelism. However, the optimized version of Heron used 1.5x more cores to realize the higher throughput.
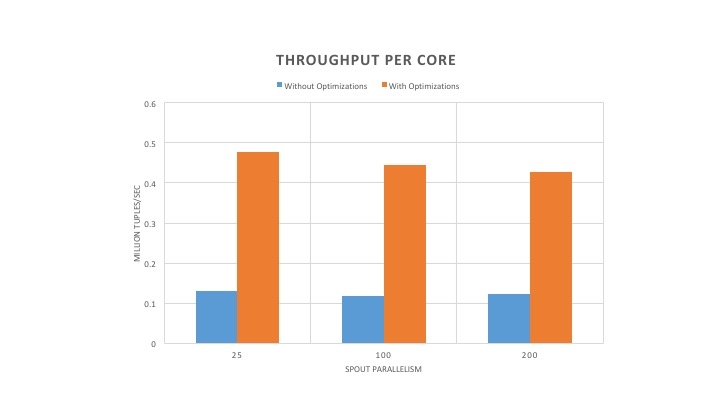
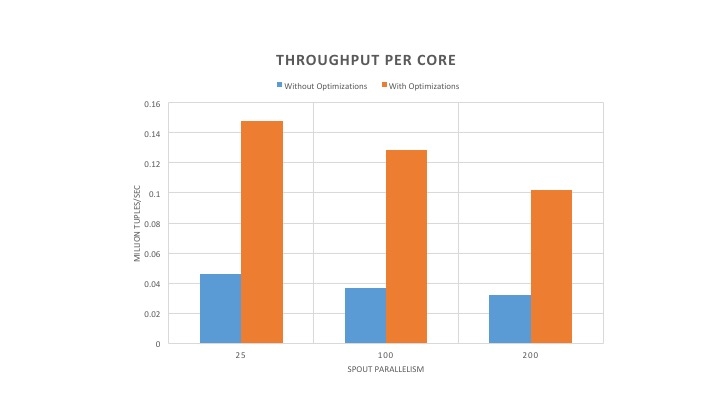
Even though the optimized version of Heron uses more cores, it utilizes each core more efficiently driving the throughput higher as shown in Figure 5. One can observe that the throughput per core is consistently 4-5X.
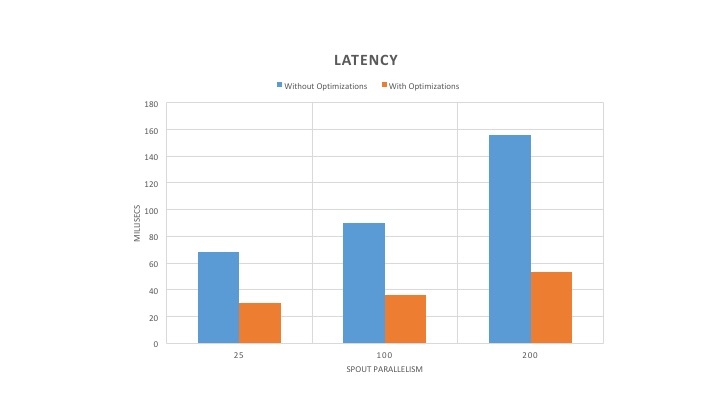
In this case, each tuple injected into the system is acknowledged once it is completely processed by the downstream components. Acknowledgements flow in the opposite direction to the data or tuple flow. Results of throughput and latency experiments are shown in Figure 6 and Figure 7. Note that the latency reported includes the total time taken by the tuple and its derivatives to be processed and for the propagation of acknowledgements back to the spout.
As can be seen in Figure 6, the throughput of the optimized version of Heron has increased by 4-5X. Furthermore, the throughput also increased with the increase in spout parallelism. In addition, the latency decreased by 50% or more as observed in Figure 7. Since the stream manager performance increased after the optimizations, the Heron instances have to do more work to keep it saturated, which increases the CPU usage as shown in Figure 8. However, the CPU increase ranges from only 25% to 45%. To further understand the increase in core usage, we plotted the throughput per core shown in Figure 8. As can be seen, the throughput per core increased by 3-4X. This shows that cores are more efficiently utilized despite the increase in core usage.
Conclusion
To summarize, serialization/deserialization were observed as the limiting factors for stream manager throughput. Using simple lower level optimizations for protobuf messages such as preallocation of a memory pool, in place updates and lazy deserialization, we were able to improve Heron throughput and latency. These optimizations allowed us to more efficiently allocate and utilize our resources in a multi-tenant cluster.
Thanks to Maosong Fu and Cong Wang who were the primary driving force for identifying the optimizations, implementing them and evaluating the performance and special thanks to Sasa Gargenta and Bill Graham for their feedback as we drafted this content.
[1] Streaming@Twitter, Bulletin of the Technical Committee on Data Engineering, IEEE Computer Society, December 2015.
[2] Twitter Heron: Streaming at Scale, Proceedings of ACM SIGMOD Conference, Melbourne, Australia, June 2015.
[3] Storm@Twitter, Proceedings of ACM SIGMOD Conference, Snowbird, Utah, June 2014.
[4] Flying Faster with Heron - Twitter Engineering Blog, May 2015.
[5] Open Sourcing Twitter Heron - Twitter Engineering Blog, May 2016
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.