Insights
Model-based candidate generation for account recommendations
By
Thursday, 20 January 2022
People come to Twitter with the intention of staying informed on what’s happening within their world of interests. Account recommendations (also known as Who-To-Follow) is a critical piece that helps people connect with accounts relevant to their personalized interests.
Behind this product is a two-stage recommendation pipeline, similar to the standard practice for machine learning-driven recommendations in the industry. It begins with candidate generation, where a set of highly relevant candidates are retrieved (in the hundreds to thousands), followed by a ranking phase where this set is ranked, in real-time, by a machine learning model to produce the final set of recommendations (single to tens).
In the past decade, we have developed dozens of candidate sources to find potentially relevant accounts that match people’s interests. However, each candidate source is typically based on a narrow slice of customer information. It applies algorithms like collaborative filtering or graph expansion to find candidates based on these particular signals. The lack of a holistic view of people’s interests results in candidate recommendations that are less personalized.
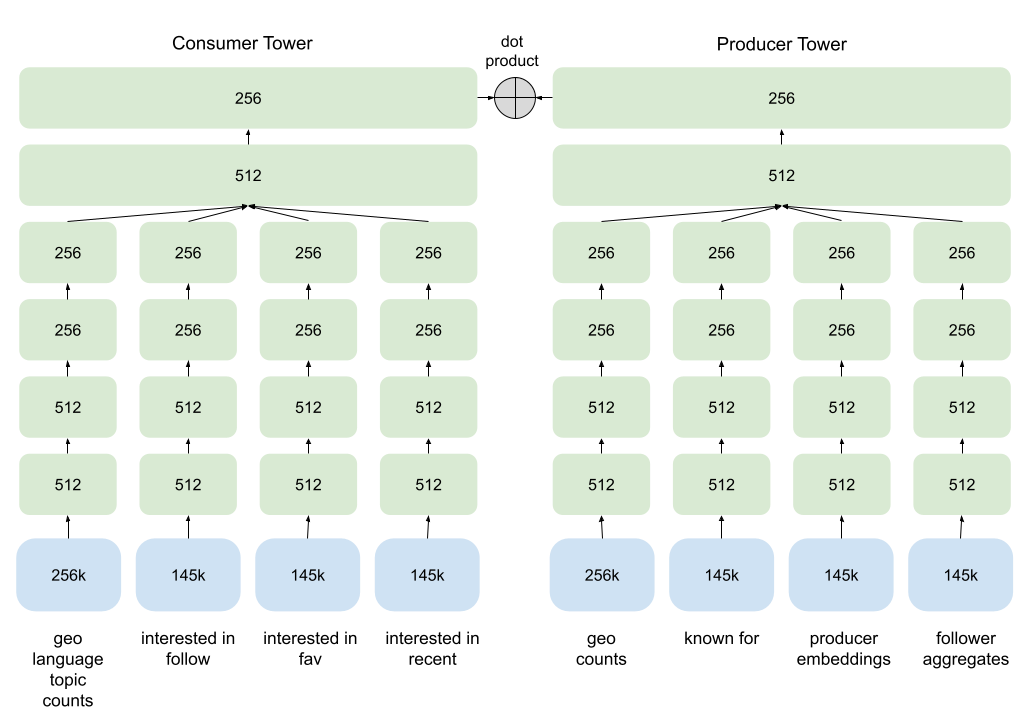
The solution to improving the personalization of our candidate generation pipelines is to use a model-based framework where we are able to add additional features (such as embedding features) to enhance the relevance of the recommendations. We decided on a two-tower model, with one tower focused on generating an embedding that reflects consumption behaviors, while the other focused on generating an embedding that reflects production behaviors.
We use the dot product of the output embeddings as a proxy for the logit of the probability that a given consumer-producer pair will be followed, using the actual follow relationship on our platform as the ground truth for the model during training. During inference time, we can:
Input a given requesting account’s consumer features
Calculate the consumer embedding
Then find the k-nearest producer embeddings within the embedding space to be used as recommendations.
With this framework, we can add in personalized features to the consumer tower to better infer a given customer’s interests. We can also add in graph-based features to our producer tower that describe their aggregate audience characteristics. By combining all of the available input signals in a single model, we allow our model to learn interactions between features, which was previously impossible.
The key benefits of the framework are:
Better relevance as a result of unifying multiple signals under a single framework-pipeline. Online experiments showed that the proposed solution increased global engagement on our product and helped new Twitter customers enhance their follow graph at the critical early stages of their journey.
Retirement of older heuristics.
Maintaining a single pipeline, reducing maintenance overhead in the long run.
Paving the way for faster, future iterations when exploring new signals. New signals can easily be added directly to our model as features rather than having to develop whole pipelines.
We could not have done this without the help from our product partners, teammates, and reviewers. Thank you to all involved!
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.