Insights
ICLR Invited Talk on Geometric Deep Learning
By
Tuesday, 4 May 2021
This blog post is based on Michael Bronstein’s keynote talk at ICLR 2021 and the paper M. M. Bronstein, J. Bruna, T. Cohen, and P. Veličković, Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges (2021), arXiv:2104.13478.
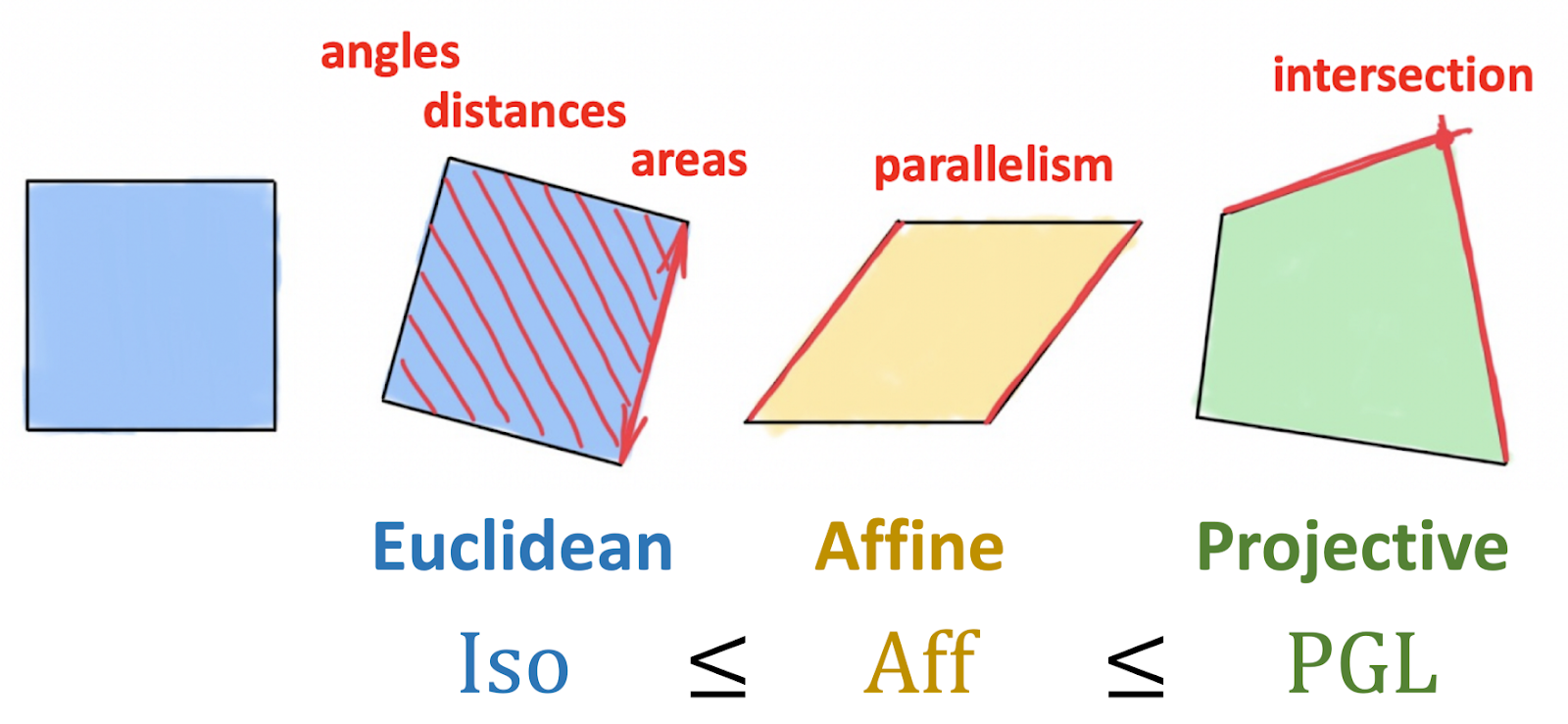
In October 1872, the philosophy faculty of a small university in the Bavarian city of Erlangen appointed a new young professor. As customary, he was requested to deliver an inaugural research program, which he published under the somewhat long and boring title Vergleichende Betrachtungen über neuere geometrische Forschungen (“A comparative review of recent researches in geometry”). The professor was Felix Klein, only 23 years of age at that time, and his inaugural work has entered the annals of mathematics as the “Erlangen Program”.¹
The nineteenth century had been remarkably fruitful for geometry. For the first time in nearly two thousand years after Euclid, the construction of projective geometry by Poncelet, hyperbolic geometry by Gauss, Bolyai, and Lobachevsky, and elliptic geometry by Riemann showed that many types of geometries were possible. However, these constructions had quickly diverged into independent and unrelated fields, with many mathematicians of that period questioning how the different geometries are related to each other and what actually defines a geometry.
The breakthrough insight of Klein was to approach the definition of geometry as the study of invariants, or in other words, structures that are preserved under a certain type of transformations (symmetries). Klein used the formalism of group theory to define such transformations and use the hierarchy of groups and their subgroups to classify different geometries arising from them. For example, the group of rigid motions leads to the traditional Euclidean geometry, while affine or projective transformations produce, respectively, the affine and projective geometries. Importantly, the Erlangen Program was limited to homogeneous spaces² and initially excluded Riemannian geometry.
The impact of the Erlangen Program on geometry and mathematics broadly was very profound. It also spilled to other fields, especially physics. Symmetry considerations allowed to derive conservation laws from the first principles — an astonishing result known as Noether’s Theorem.³ It took several decades until this fundamental principle proved successful in unifying all the fundamental forces of nature with the exception of gravity.⁴ This is called the Standard Model and it describes all the physics we currently know. We can only repeat the words of a Nobel-winning physicist, Philip Anderson,⁵ that “it is only slightly overstating the case to say that physics is the study of symmetry.’’
We believe that the current state of affairs in the field of deep learning is reminiscent of the situation of geometry in the nineteenth century. On the one hand, in the past decade, deep learning has brought a revolution in data science and made possible many tasks previously thought to be beyond reach — whether computer vision, speech recognition, natural language translation, or playing Go. On the other hand, we now have many different neural network architectures for different kinds of data, but few unifying principles. As a consequence, it is difficult to understand the relations between different methods, which inevitably leads to the reinvention and re-branding of the same concepts.
Geometric Deep Learning is an umbrella term introduced in our paper⁶ referring to recent attempts to come up with a geometric unification of ML similar to Klein’s Erlangen Program. It serves two purposes: first, to provide a common mathematical framework to derive the most successful neural network architectures, and second, give a constructive procedure to build future architectures in a principled way.
Supervised machine learning in its simplest setting is essentially a function estimation problem. Given the outputs of some unknown function on a training set (for example, labelled dog and cat images), one tries to find a function f from some hypothesis class that fits the training data well and allows prediction of the outputs on previously unseen inputs. In the past decade, the availability of large, high-quality datasets such as ImageNet have coincided with growing computational resources (GPUs), allowing the design of rich function classes that have the capacity to interpolate such large datasets.
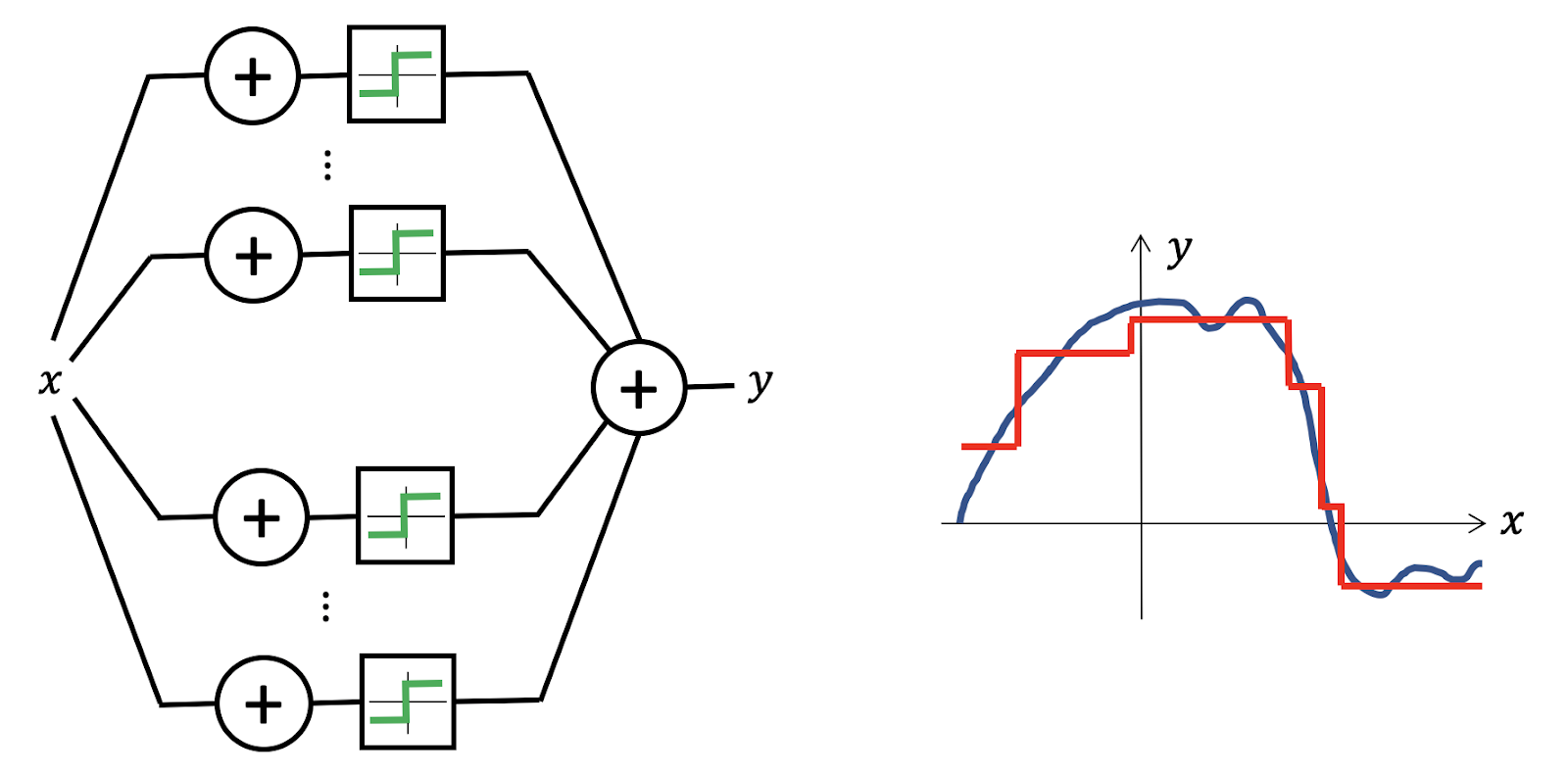
Neural networks are a suitable choice for representing functions, because even the simplest architecture, like the perceptron, can produce a dense class of functions when using just two layers, allowing for the approximation of any continuous function to any desired accuracy. This property is known as Universal Approximation.⁷
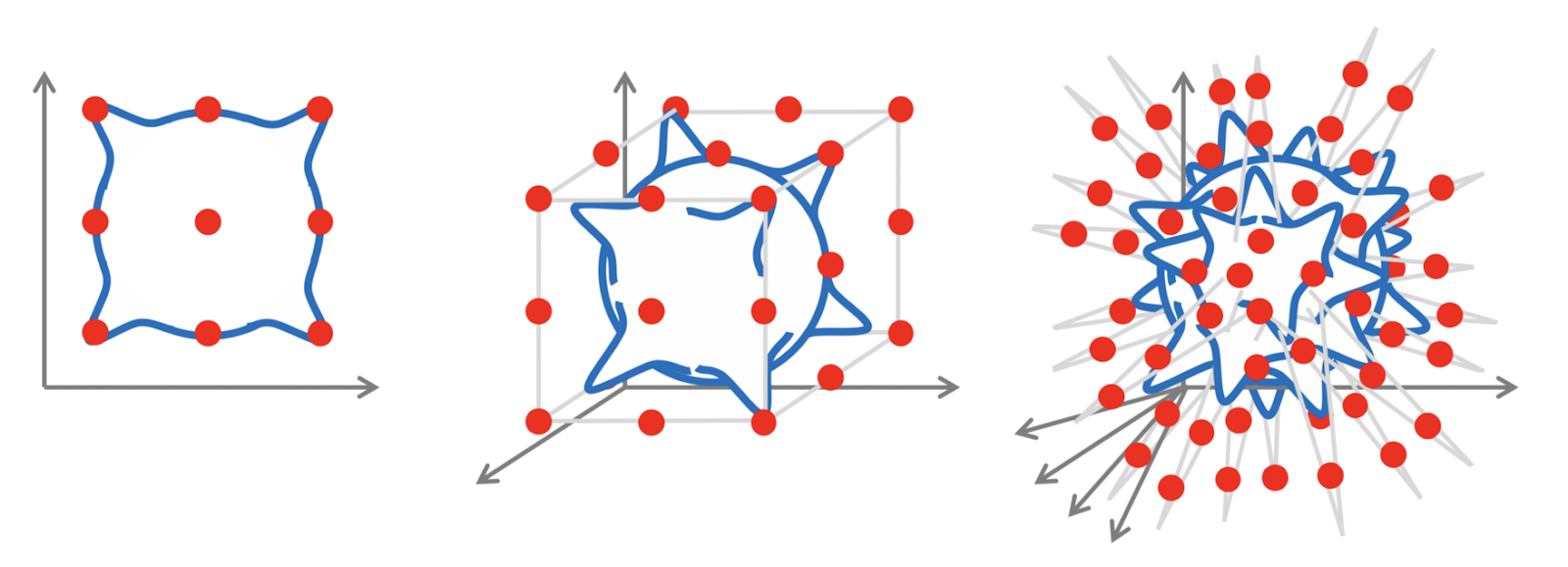
The setting of this problem in low-dimensions is a classical problem in approximation theory that has been studied extensively, with precise mathematical control of estimation errors. But the situation is entirely different in high dimensions. One can quickly see that to approximate even a simple class of, for example, Lipschitz continuous functions the number of samples grows exponentially with the dimension. This phenomenon is known colloquially as the “curse of dimensionality”. Since modern machine learning methods need to operate with data in thousands or even millions of dimensions, the curse of dimensionality is always there behind the scenes making such a naive approach to learning impossible.
This is perhaps best seen in computer vision problems like image classification. Even tiny images tend to be very high-dimensional (with d = number of pixels × number of color channels), but they have a lot of structure that is broken and thrown away when one parses the image into a vector to feed it into the perceptron. If the image is shifted by just one pixel, the vectorised input will be very different, and the neural network will need to be shown a lot of examples to learn that shifted inputs must be classified in the same way.⁸
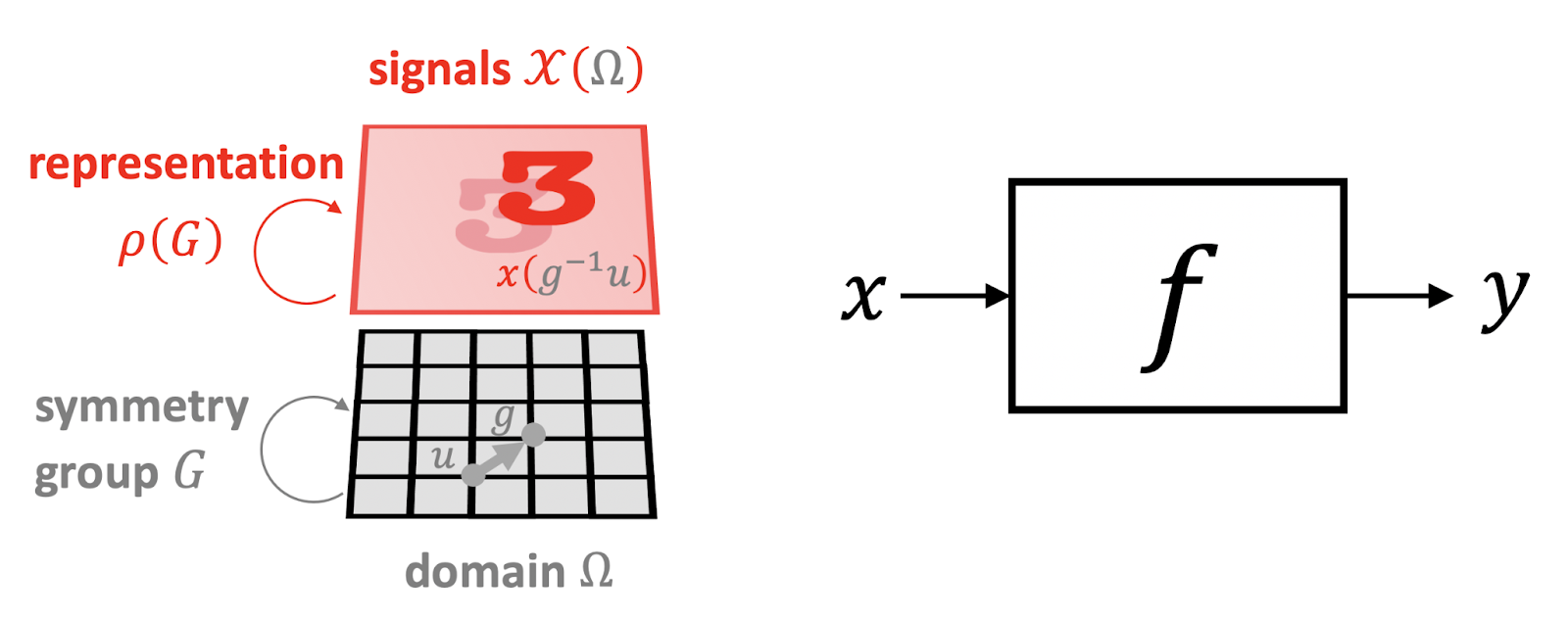
Fortunately, in many cases of high-dimensional ML problems we have an additional structure that comes from the geometry of the input signal. We call this structure a “symmetry prior” and it is a powerful principle that gives us optimism in dimensionality-cursed problems. In our example of image classification, the input image x is not just a d-dimensional vector, but a signal defined on some domain Ω, which in this case is a two-dimensional grid. The structure of the domain is captured by a symmetry group G — the group of 2D translations in our example — which acts on the points on the domain. In the space of signals, the group actions (elements of the group, g∈G) on the underlying domain are manifested through what is called the group representation ρ(g) — in our case, it is simply the shift operator, a d×d matrix that acts on a d-dimensional vector.⁹
The geometric structure of the domain underlying the input signal imposes structure on the class of functions f that we are trying to learn. One can have invariant functions that are unaffected by the action of the group:
f(ρ(g)x)=f(x) for any g∈G and x
On the other hand, one may have a case where the function has the same input and output structure and is transformed in the same way as the input—such functions are called equivariant and satisfy:¹⁰
f(ρ(g)x)=ρ(g)f(x)
In the realm of computer vision, image classification is a good illustration of a setting where one would desire an invariant function (for example, no matter where a cat is located in the image, we still want to classify it as a cat). While image segmentation, where the output is a pixel-wise label mask, is an example of an equivariant function (the segmentation mask should follow the transformation of the input image).
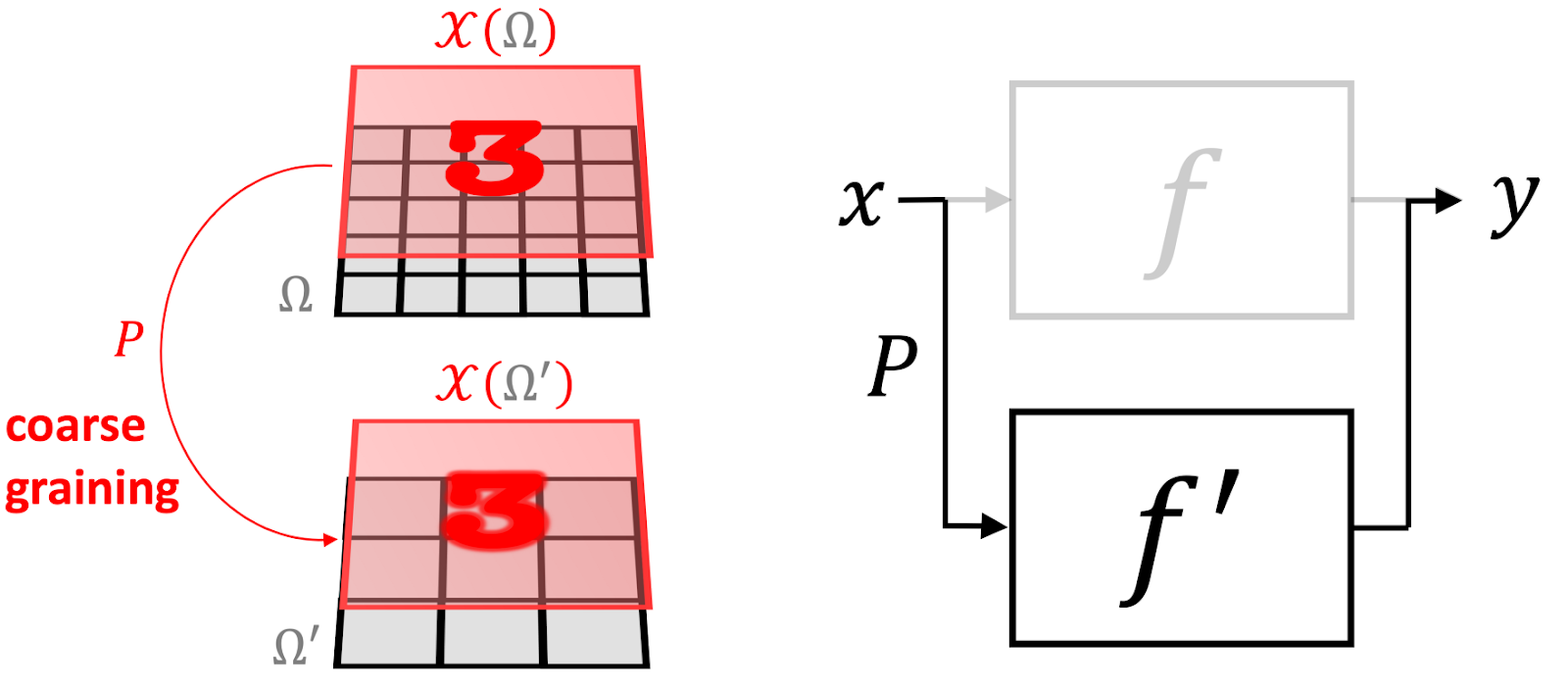
Another powerful geometric prior is “scale separation”. In some cases, we can construct a multiscale hierarchy of domains by “assimilating” nearby points and producing a hierarchy of signal spaces that are related by a coarse-graining operator P. On these coarse scales, we can apply coarse-scale functions. We say that a function f is locally stable if it can be approximated as the composition of the coarse-graining operator P and the coarse-scale function, f≈f’∘P. While f might depend on long-range dependencies, if it is locally stable, these can be separated into local interactions that are then propagated towards the coarse scales.¹¹
These two principles give us a very general blueprint of Geometric Deep Learning that can be recognised in the majority of popular deep neural architectures used for representation learning. A typical design consists of a sequence of equivariant layers (for example, convolutional layers in CNNs), possibly followed by an invariant global pooling layer aggregating everything into a single output. In some cases, it is also possible to create a hierarchy of domains by some coarsening procedure that takes the form of local pooling.
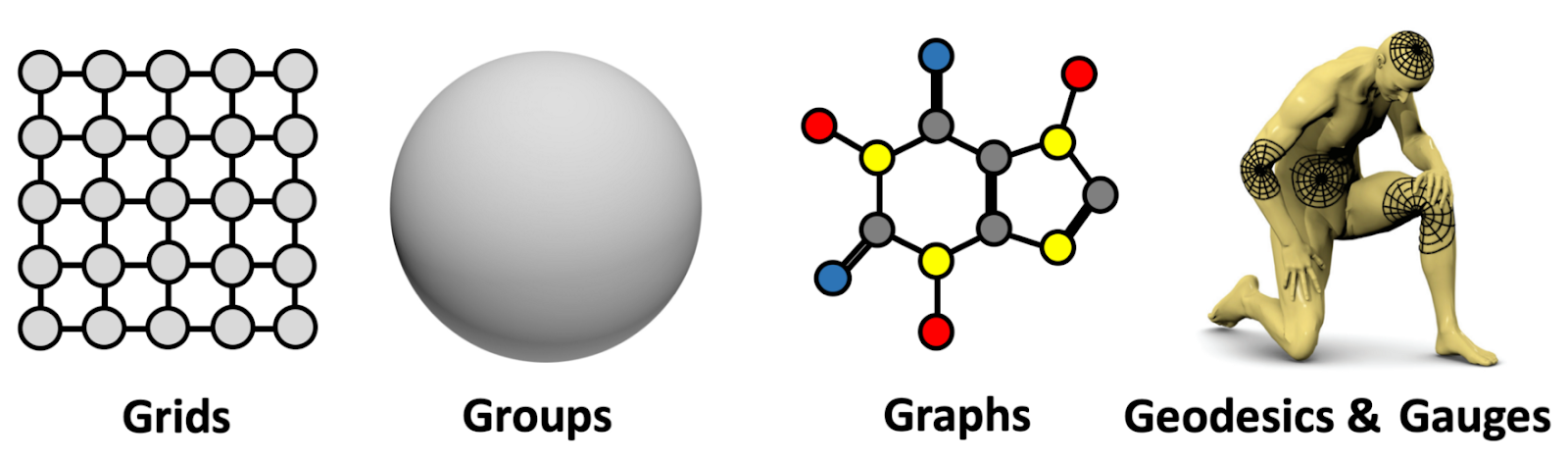
This is a very general design that can be applied to different types of geometric structures, such as:
The implementation of these principles leads to some of the most popular architectures that exist today in deep learning:
As a final note, we should emphasize that symmetry has historically been a key concept in many fields of science, of which physics, as already mentioned in the beginning, is key. In the machine learning community, the importance of symmetry has long been recognized in particular in the applications to pattern recognition and computer vision, with early works on equivariant feature detection dating back to Shun’ichi Amari¹⁶ and Reiner Lenz.¹⁷ In the neural networks literature, the Group Invariance Theorem for Perceptrons by Marvin Minsky and Seymour Papert¹⁸ put fundamental limitations on the capabilities of (single-layer) perceptrons to learn invariants. This was one of the primary motivations for studying multi-layer architectures,¹⁹⁻²⁰ which had ultimately led to deep learning.
¹ According to a popular belief repeated in many sources, the Erlangen Program was delivered in Klein’s inaugural address in October 1872. Klein indeed gave such a talk (though on December 7, 1872), but it was for a non-mathematical audience and concerned primarily his ideas of mathematical education. What is now called the “Erlangen Program” was actually the aforementioned brochure Vergleichende Betrachtungen, subtitled Programm zum Eintritt in die philosophische Fakultät und den Senat der k. Friedrich-Alexanders-Universität zu Erlangen (“Program for entry into the Philosophical Faculty and the Senate of the Emperor Friedrich-Alexander University of Erlangen”, see an English translation). While Erlangen claims the credit, Klein stayed there for only three years, moving in 1875 to the Technical University of Munich (then called Technische Hochschule), followed by Leipzig (1880), and finally settling down in Göttingen from 1886 until his retirement. See R. Tobies Felix Klein — Mathematician, Academic Organizer, Educational Reformer (2019) In: H. G. Weigand et al. (eds) The Legacy of Felix Klein, Springer.
² A homogeneous space is a space where “all points are the same” and any point can be transformed into another by means of group action. This is the case for all geometries proposed before Riemann, including Euclidean, affine, and projective, as well as the first non-Euclidean geometries on spaces of constant curvature such as the sphere or hyperbolic space. It took substantial effort and nearly fifty years, notably by Élie Cartan and the French geometry school, to extend Klein’s ideas to manifolds.
³ Klein probably anticipated the potential of his ideas in physics, complaining of “how persistently the mathematical physicist disregards the advantages afforded him in many cases by only a moderate cultivation of the projective view”. By that time, it was already common to think of physical systems through the perspective of the calculus of variation, deriving the differential equations governing such systems from the “least action principle”, that is, the minimizer of some functional (action). In a paper published in 1918, Emmy Noether showed that every (differentiable) symmetry of the action of a physical system has a corresponding conservation law. This, by all means, was a stunning result. Beforehand, meticulous experimental observation was required to discover fundamental laws such as the conservation of energy, and even then, it was an empirical result not coming from anywhere. For historical notes, see C. Quigg, Colloquium: A Century of Noether’s Theorem (2019), arXiv:1902.01989.
⁴ Through the notion of gauge invariance (in its generalised form developed by Yang and Mills in 1954.
⁵ P. W. Anderson, More is different (1972), Science 177(4047):393–396.
⁶ M. M. Bronstein et al. Geometric deep learning: going beyond Euclidean data (2017), IEEE Signal Processing Magazine 34(4):18–42 attempted to unify learning on grids, graphs, and manifolds from the spectral analysis perspective. The term “geometric deep learning” was actually coined earlier, in Bronstein’s ERC grant.
⁷ There are multiple versions of the Universal Approximation theorem. It is usually credited to G. Cybenko, Approximation by superpositions of a sigmoidal function (1989) Mathematics of Control, Signals, and Systems 2(4):303–314 and K. Hornik, Approximation capabilities of multilayer feedforward networks (1991), Neural Networks 4(2):251–257.
⁸ The remedy for this problem in computer vision came from classical works in neuroscience by Hubel and Wiesel, the winners of the Nobel prize in medicine for the study of the visual cortex. They showed that brain neurons are organised into local receptive fields, which served as an inspiration for a new class of neural architectures with local shared weights: first, the Neocognitron in K. Fukushima, A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position (1980), Biological Cybernetics 36(4):193–202, and then the Convolutional Neural Networks, the seminar work of Y. LeCun et al., Gradient-based learning applied to document recognition (1998), Proc. IEEE 86(11):2278–2324, where weight sharing across the image effectively solved the curse of dimensionality.
⁹ Note that a group is defined as an abstract object, without saying what the group elements are ( for example, transformations of some domain), only how they compose. Hence, very different kinds of objects may have the same symmetry group.
¹⁰ These results can be generalized for the case of approximately invariant and equivariant functions, see e.g. J. Bruna and S. Mallat, Invariant scattering convolution networks (2013), PAMI 35(8):1872–1886.
¹¹ Scale separation is a powerful principle exploited in physics, for example, in the Fast Multipole Method (FMM), a numerical technique originally developed to speed up the calculation of long-ranged forces in n-body problems.
¹² M. Zaheer et al., Deep Sets (2017), NIPS. In the computer graphics community, a similar architecture was proposed in C. R. Qi et al., PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation (2017), CVPR.
¹³ A. Vaswani et al., Attention is all you need (2017), NIPS, introduced the now popular Transformer architecture. It can be considered as a graph neural network with a complete graph.
¹⁴ C. Tallec and Y. Ollivier, Can recurrent neural networks warp time? (2018), arXiv:1804.11188.
¹⁵ J. Masci et al., Geodesic convolutional neural networks on Riemannian manifolds (2015), arXiv:1501.06297 was the first convolutional-like neural network architecture with filters applied in local coordinate charts on meshes. It is a particular case of T. Cohen et al., Gauge Equivariant Convolutional Networks and the Icosahedral CNN (2019), arXiv:1902.04615.
¹⁶ S.-l. Amari, Feature spaces which admit and detect invariant signal transformations (1978), Joint Conf. Pattern Recognition. Amari is also famous as the pioneer of the field of information geometry, which studies statistical manifolds of probability distributions using tools of differential geometry.
¹⁷ R. Lenz, Group theoretical methods in image processing (1990), Springer.
¹⁸ M. Minsky and S. A Papert, Perceptrons: An introduction to computational geometry (1987), MIT Press. This is the second edition of the (in)famous book blamed for the first “AI winter”, which includes additional results and responds to some of the criticisms of the earlier 1969 version.
¹⁹ T. J. Sejnowski, P. K. Kienker, and G. E. Hinton, Learning symmetry groups with hidden units: Beyond the perceptron (1986), Physica D:Nonlinear Phenomena 22(1–3):260–275
²⁰ J. Shawe-Taylor, Building symmetries into feedforward networks (1989), ICANN. The first work that can probably be credited with taking a representation-theoretical view on invariant and equivariant neural networks is J. Wood and J. Shawe-Taylor, Representation theory and invariant neural networks (1996), Discrete Applied Mathematics 69(1–2):33–60.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.