Insights
Fusing Elasticsearch with neural networks to identify data
By
and
Friday, 30 April 2021
Microservice-based companies distribute accountability for data privacy throughout an organization. Tracing and accounting for personal data is challenging when it is distributed across the numerous datasets and storage systems of an organization. Twitter has a large number of datasets spread across teams and storage platforms, and all these datasets must adhere to evolving privacy and data governance policies. Given Twitter’s commitment to privacy, we must always understand what data exists in our systems, its sensitivity, and its permitted purpose of use. Not only does such an understanding of data drive Twitter’s privacy efforts, but it also lets us optimize for storage, discover new usage patterns, improve data security, and optimize data handling.
One solution is to consistently follow a standardized taxonomy when naming the columns, keys, or fields of a dataset’s schema. Though this seems trivial, this is challenging when there is a vast number of existing legacy datasets that aren’t annotated via the selected standardized taxonomy. Changing schemas in existing datasets often results in heavy refactoring across the consumers and producers of data. That is to say, every service that produces data has to be rewritten to adhere to the new format. In addition, every consuming service or monitoring tool has to be reviewed to be sure that queries are using the new format. Given the scale at which Twitter operates, this would have been a long, painful, and error-prone process.
Another solution is to annotate, or “tag”, the columns with names chosen from a standardized taxonomy. The annotation could be done in the background with minimal refactoring and no downtime to existing tools and services. Because of these benefits, we decided to annotate the columns for the datasets over changing the actual column names for the datasets.
The article describes how Twitter annotated its data to a defined taxonomy by leveraging machine learning in its data platform. We call this the Annotation Recommendation Service.
Twitter introduced a data taxonomy by letting engineers and product managers annotate their data manually over a period of time. As a result, the unwieldy data taxonomy informs much of the internal data. At the time of writing, the taxonomy has 504 possible annotations. Twitter systems have more than 2 million columns spread across ~100K primary and derived datasets. Each of these columns had to be mapped against these 504 annotations.
We needed an automated way to find annotations for the data to support development velocity and quality of annotations. We developed the Annotation Recommendation Service, which leverages machine learning to predict the annotations for the data based on dataset metadata.
Example annotations:
Here the dataset profile has a column id that is annotated with UserId.
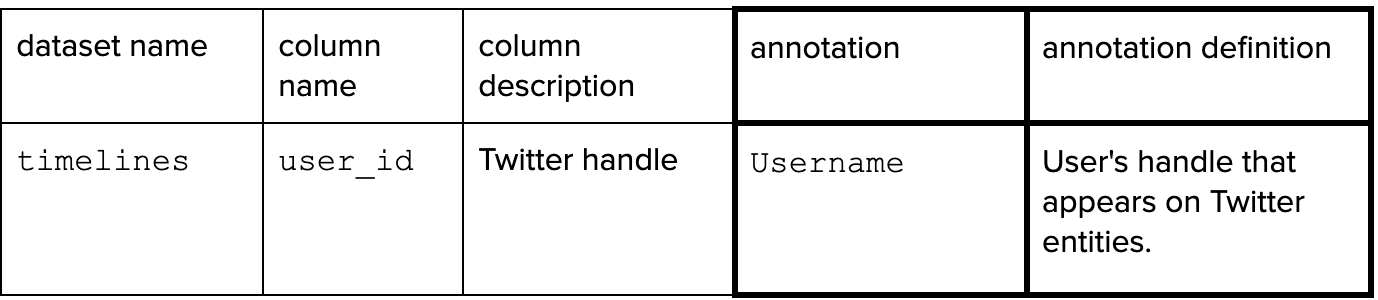
Here the dataset timelines has a column user_id that is annotated with Username.
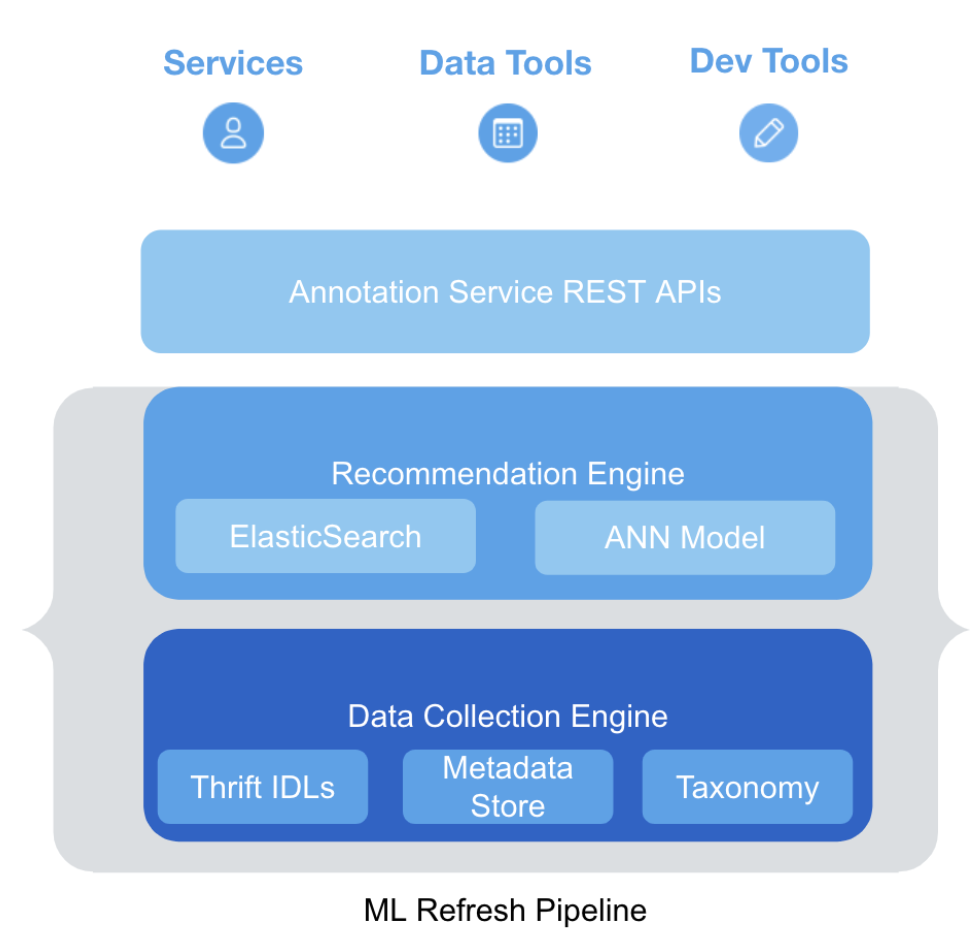
The architecture of the Annotation Recommendation Service (see Fig. 1) consists of the following components:
Below, we discuss the Recommendation Engine in more detail, since that forms the core of the service.
We let engineers and product managers annotate their data manually for several months, which resulted in labeled data of annotated columns across datasets and storages. A set of regularly scheduled jobs scrapes this annotation information from Twitter’s storage metadata.
This manually-labeled data acts as a training corpus to automatically predict annotations for other datasets. The labeled mapping of dataset column names and the annotations are augmented with other dataset metadata, which results in a text-based feature vector with the format [Dataset Name, Column Name, Column Description, Annotation Name, Owner Team].
We started with a training corpus of ~70K records. That dataset was large enough to frame the annotation problem into a pattern matching, or a machine learning problem. A query to search for an annotation for an unannotated column is in the format [Dataset Name, Column Name, Column Description]and the output is a set of recommended annotations for the column.
We formulated the annotation recommendation problem into a full-text search problem and converted our corpus into inverted search indexes. Once we had a full-text search problem, we were able to leverage existing solutions. We chose Elasticsearch as our search engine, as it is easy to scale, has fast performance, and is already used internally.
We preprocessed the data using standard techniques and turned the data into documents for Elasticsearch by concatenating the metadata for columns with the same annotations. For example, a document given to Elasticsearch is:
Our recommendation engine tries to predict the target on the right from the text-based features on the left.
For each prediction of annotations for a column, we do multiple variations of the Elasticsearch queries with a combination of and, or over different text-based features. Then to combine the results of these queries, we use a calibration model that provides the weights for combining these query results into a final result.
To train the calibration model, we held out 20% of the training corpus as a held-out set and used the held-out set to query Elasticsearch using [Dataset Name, Column Name, Column Description]. Elasticsearch returns scores based on Lucene's practical scoring function, TF IDF similarity. These Elasticsearch result scores become a numeric feature vector of 504 dimensions (R504) for the calibration model. We experimented with different multi-classification models and decided to use an artificial neural net model.
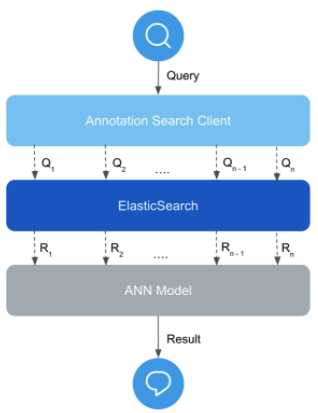
The figure below summarizes the Recommendation Engine.
A query to Annotation Search Client is divided into n queries and is queried against the Elasticsearch index. These n query results in n sets of recommendations act as numeric feature vectors to the calibration model, which outputs the final set of recommendations. The neural network uses weight sharing across the results of all queries for calibration. In effect, it is a 1D convolutional network.
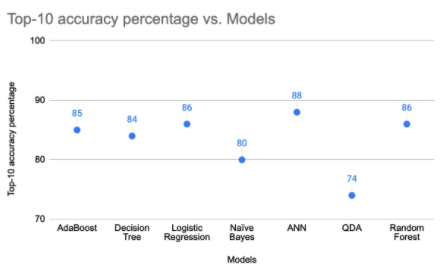
The following graph shows benchmarking results for the Elasticsearch index with different calibration models:
Based on the above results, we decided to go with the Elasticsearch with a neural network calibration model for our recommendation engine.
Using ML models and dataset metadata/schemas we developed a recommendation engine to annotate legacy datasets at Twitter to a new standardized taxonomy. Integrating development tools with the Annotation Recommendation Service improved engineering efficiency and annotation quality. Of the datasets that have been annotated since the recommendation service launch, 73.8% use the recommendations directly from the service.
The recommendation service also facilitates the development of tools for data discovery and data auditing and handling. The data discovery tools let us optimize storage and discover new usage patterns. The auditing and handling tools help to understand the sensitivity of the accessed data, which allows teams to align data permissions based on sensitivity and help overall data privacy and security in the company.
While developing the annotation recommendation service we learned that, while applying state-of-the-art deep learning techniques can be impactful, applying simpler techniques in the right context can prove to be more beneficial than one often expects.
The Annotation Recommendation Service and its integrations into internal tools were built by Alex Makaranka, Amaresh Bingumalla, Arash Aghevli, Chie Inada, Krishna Prasad, Neha Mittal, Rakshit Wadhwa, Ryan Turner, Viknes Balasubramanee, Vivek Joshi and the broader Data Platform and Cortex teams. We would also like to thank David Marwick, Fabio Rojas, Kim Norlen, Mai Do, Nitin Singhal, Ravi Kiran Meka, and Tamara Reyda for their support and guidance.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.