Insights
Graph ML at Twitter
By
Wednesday, 2 September 2020
Deep learning on graphs — also known as Geometric deep learning (GDL)¹, Graph representation learning (GRL), or relational inductive biases² — has recently become one of the hottest topics in machine learning. While early works on graph learning go back at least a decade³, if not two⁴, it is undoubtedly the past few years’ progress that has taken these methods from a niche interest into the spotlight of the ML community, complete with dedicated workshops attracting large crowds.
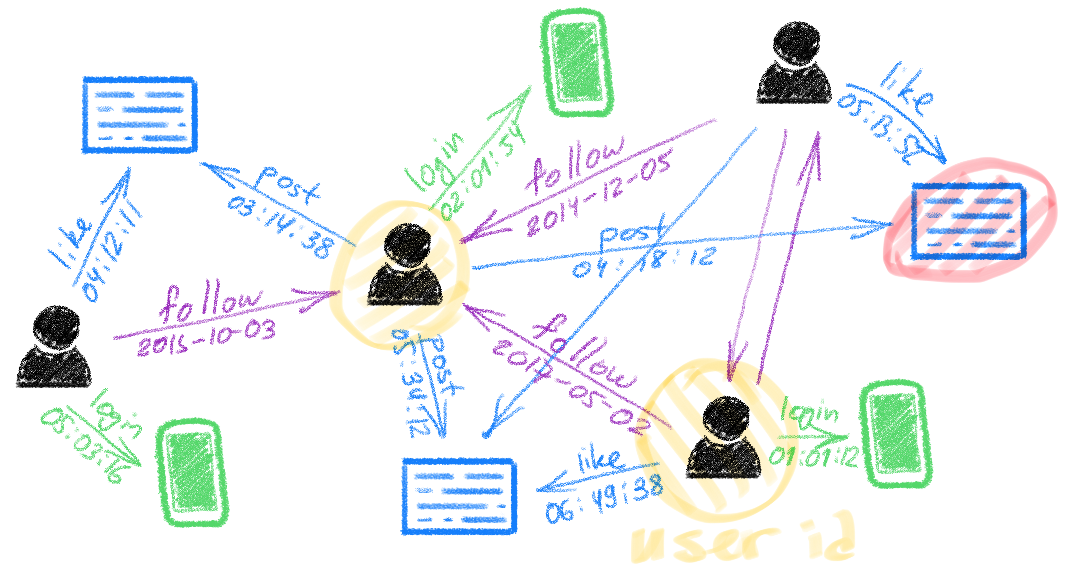
Graphs are mathematical abstractions of complex systems of relations and interactions. A graph represents a network of objects (called nodes or vertices) with pairwise connections (edges). Graphs are ubiquitously used in fields as diverse as biology⁵ ⁶ ⁷, quantum chemistry⁸, and high-energy physics⁹. Social networks like Twitter are examples of very large-scale complex graphs where the nodes model users and Tweets, while the edges model interactions such as replies, Retweets, or favs. Public conversations happening on our platform typically generate hundreds of millions of Tweets and Retweets every day. This makes Twitter perhaps one of the largest producers of graph-structured data in the world, second perhaps only to the Large Hadron Collider.
Conventional deep learning techniques have been remarkably successful in data-rich settings and are in wide use at Twitter. However, applying deep learning to graphs requires rethinking the very basic building blocks of neural network architectures. Similarly to convolutional neural networks used in image analysis and computer vision, the key to efficient learning on graphs is to design local operations (with shared weights) that amount to message passing between every node and its neighbours. A major difference compared to classical deep neural networks, which deal with grid-structured data, is that on graphs such operations are permutation-invariant, i.e. independent of the order of neighbour nodes, as there is typically no canonical way of ordering them.
There are multiple settings of graph learning problems that are largely application-dependent. One dichotomy is between node-wise and graph-wise problems, in which the former one tries to predict properties of individual nodes in the graph (e.g. identify malicious users in a social network), while in the latter one tries to make a prediction about the entire graph. Furthermore, like in traditional ML problems, we can distinguish between supervised and unsupervised (or self-supervised) settings, as well as transductive and inductive problems. Like in traditional deep learning architectures, graph neural networks have basic building blocks that can be combined together into architectures that are designed for and trained on a specific problem at hand.
Our team at Twitter is conducting research on graph ML that progresses the state-of-the-art in the field, while addressing the unique needs and applications of our platform. Below, some of the central topics on our research agenda, which we will be covering in a series of follow-up blog posts.
Standardized benchmarks like ImageNet were surely one of the key success factors of deep learning in computer vision, with some¹⁰ even arguing that data was more important than algorithms for the deep learning revolution. We have nothing similar to ImageNet in scale and complexity in the graph learning community yet. The Open Graph Benchmark launched in 2019 is a first research community effort toward this goal. Members of our team are part of the steering committee of this initiative. Furthermore, in 2020 we sponsored the RecSys Challenge and provided one of the largest datasets in the industry: 160 million Tweets with corresponding user engagement graphs.
Scalability is one of the key factors limiting the broad industrial applications of graph neural networks so far. At Twitter, we deal with very large graphs that often contain hundreds of millions of nodes and billions of edges. On top of that, some of our applications are time-critical and have low latency constraints. Many existing graph neural network models published in the academic literature are tested only on very modestly sized graphs and prove inadequate for large-scale settings, both in terms of architecture and training algorithms. Hitting the right tradeoff between performance, computational complexity, memory footprint, training and inference time are key for a successful use of graph neural networks in production systems.
Dynamic graphs are another aspect that is scarcely addressed in the literature while being crucial to Twitter. Real-world interactions between people are dynamic by nature, and we witness trends, topics, and interests emerge and fade out all the time. Twitter graph is formed by a stream of asynchronous events such as new people joining the platform, following other people, faving, Tweeting and Retweeting. ML models working on continuous-time dynamic graphs could better account for the temporal information and eventually bring a boost in performance.
Higher-order structures such as motifs, graphlets, or simplicial complexes are known to be of importance in complex networks. Yet, the majority of graph neural networks are limited to nodes and edges only. Incorporating more complex structures into the message passing mechanism could, in principle, bring more expressive power to graph-based models. At the same time, finding such higher-order structure may increase the computational complexity of the model and become prohibitive in large-scale production systems. Once again, a careful tradeoff between expressivity and complexity is important.
Theoretical understanding of the expressivity of graph neural networks is rather limited. It is common to see both dramatic boosts in performance coming from the use of graph neural networks in some settings along with almost no difference in others. It is not clear yet when and why graph neural networks work well. The problem is difficult because one has to consider both the structure of the underlying graph as well as the data on it. For graph classification problems, recent works showed that graph neural networks are equivalent to Weisfeler-Lehman graph isomorphism test¹¹, a heuristic for solving a classical problem in graph theory. This formalism sheds light on why, for example, graph neural networks fail on instances of non-isomorphic graphs that cannot be distinguished by this simple test. Going beyond the Weisfeler-Lehman hierarchy of tests while keeping the low linear complexity that makes graph neural networks so attractive is an open research question.
A somewhat different aspect of theoretical understanding of graph ML models is their performance in the presence of noise. In graphs, noise can come both in the form of noisy features as well as noisy connectivity. It was shown that one can design adversarial attacks on graph neural networks¹² that use a carefully crafted connectivity and feature perturbations to degrade the performance of such systems. This is an instance of a broader topic of adversarial robustness of deep learning architectures. Providing theoretical guarantees on the performance of graph neural networks and regimes in which they fail is important for ensuring that the ML systems we use in production cannot be easily manipulated.
Applications of graph-based ML at Twitter are abundant and exciting. Graphs in different forms are the core data assets generated by people using our platform, whether the follow graph representing the social network of the users, the engagement graph capturing how people interact with Tweets, or graphs used by our Integrity Data Science team to relate users to devices and IP addresses from which they access the service in order to detect malicious behavior and violations.
Developing ML methods capable of taking advantage of these data assets is important for making Twitter a better place for public conversation.
¹M. M. Bronstein et al. Geometric deep learning: going beyond Euclidean data, IEEE Signal Processing Magazine 34(4):18-42, 2017.
²P. Battaglia et al., Relational inductive biases, deep learning, and graph network, arXiv:1806.01261, 2018.
³F. Scarselli et al. The graph neural network model, IEEE Transactions on Neural Networks 20(1):61-80, 2008.
⁴A. Küchler, C. Goller (1996). Inductive learning in symbolic domains using structure-driven recurrent neural networks, Proc. Künstliche Intelligenz, 1996.
⁵M. Zitnik et al. Modeling polypharmacy side effects with graph convolutional networks, Bioinformatics 34(13):457-466, 2018.
⁶J. Stokes et al. A deep learning approach to antibiotic discovery. Cell, 180(4), 2020.
⁷P. Gainza et al. Deciphering interaction fingerprints from protein molecular surfaces using geometric deep learning, Nature Methods volume 17:184–192, 2020.
⁸J. Gilmer et al., Neural message passing for quantum chemistry, ICML 2017.
⁹N. Choma et al. Graph neural networks for IceCube signal classification, ICMLA 2018.
¹⁰A. Wissner-Gross, Datasets over algorithms, 2016.
¹¹K. Xu et al. How powerful are graph neural networks? ICLR 2019.
¹²D. Zügner et al., Adversarial attacks on neural networks for graph data, Proc. KDD 2018.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.