Insights
Protecting user identity against Silhouette
By
and
Tuesday, 18 September 2018
The security of Twitter users and their data is important to us. One aspect is securing your Twitter identity from other websites you may visit.
A user may accidentally visit a malicious website via a link from an email or Tweet, from an advertisement on another website, or from a hacked version of a familiar site. The malicious nature of a site may not be apparent, because the site may perform actions in the background.
If a website is able to find your Twitter identity, they may use that information for tracking or association between other accounts. It may enable them to connect your offline names to your online identities. In some regions, this may put users at great risk.
Recently we learned of a new technique for discovering the identity of logged-in users to online platforms including Twitter, so we quickly moved to make some changes to our site to mitigate this risk, and urged browser partners to build out supporting features.
The issue was reported to us in December 2017 through our vulnerability rewards program by a group of researchers from Waseda University and NTT. They provided us with a draft of their paper for the IEEE European Symposium on Security and Privacy in April 2018. This gave us ample time to address the issue before it was made public.
Our security team triaged the issue and routed it through to the various relevant teams. In turn, they recognised the significance of the problem and formed a cross-functional squad to address it. In addition, we contacted several other at-risk sites and browser companies to urgently address the problem.
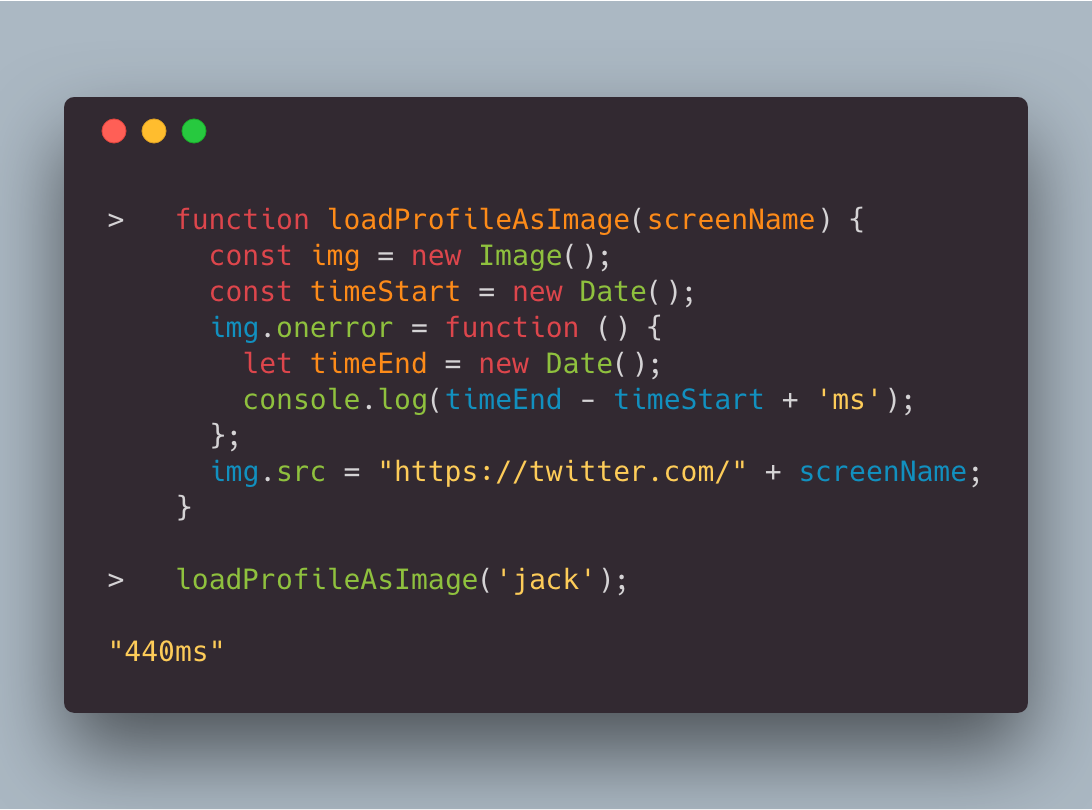
The attack depends on exploiting variability in the time web pages take to load.
A website can request a page from Twitter in the background with JavaScript using standard browser APIs. That request will be made using login credentials (stored in cookies), so if you're logged into Twitter, that request will be made as you.
Our site implements common CSRF protections on POST requests to prevent actions being made on your behalf (for example, being able to send a Tweet). The browser also enforces a number of limitations on cross-origin requests for security reasons. For example, another origin cannot read the response content. However, the requesting page is able to determine how long the request took to load.
This timing data will only reveal information if the response times can be manipulated into result based on a specific user. Generally, your page load time will depend on the Tweets you're viewing, and these aren't easy to predict.
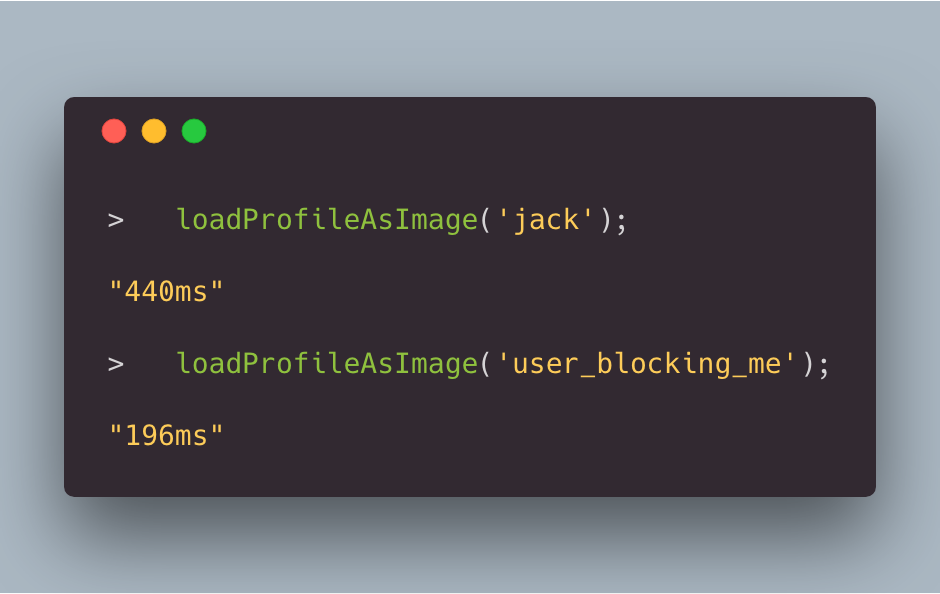
However, when you are blocked by another user, we prevent you from being able to load their profile page, and just show a basic empty page. That page is much faster to load than a profile full of Tweets.
In our tests, profile page load times reliably dropped from around 500ms to about 200ms. In this way, one user can affect the page load time of another user viewing a specific url.
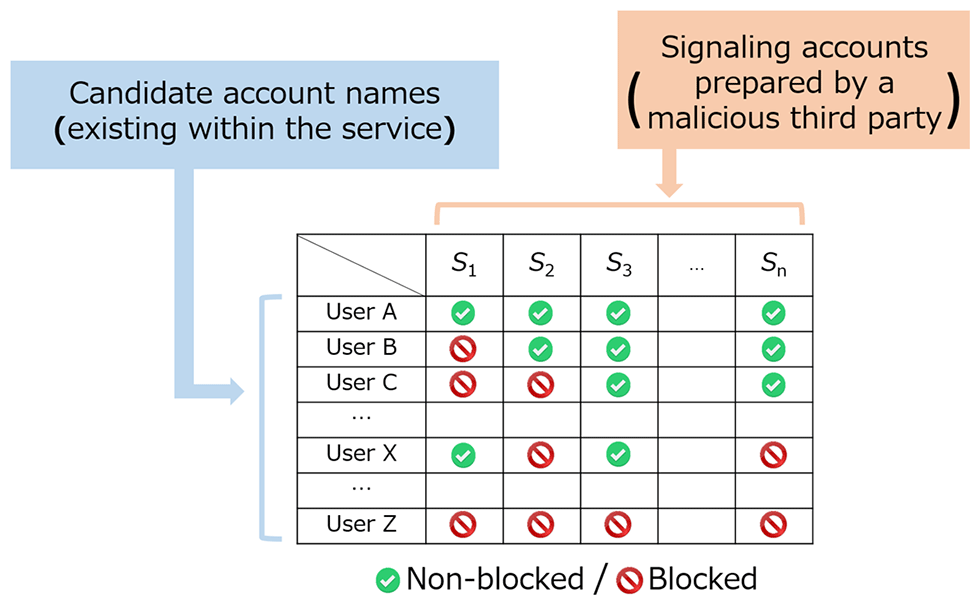
The researchers cleverly combined this knowledge with a matrix approach. By setting up a number of accounts with specific blocking relationships, they were able to use a surprisingly low number of timed requests to find a user within a large set.
For example, the researchers could set up just 20 Twitter accounts with specific blocking relationships that would be able to identify your account from a target set of around one million.
This technique was named "Silhouette" in their press release.
Of course, it would be relatively easy to simply Direct Message someone a unique link that the destination site will then know was sourced from that Twitter account. However, this only works against specific targeted users (spearphishing). This new technique is effective against a large set of users, without navigating from Twitter itself, when users would otherwise be expecting privacy.
The researcher's paper provided several ideas for mitigation of the issue.
The ideal solution was to use the SameSite attribute for our login cookies. This would mean that requests to our site from other sites would not be considered logged-in requests. If the requests aren't logged-in requests, identity can't be detected.
However, this feature was an expired draft specification and it had only been implemented by Chrome. While Chrome is our biggest browser client by usage, we need to cover other browsers as well, so we looked for other options.
Initially, we looked into ways we could reduce variation in response time. Should we return the same (full-size) profile page in both the blocked and non-blocked case, and merely render them differently? After a little thought we decided this was inadequate - it would need consideration for every page, would be brittle to future changes, and it would increase load times for users.
We then considered reducing the response size differences by loading a page shell, and then loading all content with JavaScript using AJAX. Page-to-page navigation for the website already works this way. However, we found that the server processing differences were still significant for the page shell, because the shell still needed to provide header information and those queries made a noticeable impact on response times.
Our CSRF protection mechanism for POST requests checks that the origin and referer headers of the request are sourced from Twitter. Since we knew this to be effective for POSTs, we considered how we could implement this for GET requests.
This proved effective in addressing the vulnerability, but it prevented this initial load of the website. You might load Twitter from a Google search result or by typing the url into the browser. To address this case, we created a blank page on twitter.com which did nothing but reload itself. Upon reload, the referer would be set to twitter.com, and so it would load correctly. There is no way for non-Twitter sites to follow that reload. The blank page is super-small, so while a roundtrip load is incurred, it doesn't impact load times too much.
With this general solution, we were able to apply it to a high-level of our various web stacks.
Some additional considerations we had to make were:
While we implemented the mitigation above, we started discussions with the major browser vendors regarding the SameSite cookie attribute. Once we shared the problem with them, they were keen to help. All major browsers have now implemented SameSite cookie support. This includes Chrome, Firefox, Edge, Internet Explorer 11, and Safari. This was an incredible effort in a very short timeframe, and the browser vendors deserve enormous credit for responding quickly.
Rather than adding the attribute to our existing login cookie, we added two new cookies for SameSite, to reduce the risk of logout should a browser or network issue corrupt the cookie when it encounters the SameSite attribute.
Adding the SameSite attribute to a cookie should be relatively trivial. It's a matter of adding "SameSite=lax" to the set-cookie HTTP header. However, Twitter's servers depend on Finagle, which is a wrapper around Netty - and Netty did not support extensions to the Cookie object. When investigating, we were surprised to find a feature request from one of our own developers the year before! But because SameSite was not an approved part of the spec, there was no commitment from the Netty team to implement. Ultimately we managed to add an override into our implementation of Finagle to support the new cookie attribute.
With the SameSite cookie and Referrer checks in place, we could be sure that our users were protected from the Silhouette technique.
This kind of attack is not entirely new - we have responded to previous security risks in the past - which is why we endorse responsible reporting and have security teams in place to respond.
Of course, Twitter is not the only site affected by Silhouette - we look forward to seeing other sites using SameSite cookies in the future.
We'd like to thank security teams at the browser companies for their rapid assistance to prioritize, and Takuya Watanabe with NTT for his comprehensive paper, responsible reporting, and ongoing help.
Appendix
Watanabe, T. (2018) "User Blocking Considered Harmful? An Attacker-controllable Side Channel to Identify Social Accounts", 14 May 2018, https://arxiv.org/abs/1805.05085
"NTT Discovers Novel Privacy Threat “Silhouette” in Social Web Services", 18 July 2018, http://www.ntt.co.jp/news2018/1807e/180718a.html
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.