Insights
Our discovery of cramming
By
Tuesday, 7 November 2017
As we’ve just announced, we’re expanding the character limit for certain languages. Before implementing the change, we analyzed data and trends around the length of Tweets and now, we want to share this information with you.
1. Finding answers to previously un-asked questions
For quite some time, we knew that the number of characters required to express a certain amount of information varied between languages — or, writing systems, to be precise. Japanese and Korean characters can convey twice as much information as English characters, for instance, and Chinese more than three times as much.
But the real question we needed to ask was whether or not 140 characters was an adequate limit for all languages. Do people Tweeting in Japanese have too much space? Do those Tweeting in English not have enough? How often were people trying to craft Tweets which ended up over 140 characters? And by how much? These questions seemed impossible to answer since there were no Tweets in Twitter's database over 140 characters long.
To figure this out, we first collected every Tweet over 70-day period, and cleaned them up by removing Retweets, Quote-Tweets, Tweets with links and Tweets with duplicate text, leaving us with several billion Tweets. Then, we separated them by language.
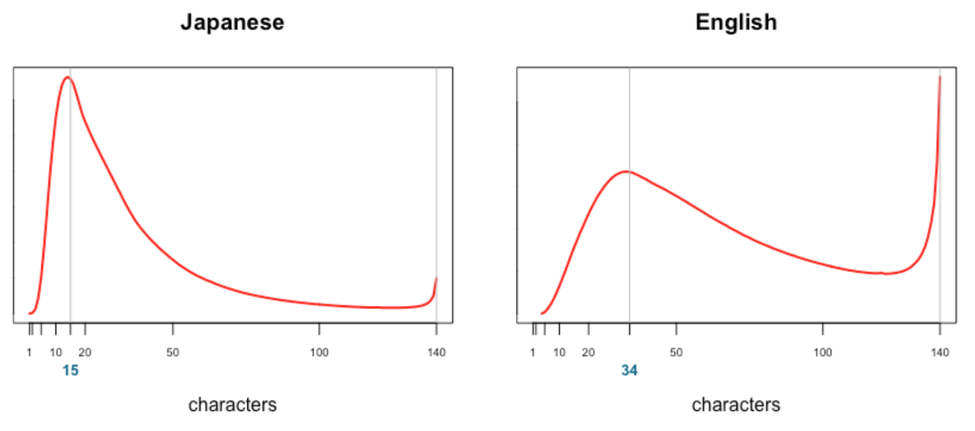
Here are the resulting length distributions of Japanese and English language Tweets:
The first peaks in both the Japanese and English Tweet distributions are at 15 and 34 characters, respectively, which matches well with the fact that Japanese needs as half as much text compared to English. The English Tweets graph also has a larger peak at 140, suggesting that people experienced far more difficulty in keeping their Tweets under 140 characters.
2. Discovery of log-normal distribution
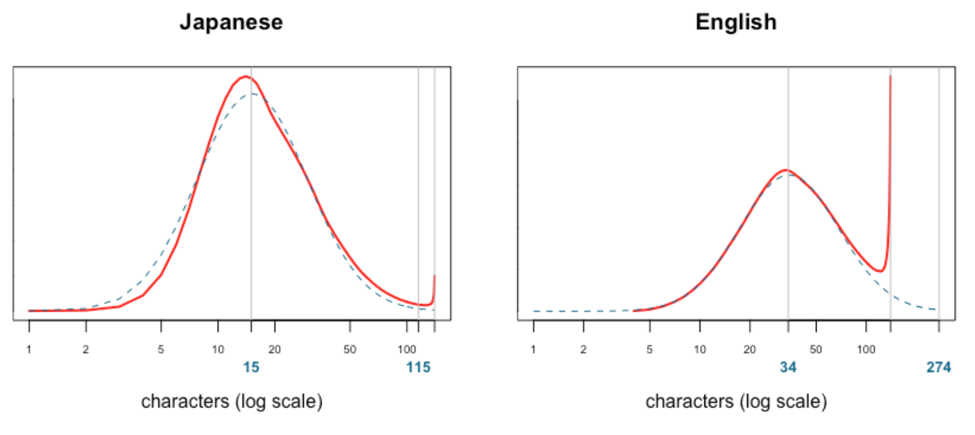
As we switched the graphs’ x-axis to a logarithmic scale, we found ourselves looking at a more familiar, symmetric shape.
It seems that when people try to write text within a certain length constraint, the resulting text lengths generally follow a log-normal distribution.
The peak of the Japanese length distribution now sits about halfway across the log scale (exactly halfway is 11.8). Most (99%) of the underlying log-normal distribution fits below 115 characters, with 99.6% below 140 characters. If Japanese Tweets are, in fact, generated according to this log-normal distribution, 0.4% of them would be over 140 characters.
In contrast, the log-normal distribution fitted to the English Tweet lengths reaches the 99th percentile only at 274 characters. Only 91% of the log-normal distribution manages to fit below the 140 limit. This indicates that 9% of English Tweets created would end up exceeding 140 characters, which then have to be crammed to fit into the character limit — the most likely cause of the big peak around 140 characters.
So, here we have the answer to our previous question:
9% of English Tweets, and 0.4% of Japanese Tweets, do not make it under 140 characters. And we will need 274 characters to make 99% of English Tweets viable as-is.
Note that this does not simply mean that English sentences are generally longer than Japanese sentences. We expect people would instinctively know how much they can write with 140 characters in their own languages. And still, people Tweeting in some languages fail to target the right text length more often than others.
3. The cramming
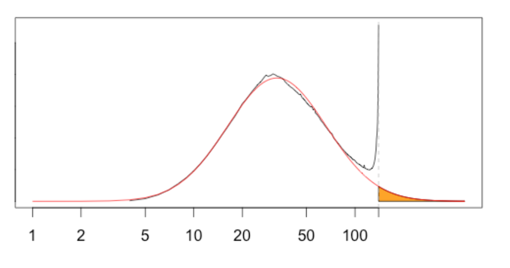
Let’s now explore these graphs in more depth, and try to come up with a model that can best describe the distribution of the Tweet length.
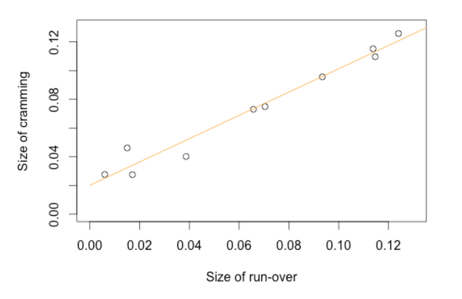
For convenience, we call this orange part of the graph — part of the theoretical log-normal distribution that falls beyond 140 characters — “run-over.”
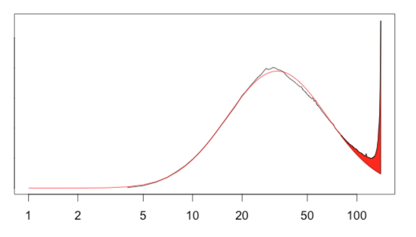
And this red part of the graph — the deviation of the actual length distribution from the theoretical log-normal distribution near the character limit — “cramming,” as it likely reflects people’s attempts to “cram” their Tweets within the character limit.
By comparing the size of run-over against the size of cramming for each language distribution, we saw that the two sizes correlated linearly.
It also appeared that the shape of the cramming is consistent across all languages, despite being different in sizes. In fact, they all seemed to follow a power-law curve. We don’t know for certain whether, or why, cramming follows a power law. But we were able to reproduce a similar distribution by the following simple simulation:
When a Tweet ends up being more than 140 characters,
4. Full model of the Tweet distribution
With all these put together, we came up with a model that approximates the Tweet length distribution with cramming. It basically consists of two parts: the log-normal distribution, and the power law that is directly proportional to the size of run-over — a.k.a. cramming.
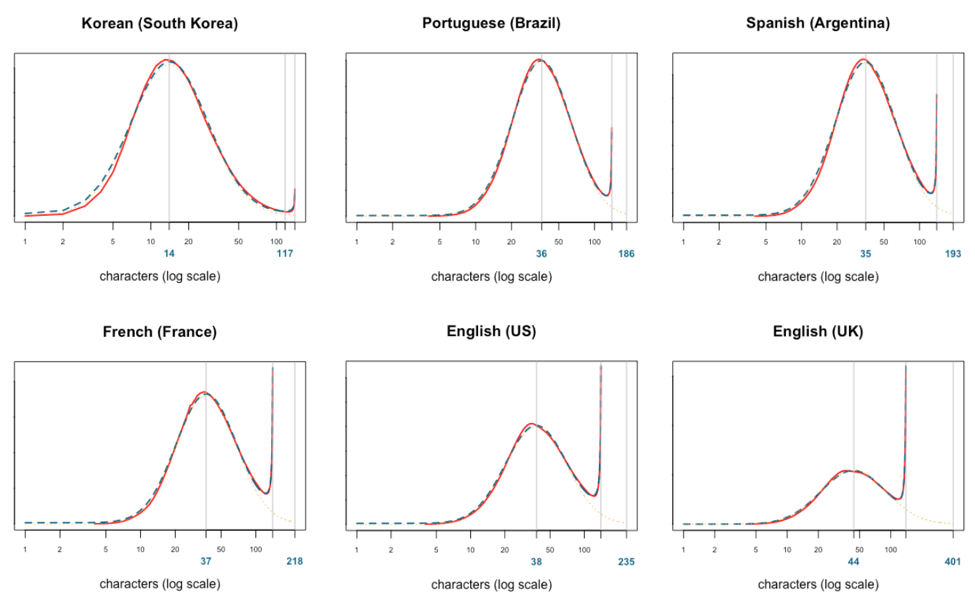
Here are some examples of Tweet length distributions from various countries and languages (red lines), and how the model fits with the actual distribution (blue dotted lines).
One thing to note here is that it’s not only language that affects the distribution. As you can see above, English Tweets from the U.S. are much shorter than English Tweets from the UK (or Canada or Australia). Replies tend to be shorter than non-replies. Tweets from different clients also show slightly different patterns. If we divide Tweets by topics, we may see some differences there, too.
The Tweet length distribution reflects how Twitter is currently being used by that particular group. We would not have observed cramming if the only usage of Twitter among English speakers was to say “Hi” and “Yo.” But that doesn’t mean that people speaking English can generally express anything in just two characters.
What we saw through this modelling is that people Tweeting in English and other languages are actually trying to Tweet as complex thoughts as people using Japanese and Korean, but with much more difficulty. To balance this, we need some sort of variable character limit depending on the language characteristics.
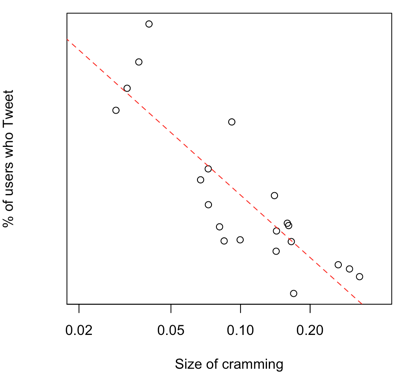
5. Correlation with proportion of people Tweeting
Yet another discovery that interested us was the correlation between the size of cramming and the percentage of people who Tweet.
Listen, we know the cliché — correlation doesn’t imply causation — but it did seem reasonable to expect that people will Tweet more if there’s less friction to Tweet. This looked like something worth trying.
So we did.
6. Finding the practical implementation
We’ve had many wild ideas for implementing the variable character limit. Starting from a simple per-country configuration, to much more ambitious LSTM-based contraption (where more predictable input, such as “e” after “th,” will be counted far less than as one character).
But in the end we decided on the current implementation which weights each character based on the Unicode block. Currently, a certain range of Unicode blocks, including Basic Latin, are counted half as much as other blocks, such as CJK Unified Ideographs.
This, of course, is not an ideal solution. But we can accommodate those people who mix multiple languages in a single Tweet without having to install complex language detection mechanisms on clients, or relying on manual language settings. And we have a way to finely adjust the weights later on. This new counting logic will be available via open source TwitterText library.
After all the analysis, implementing the change introduced various new challenges on the UI side. At some point I had an hour-long discussion (and by discussion, I mean duel) with the designer about whether we should still keep the remaining character count in the UI — which introduces substantial complexity with the variable counting — or totally remove it. You can read all about it on the @design blog.
Acknowledgements
This has been a rather unusual project, from the beginning to end. So many teams, colleagues working outside of their usual roles, and, of course the people Tweeting every day, joined forces to move forward and scrutinize this unprecedented piece of work. We just cannot fit all your names in the length of this post, no matter the character limit. We thank you all. And we will keep on researching, and improving.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.