Insights
Manhattan software deployments: how we deploy Twitter’s large scale
By
Monday, 9 May 2016
Twitter’s Manhattan distributed database is one of the primary data stores at Twitter, serving Tweets, Direct Messages, and advertisements, among other use cases. We want to share the challenges of handling Manhattan software deployments and our approach to solving them.
The Manhattan service runs on clusters of thousands of physical hosts in multiple data centers. Each instance of the Manhattan service can be viewed as two parts consisting of a stateless coordinator process (to handle the routing of the requests) and the stateful backend layer (which stores the actual data). For reliability guarantees, the same data is replicated to a set of instances — typically three — called a mirror-set. The focus on this post will be on the core Manhattan service described above. We won’t cover supporting services — such as the topology manager, configuration web service, and metadata service — because those services have far more relaxed deployment constraints compared to the core service.
Challenges
At its heart, deployment can be simply viewed as distributing the software package and restarting the service. But the constraints and challenges involved in safely deploying a distributed database complicates this process.
In summary, the challenges of Manhattan deployment can be categorized as the problems of scale and the requirement for speed and safety.
Goals
We have built a deployment service for Manhattan with the following characteristics and features:
Approach
The Manhattan package is composed of two sub packages:
Different clusters typically use the same coordinator and backend packages but have specialized configurations. Both packages are versioned separately and can be deployed independently.
In a nutshell, a deployment cycle goes through the following steps:
Components
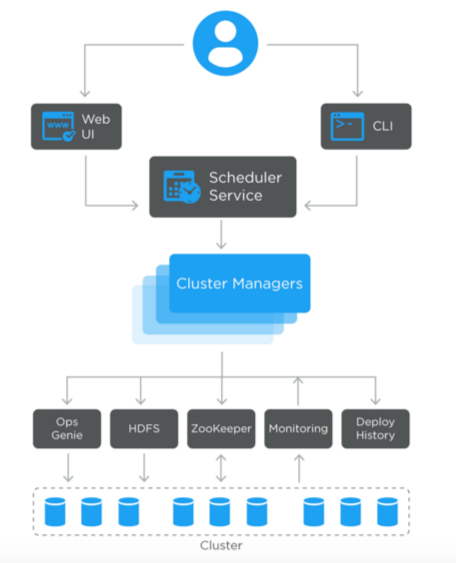
The operator submits the deployment plan through a command line tool or a web interface.
Scheduler
The Scheduler service receives a plan from web interface or command line and coordinates with different cluster managers to safely execute that plan.
Sample plans:
Cluster manager
This component continuously monitors deployment status, on a per cluster basis, and updates the deploy status.
Deploy agent
This is the part of the deployment system responsible for rapidly distributing the Manhattan binaries to all the hosts in the cluster. It consists of two parts:
When a new deployment plan is executed, batches of hosts download the new packages in parallel. Typically, all hosts in an about twenty five hundred hosts cluster receive the package within five to seven minutes. The deploy-agent also caches a set of previously downloaded packages on disk to save on time required for rollbacks.
OpsGenie
OpsGenie is the topology management service for Manhattan and manages various aspect of Manhattan related to data placement throughout the cluster. One of its components is responsible for driving a safe cluster wide rolling restart. It enforces hard restrictions to support consistency guarantees (i.e., no more than a small subset of hosts in a mirror-set should be down at any given time) while also allowing for controllable concurrency of total number of hosts that can be restarted in the cluster.
Conclusion
During the early days of Manhattan development, the packages were built on some developer’s laptop and manually copied to the production hosts which was both cumbersome and error prone. We have come a long way since then and as we continue to grow in scale, the deployment service saves countless engineering hours and ensures that deployments are a safe, easy, efficient, and joyful exercise.
If you think this is interesting and would like to work on similar problems, the SRE team at Twitter could use your help - join the flock!
Acknowledgements
Special thanks to Istvan Marko for his contribution to this project and blogpost.
We also want to acknowledge contributions by Alex Yarmula, Boaz Avital, Chris Hawkins, David Helder, Devin Kowatch, Juan Serrano, Kevin Crane, Pascal Borghino, Peter Beaman, Peter Schuller, Ravi Sharma, Ronnie Sahlberg, Sumeet Lahorani, Vladimir Vassiliouk, and others from the core-storage team at Twitter.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.