Insights
Discovery and Consumption of Analytics Data at Twitter
By
Wednesday, 29 June 2016
The Data Platform team at Twitter maintains systems to support and manage the production and consumption of data for a variety of business purposes, including publicly reported metrics (e.g., monthly or daily active users), recommendations, A/B testing, ads targeting, etc. We run some of the largest Hadoop clusters in the world, with a few of them larger than 10K nodes storing more 100s of petabytes of data, with more than 100K daily jobs processing 10s of petabytes of data per day. On the Hadoop Distributed File System (HDFS), Scalding is used for ETL (Extract, Transform, and Load), data science and analytics, while Presto is employed for interactive querying. Vertica (or MySQL) is used for querying commonly aggregated datasets, and for Tableau dashboards. Manhattan is our distributed database used to serve live real-time traffic.
Over time we have evolved from a single analytics group that owns all of our core datasets, to several hundreds of employees (and teams) producing and consuming these datasets. This means that discovering data sources, getting their complete lineage (i.e., how those data sources are produced and consumed), consuming them irrespective of their formats, locations and tools, and managing their entire lifecycles consistently has become a real problem.
To meet these needs, the Data Platform team has been working on the Data Access Layer (DAL), with the following goals:
In this blog, we will discuss the higher-level design and usage of of DAL, how it fits in within the overall data platform ecosystem, and share some observations and lessons learned.
To enable data abstraction, DAL has a concept of a logical dataset and a physical dataset. A logical dataset represents a dataset independently of its storage type, location, format, and replication. A logical dataset could physically live in multiple locations, and may even be hosted on different systems such as HDFS or Vertica. A physical dataset is bound to a physical location (e.g., HDFS namenode, database server like Vertica or MySQL, etc.) where all its segments (physical artifacts) are stored. Depending on its type, the segments are either partitions (if it is a partitioned dataset) or snapshots. Metadata regarding how to consume the dataset is stored at the physical dataset level. This abstraction enables us to a) group together the same logical dataset to enable easier discovery across various physical implementations, and b) provide all the information needed to consume the dataset, including formats, locations, and more from clients such as Scalding or Presto. Additional metadata is added to DAL datasets to enable easier discovery and consumption (as you see below). Since all access to datasets happens via DAL, we use it to get the complete lineage of all datasets produced and consumed.
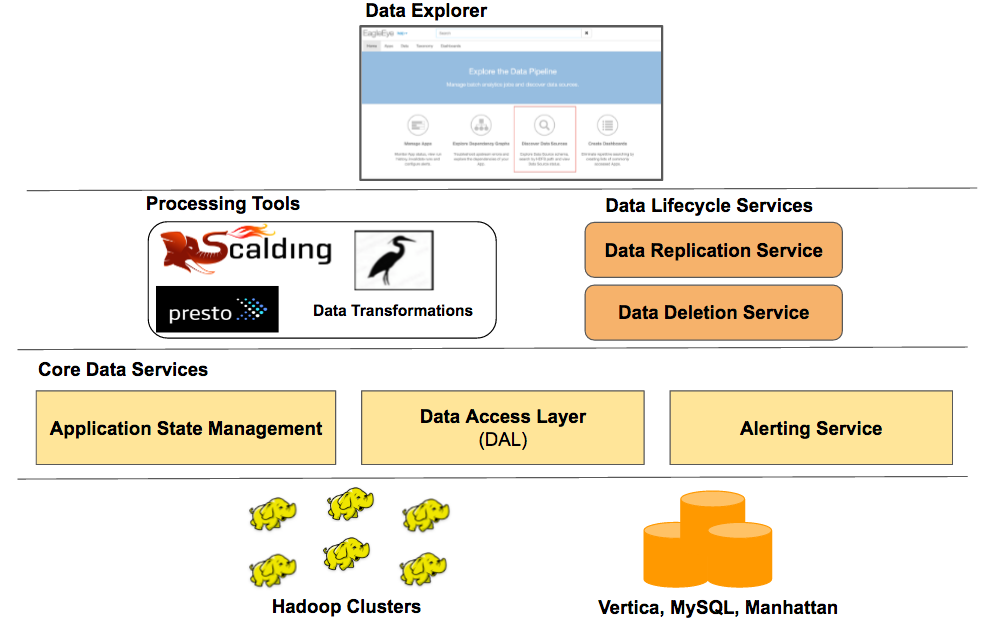
The following diagram shows how DAL fits into the overall architecture of our data platform.
At the bottom of the stack, we have the core infrastructure which includes Hadoop clusters, and databases such as Vertica, MySQL, and Manhattan. The core data services layer includes the Data Access Layer (DAL), and also services for application state management for checkpointing job state and dependencies, and for alerting if jobs are delayed. Data lifecycle management services such as the replication service, which copies data across Hadoop clusters, and data deletion service, which deletes data based on its retention policies, are built on top of the core services layer. The processing tools include Scalding and Presto as mentioned before, and also an in-house ETL tool for data transformations between different back-ends such as HDFS, Vertica or MySQL.
The data explorer UI (internally called EagleEye) aggregates metadata served by the core data services layer, and serves as our portal into data at Twitter. It is used to discover datasets and applications, and to explore their dependency graphs.
Like we mentioned earlier, DAL datasets have additional metadata that enables discovery and consumption. We discover and consume datasets via the data explorer as follows.
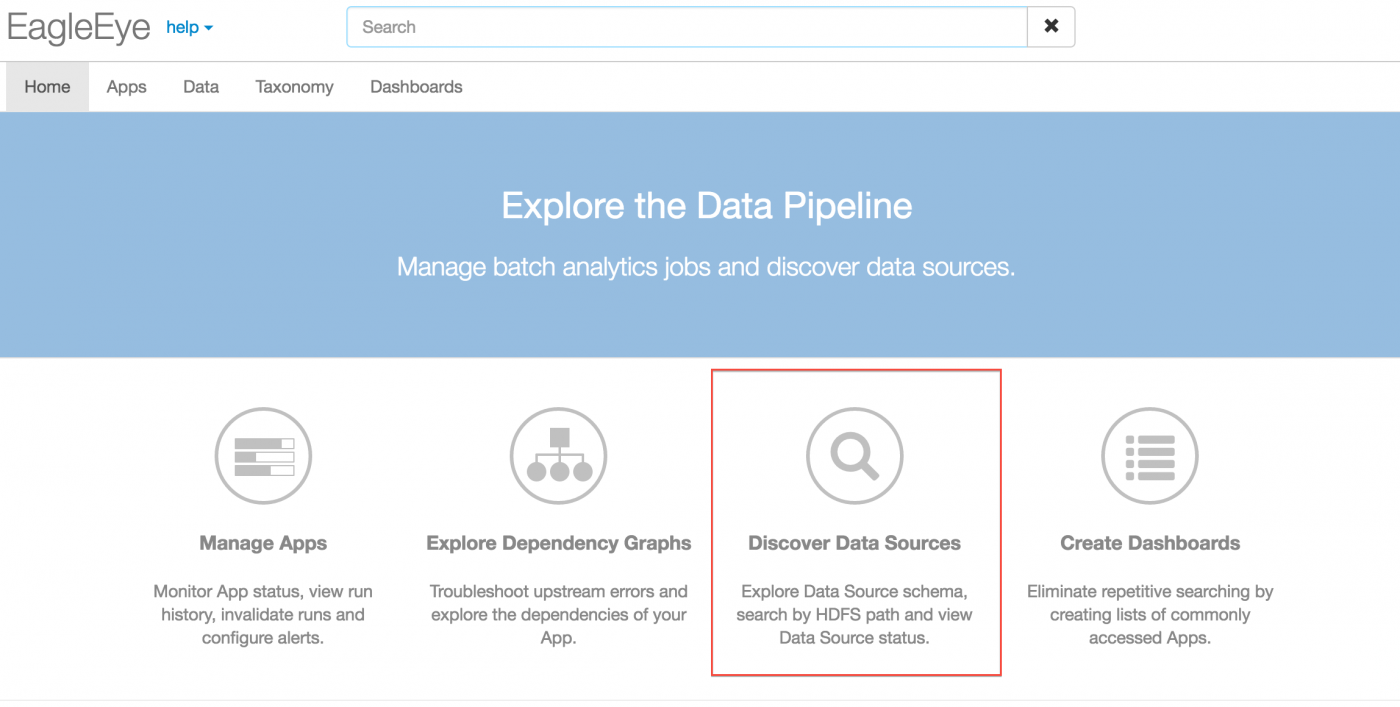
Discover a dataset
We can discover commonly used datasets via the “Discover Data Sources” link (highlighted) in our data explorer, or can search for a dataset that they are interested in. The data explorer looks up this dataset in the metadata that it has aggregated from DAL.
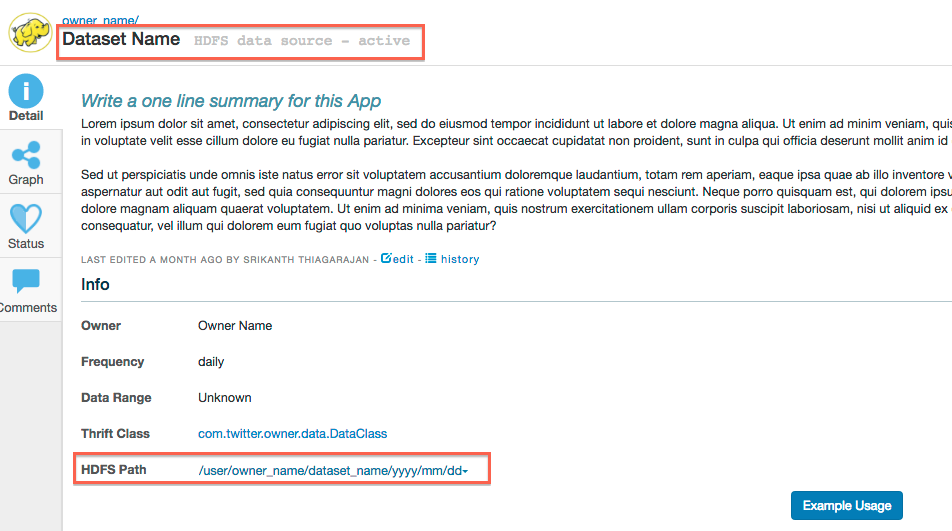
Review information about the dataset
If the data explorer finds the dataset that we searched for, it displays the information for it for us to review. As you can see below, the following dataset was found on HDFS. There is a description of the data provided by the owner, as well as the overall health of the dataset that is computed using certain heuristics. We can also review metadata fields such as the owner, the frequency of the dataset, the thrift class that represents the schema, the physical location on HDFS that it is available at (also via DAL).
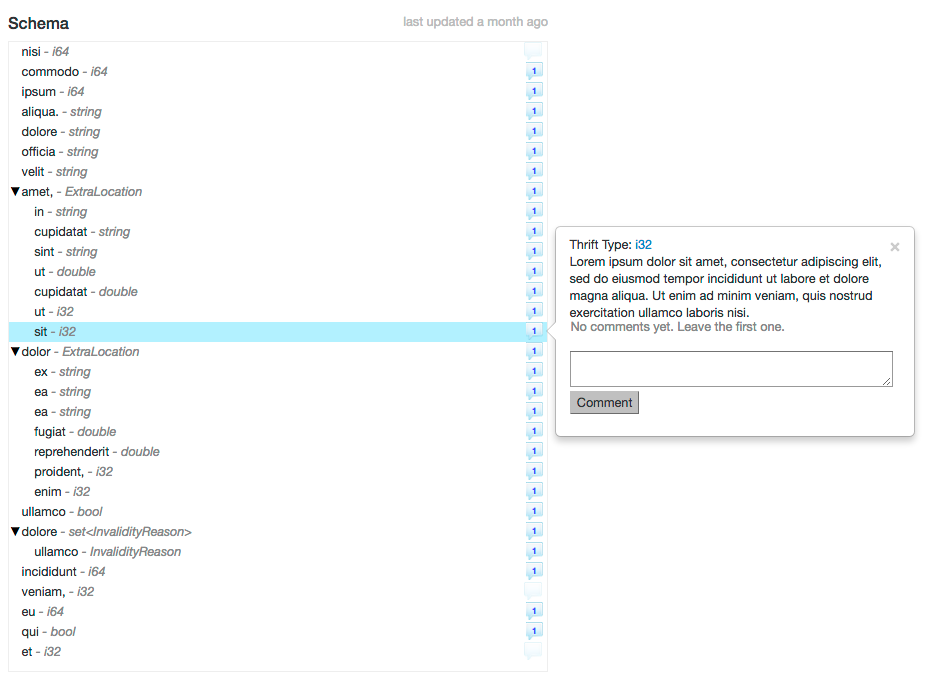
We can also inspect the schema for the dataset, along with comments for specific fields added by users. Similarly, schemas can also be discovered for other systems such as Vertica and MySQL.
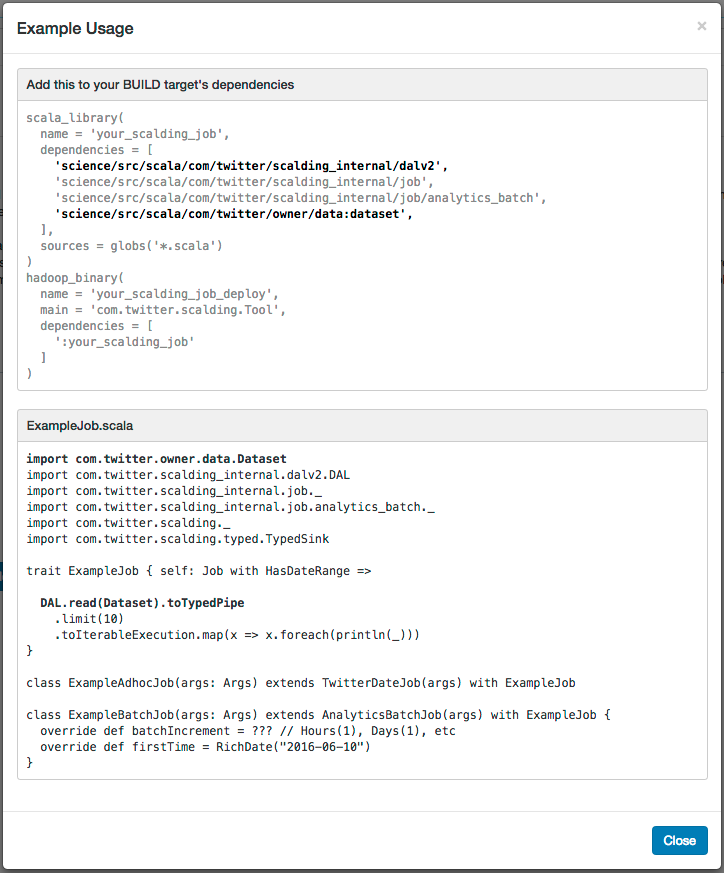
We can then look at example usage. The following screenshot shows example usage in Scalding – note that the formats and locations are totally abstracted away from the viewer . When we run the following snippet via Scalding, the date range is provided to DAL, which provides the location and formats for the segments (or partitions) that are in the specified date range. The DAL Scalding client then uses that information to construct the appropriate Cascading Taps (i.e., the physical data source) with the appropriate number of Hadoop splits.
Get complete lineage and dependencies
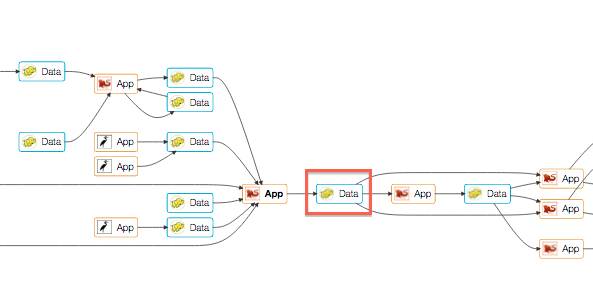
We can also look at the jobs that produce and consume the dataset, and the complete lineage for it. As you can see from this screenshot, there is one job that produces this dataset, but there are several jobs consuming it. The job that produces the dataset depends on several upstream datasets on HDFS. It’s also possible to find out if any of the jobs producing the datasets are late, and if they are alerting.
At organizations our scale, simplifying data consumption across all data formats and storage systems is critical. There are a few open source tools that address data abstraction such as the Hive Metastore, which can be part of the puzzle, but value-added features such as auditing and lineage for datasets, managing retention and replication, and example usage to make data consumption easy are just as important.
We made a design choice to implement DAL as an abstraction and consumption layer, rather than just focusing on discovery and auditing. We did so because we wanted DAL to be the source of truth for our datasets - this helps us switch data formats transparently (such as from lzo-compressed Thrift to Parquet), helps produce and consume the data from different tools such as Scalding and Presto interchangeably using the same source of truth for the metadata, helps with the migration of jobs between user accounts and locations (as it happens quite frequently over the course of time as job ownership and team roles evolve), and enables management of retention and replication of datasets in one place.
In the beginning, we started with DAL as a library that talked directly to the database back-end. This was fragile for several reasons – security was poor since credentials had to distributed to every client, scaling was hard as every client connected directly to the database, and rolling out changes to all the users was slow since clients re-deployed at different times. We moved away from this model to build a service layer, which helped alleviate these issues.
Our work on DAL involved rewiring dependencies of thousands of jobs (i.e., from HDFS to DAL), which were already running in production. We had to do this extremely rigorously and cautiously without breaking these jobs. If we only cared about data lineage and auditing, the implementation could have been simpler and less risky because we could have potentially implemented it without rewiring job dependencies via an asynchronous or offline process. Migrations are hard, time consuming, and best done in an incremental fashion. But we have learnt that a metadata service is something that every data platform needs, and would highly recommend that it be one of the first things to build a data platform around. We are now making DAL-integration the first order of business for every new processing tool – e.g. we did so when we recently rolled out Presto for interactive querying.
Finally, there appears to be an opportunity to consolidate efforts across many of our peers since many of us are trying to solve the same or similar problems. Let’s talk!
We will soon follow up with another post discussing the various technical aspects of in greater detail. Stay tuned!
Acknowledgements
The DAL team is Arash Aghevli, Alaukik Aggarwal, David Marwick, Joseph Boyd, and Rob Malchow. We would like to thank the Scalding team (specifically Alex Levenson and Ruban Monu for integrating Scalding with DAL), the Hadoop team (specifically Joep Rottinghuis and Gary Steelman) and project alumni, who include Bill Graham, Feng Peng, Mike Lin, Kim Norlen, Laurent Goujon, and Julien Le Dem.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.