Infrastructure
The data platform cluster operator service for Hadoop cluster management
By
Wednesday, 8 February 2023
Ashwin Poojary, Head of Platform Services SRE, @ash_win_p
Lakshman Ganesh Rajamani, Staff Site Reliability Engineer, @lakshmanganesh
Sampath Kumar, Senior Site Reliability Engineer, @realsampat
Twitter uses Apache Hadoop and does not utilize any enterprise Hadoop solutions. The lack of standard cluster management tools was a challenge at the scale we operate on. To address this, we have created our own automation and management tool, the Data Platform Cluster Operator (DCO) service, built in Python, which aims to make SRE operations efficient and provide robust solutions for managing Hadoop clusters across all our data centers and in the cloud.
As SREs in the Data platform team, we previously spent a vast majority of our time managing and maintaining Hadoop cluster operations, such as adding or removing hosts to clusters, addressing capacity requirements from users, draining hosts before removal, maintaining the life cycle of the hosts, and ensuring cluster health. The DCO service streamlined these processes and made cluster management a seamless experience.
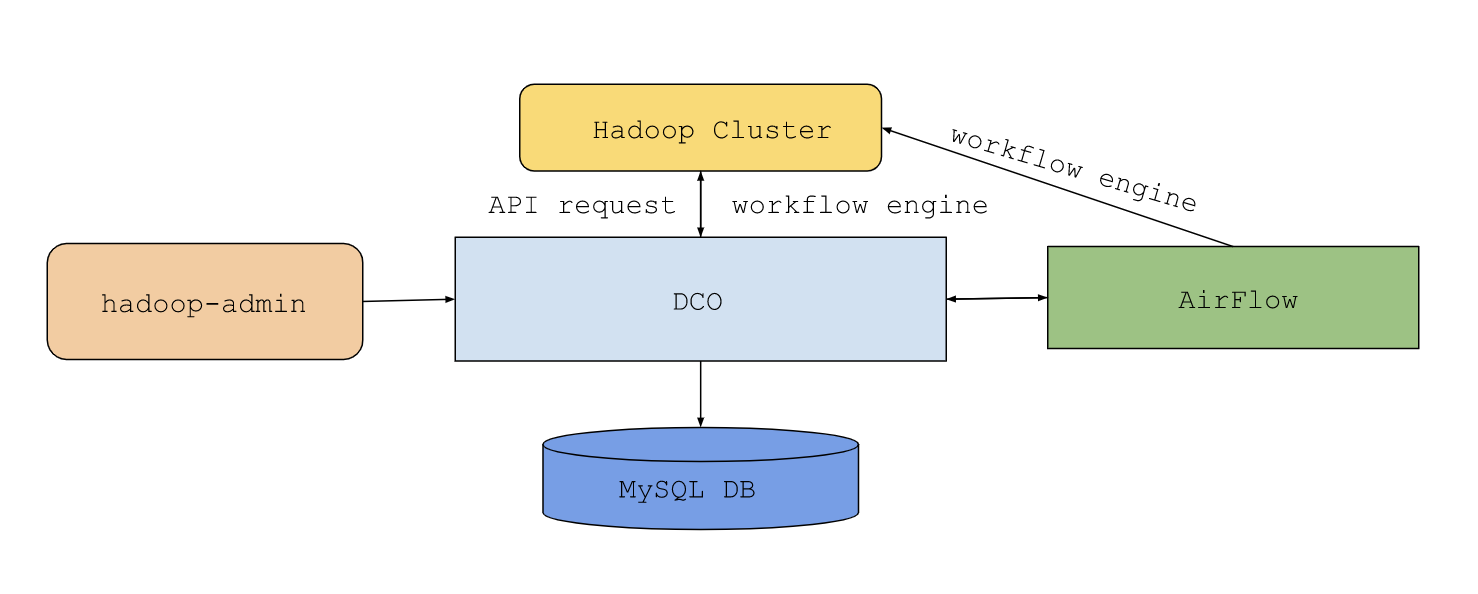
The DCO service is implemented using Flask, a Python web framework. It is used to expose API endpoints and interact with the database backend. We have a load balancer and web server gateway interface. DCO handles execution orchestration via an internally managed reliable workflow engine for managing hardware servers. One approach that we considered to handle requests is that a request from hadoop administration will be parsed, stored in the database and forwarded to the orchestration engine, which will use a callback feature to update the job state in DCO’s database. In case that the DCO is not available at callback time, there will be a service periodically polling the orchestration engine for plan status. The orchestration engine will implement workflows as plans with sets of tasks that need to be executed on a specific host. Each of these tasks will be retriable for a configured number of times. The orchestration engine will also handle failure scenarios for specific tasks and try different sets of tasks based on failures. A MySQL database will store data and metadata of clusters currently being managed by DCO. The database will receive input from the request management controller which will be responsible for receiving API requests and executing and dispatching tasks. The database is implemented with sharding to allow horizontal scaling if the request volume requires it.
The tech stack for the DCO service includes the following components:
hadoop-admin is a python based library which contains the logic to perform hadoop administration operations, look up the status of clusters and the services running on clusters. It also has the ability to execute per-node tasks such as service changes using on-node binaries.
Adding hosts to a Hadoop Cluster can be a complex task, requiring the installation of various packages, modification of configuration files, and restarting of relevant services. However, with the use of the DCO service, this process can be streamlined into a single step operation. The Site Reliability Engineers can provide a file containing the host names, along with relevant cluster variables, to DCO, which will then proceed to add the hosts to the cluster. The SREs can monitor the progress of this operation through the use of the job ID provided by DCO. This approach enhances efficiency and reduces the likelihood of errors.
Just like adding hosts, removing hosts is a one step process using the hadoop-admin tool. It not only removes hosts from the cluster but also sends them through the reinstallation process and makes them ready to add to another cluster.
Allocating and deallocating storage space and compute resources can be done via the hadoop-admin tool and DCO stores the history of the changes. This data can be used for charge back for customers.
All Twitter hadoop clusters use kerberos authentication. The DCO provisions and manages the lifecycle of the keytabs of each node of every cluster.
Various feature flags are developed to release the features based on requirement. DCO reads the yaml file of each cluster to check what features that cluster needs.
The DCO service runs in each datacenter serving the cluster and cluster operations use cases within that datacenter. DCO does not control or manage the critical data path on hdfs or compute capacity on top of yarn so it does not have a very high uptime SLO.
In conclusion, the new Data Platform Cluster Operator (DCO) service for Hadoop cluster management brings significant advancements in terms of operations, maintenance, and scalability for the SRE team. The service has undergone comprehensive testing and has been successfully deployed on production clusters, making our infrastructure more robust and reliable.
We thank Dave Beckett, Jeremy Inn, Sudhir Srinivas, Tihomir Elek and many others who were involved in the design, development and deployment of the Data Platform Cluster Operator service at Twitter.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.