Infrastructure
Twitter Sparrow tackles data storage challenges of scale
By
Tuesday, 28 June 2022
When the engineers on Twitter’s platform teams come into work every day, whether they’re sitting at one of the desks at the office or opening their laptops at home, the common thread that connects all their work is the complex challenge of operating at massive scale. Tens of thousands of nodes, hundreds of petabytes, and trillions of events per day are just facts of life at Twitter.
Working at that scale means pushing the limits of our data storage and processing systems and our cloud providers’ capabilities for Twitter’s passionate engineers. Praveen Killamsetti (staff software engineer) likes to say, “We assume everything works at scale, but not at Twitter scale … even for cloud providers.”
The amount of data we record, store, process, and analyze unfolds in real time and grows with the number of daily active customers. Every time a customer takes an action on the platform, from Liking a Tweet to scrolling past an ad, we log that information and turn the data into insights that help make our platform a better place for our end customers.
To illustrate this story of immense volume, let’s take a look at Twitter Sparrow — a recent initiative that has shortened the processing and delivery of data from hours down to minutes … and even seconds.
Sparrow is just one of the many projects that demonstrate the duality of engineering at Twitter — tackling cutting-edge challenges of scale while working on teams that prioritize support and transparency. And it’s this bottom-up support from our peers, managers, and leaders that allows us to make strides in the data storage community. At Twitter, we’re all part of the same team. And that’s exactly what Praveen saw while working on Sparrow.
Enabling real-time insights into user behavior was Twitter Sparrow’s goal. In 2020, senior engineers Lohit Vijayarenu, Zhenzhao Wang, and their team began working on the concept as a Twitter Hack Week project to shorten the amount of time it takes to record and deliver data in the log pipeline.
This pipeline holds interactions from hundreds of millions of customers that connect on Twitter through a variety of services, from web to mobile. Each click, swipe, and scroll is recorded as an event that our systems log to provide a rich picture of how our platform is used and how that evolves day to day. It’s these insights that allow us to better understand our customers and serve the public conversation.
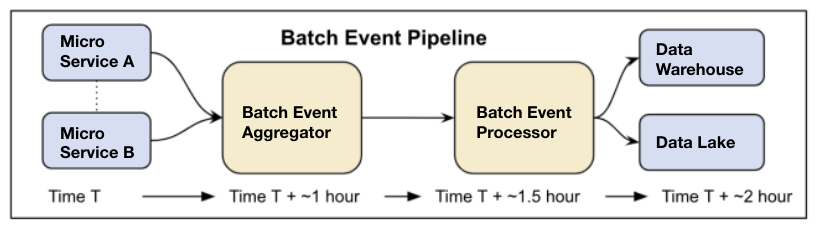
Before Twitter Sparrow began, our data engineers waited up to several hours for fresh data from customer events to become available, due to the previous batch log ingestion pipeline. This design was optimized to support scale on the order of billions of events per minute. As a result of the sheer amount of data collected on a daily basis, events flowing through various software systems were batched to optimize for throughput at the expense of latency.
As our needs as a company and the technological landscape around us evolved, delivering this data to our engineers in real time was a must to be able to “move at the speed of Twitter. We want Twitter products to develop fast, understand things fast, fail fast, if something doesn't work, and reiterate fast,” Praveen says.
We started Twitter Sparrow with the goal of delivering the log data generated from the tens of thousands of microservices spread across different data centers into the hands of our Tweeps more efficiently. The way to do that was to redesign our batch log ingestion pipeline to take advantage of more modern streaming technologies.
Streaming data pipelines provide users low-latency access to fresh data as it’s produced. But for classic historical data processing, such as running reports over longer time periods, batch processing can be simpler and more efficient. To address our full set of use cases, the redesigned log ingestion pipeline had to provide both data as stream and historical data.
Here’s a before and after look at the architecture of these pipelines:
After Twitter Sparrow, we migrated to a streaming event pipeline:
To modernize the pipeline with the goal of reducing end-to-end latency, we revisited all components of the system and adopted a streaming-first approach.
We developed a Streaming Event Aggregator to collect the log events from services and pass them to a message queue like Kafka or Google Pub/Sub. The Streaming Event Processor then uses Apache Beam and Google Dataflow to read events from the message queue, applies transformations or format conversions, and streams the events into downstream storage systems, such as Google BigQuery and Google Cloud Storage.
This streaming-first architecture certainly isn’t something unique to Twitter. What is unique to Twitter is making it work at our scale using Google Cloud. Because of the scale at which we process data, our new pipeline pushed the boundaries of what was possible on Google Cloud. The effort to scale the new pipeline and all of the supporting infrastructure to meet the throughput and latency objectives was enormous.
In the end, we have a low-latency streaming log ingestion pipeline in Google Cloud that enables Twitter’s data science community to answer questions that couldn’t even be considered previously. One example is analyzing user behavior on the Twitter platform in near real time. If you’re interested in diving deeper, we’ve published a paper about our experiences that was accepted for the IEEE BigData 2021 conference. [1]
Sparrow is just one example of the unique challenges of scale we face everyday at Twitter. While this initiative showcases the many challenges we face when building at scale, (such as pushing the limits of cloud services) we’re only just scratching the surface. Nearly every project we tackle faces scale challenges on some level.
When I talk to folks about why it’s amazing to work at Twitter, I tell them there are two reasons. The first is the scale. As engineers we get to solve lots of fun, crunchy challenges, which is what makes the work interesting.
The second is the culture. Twitter is a bottom-up, employee-centric organization, where engineers are able to tackle tough problems with the full support of their peers and their leadership. Back before WFH was the norm, it was a regular thing to see engineers gathered around a monitor or a booth in a break room discussing designs and talking through problems. After the pandemic sent us all home, that level of collaboration did not fade. Slack and impromptu video calls have replaced face-to-face time, but the net effect is still the same.
Beyond teamwork, Twitter’s company culture does a lot to make it possible for our engineers to do their best work. Company policies, such as our commitment to open source, unaccrued vacation time, monthly global days of rest, pay transparency, WFH productivity budgets, team building budgets, and an open invitation to share #Gratitude and #BringYourWholeSelfToWork make it easy to #LoveWhereYouWork.
The combination of solving challenging problems at scale and a culture that is truly supportive makes Twitter a unique place to work. At Twitter, we get to kick butt, have fun, and push the limits of what’s possible while doing it.
---
[1] Lohit VijayaRenu, Zhenzhao Wang, Praveen Killamsetti, Tisha Emmanuel, Abhishek Jagannath, Lakshman Ganesh Rajamani, and Joep Rottinghuis, Twitter Sparrow : Reduce Event Pipeline latency from hours to seconds
About the author: Daniel Templeton is a senior manager for software engineering, and he’s been at Twitter for over three years.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.