Infrastructure
Data Quality Automation at Twitter
By
and
Thursday, 15 September 2022
Twitter ingests thousands of datasets daily through our automated framework. It runs on top of existing services such as GCP Dataflow and Apache Airflow moving Hadoop on-premise data into BigQuery as described in this previous article. This framework enables Twitter employees to run over 10 million queries a month on almost an exabyte of data in BigQuery.
After we increased data availability, the next natural step was to ensure data quality on those datasets. They power Twitter’s Core Ads product analytics, ML feature generation, and portions of the personalization models.
Data freshness, completeness, accuracy, and consistency are some of the criteria used to determine data quality, which assesses the state of the data.
Some product teams were doing manual testing, on their own, by executing SQLs commands manually via BigQuery UI and/or Jupyter notebooks. There wasn’t a single framework to run data quality checks in an automated and consistent way.
It is important to have automated data quality checks to identify anomalies, accuracy, and reliability of datasets at scale to achieve:
We created Data Quality Platform (DQP) which is a managed, config-driven, workflow-based solution to build and collect standard and custom quality metrics, alerting on data validations, and adding monitoring to those metrics / stats within GCP.
These features in the platform enable us to identify and monitor anomalies, latency, accuracy, and reliability of these datasets.
Under the hood, DQP relies on open-source Great Expectations and our own built Stats Collector Library as operators to generate the logic to query the resources. It also depends on Airflow for workflows and state management and Google’s Dataflow for transportation into BigQuery.
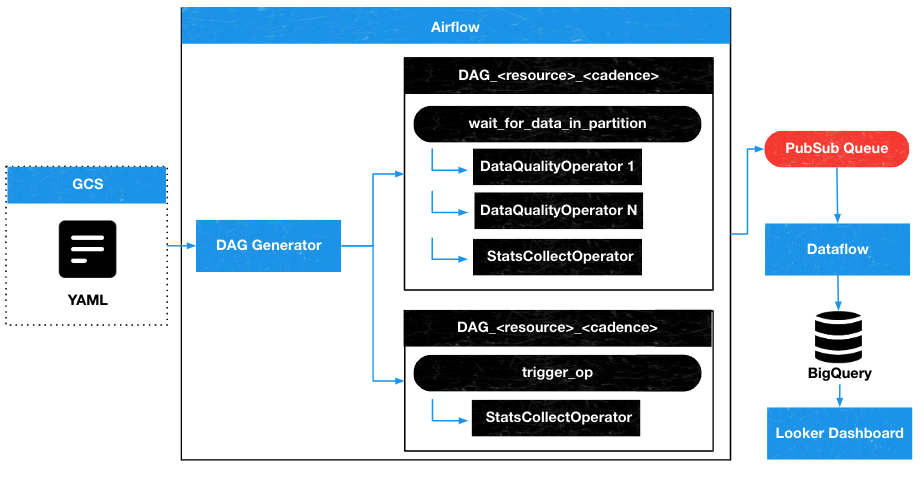
Data Quality Platform relies on a number of technologies along its stack. Using a CI/CD workflow, we upload YAML configurations to GCS. From there, the associated Airflow worker will start the associated test at the resource and cadence granularity. The results of the test will run and send its results to a PubSub queue. Later, the Dataflow job lands the dataset from the queue into the destination table in BigQuery used in Looker, enabling users to debug and identify trends in metrics.
Here are some work streams that benefit from the solution:
The Revenue Analytics Platform team builds and maintains products to efficiently ingest, aggregate, and serve revenue analytics data to downstream products such as AdsManager. After implementing DQP:
Core Served Impressions is a core dataset for product analytics of direct revenue, generating products within Twitter that many downstream customers consume to build their own specialized dataset for their product needs.
Data Quality Platform allowed Twitter to leverage open source libraries, Apache Airflow, and Great Expectations, and integrated with GCP services like GCS, PubSub, Dataflow, BigQuery and Looker. This provides an end-to-end automated solution to ensure accuracy and reliability of thousands of datasets ingested daily, increasing confidence in data being delivered to advertisers.
We are grateful for the following contributors that helped us to deliver the Data Quality Platform solution:
Josh Peng, Wini Tran, Tushar Arora, Joanna Douglas, Oguz Erdogmus, Katie Macias, Stacey Ko, Bhakti Narvekar, Kasie Okpala, Nathan Chang.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.