Infrastructure
Advancing Jupyter Notebooks at Twitter - Part 1
By
and
Thursday, 30 December 2021
Within Cortex Platform (Twitter’s ML Platform group), the Experimentation Tools (ET) team is chartered with providing a first-class platform and tooling for data scientists, ML researchers, and ML engineers at Twitter.
Twitter Notebook is our internal notebook solution that started as a small grassroots effort within Cortex around 2016. This effort began within a small working group of engineers across different teams and backgrounds with the high-level goal of introducing Notebooks as a de facto tool for leveling up Twitter’s Data Science and ML Development platform capabilities. This group took Twitter Notebook from an ambitious, early vision all the way to a top-level company initiative with 25x+ internal usership growth. Notebooks are now an integral part of our Data & ML Platform narrative.
In this blog post, we will discuss how we implemented the following features to improve the notebook experience:
Our ongoing goal is to provide a managed Jupyter Notebook environment, which is integrated and compatible with Twitter’s data and development ecosystem. We believe this approach enables our DS and ML teams to experiment faster with notebooks by easily accessing code, data, and tools.
Even though Jupyter Notebook has excellent out-of-the-box features that ML practitioners at Twitter enjoy, the notebook development environment was disconnected from the rest of Twitter’s engineering environment. Notebook customers manually had to deal with infrastructure, data, and source code to execute in a notebook environment. It was time-consuming and painful. To address these pain points, we decided to provide a managed Jupyter Notebook environment that could be deployed to any Twitter computing environment. We built first-class features to support the ML and DS teams’ initial development needs.
Our goal throughout this process has very much been to build on top of Open Source and to operate in harmony with the community and the public API boundaries (for example, JupyterLab plugins, IPython Magics, and ContentsManagers) without forking whenever possible. Twitter Notebook can be thought of as a suite of integrations that simply work with the typical Jupyter Notebook runtime to great effect.
In our time building Twitter Notebook, our team also made several open source contributions to the Jupyter community, such as building the asynchronous contents API and UNIX socket support to Notebook Server. We hope to continue building in the open and contributing upstream whenever possible.
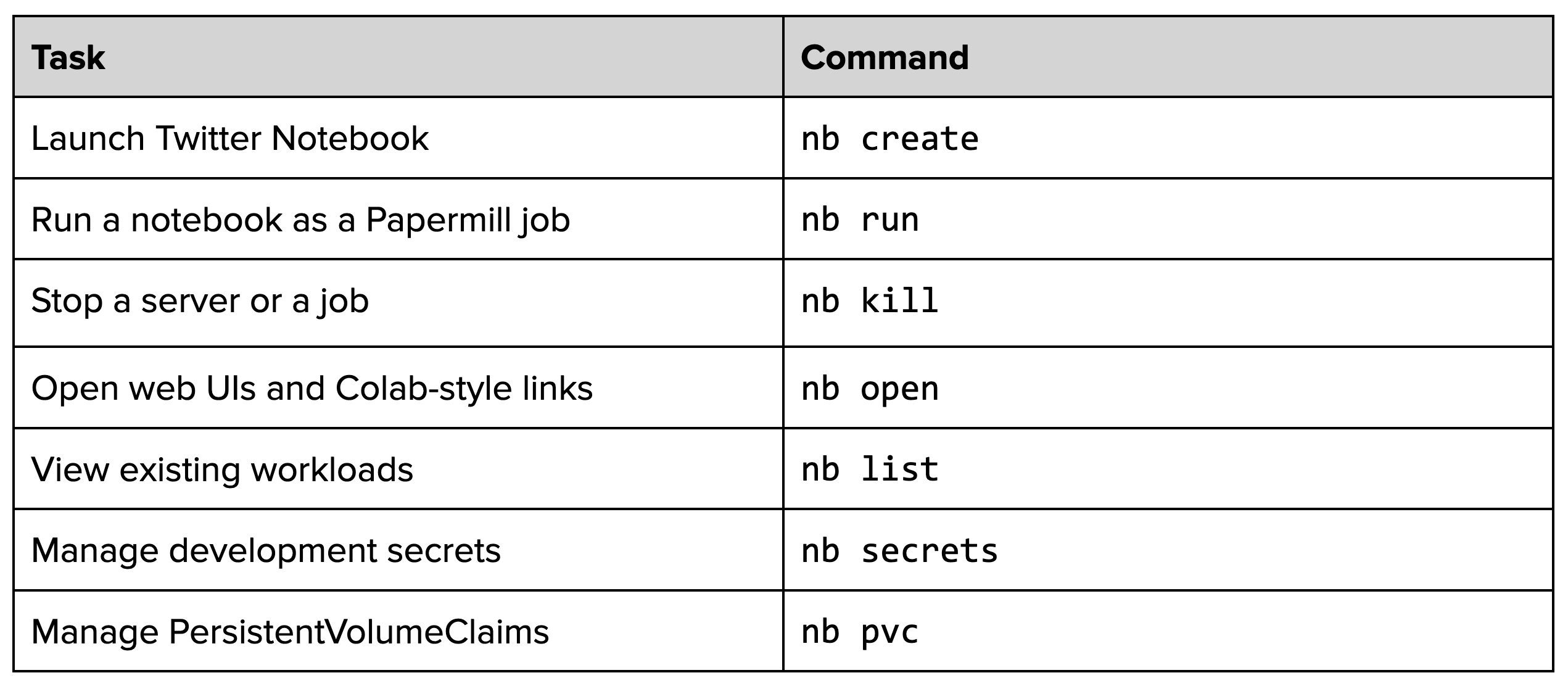
Twitter Notebook provides a seamless experience for managing the notebook lifecycle across the heterogeneous mix of on-premise and cloud-based compute clusters and zones that Twitter operates. This provides a high degree of flexibility for our customers to gain instant access to the exact type of hardware and operating environment they need for the task at hand. To enable this, we built a streamlined command-line interface (CLI), called nb, to help customers manage their Twitter Notebook resources in an intuitive way. The CLI interacts with Twitter’s Kubernetes and Mesos/Aurora clusters on behalf of the customer and abstracts away managing workloads in disparate infrastructure layers by providing easy-to-use and simple lifecycle commands. With the nb CLI, our customers can do the following:
By default, all Twitter engineers get this managed CLI installed on their laptops as part of our Managed Development Environment. This means that any employee in the company can use a fully functional notebook in about 60 seconds with a simple one line command (nb create) with zero installation steps required.
At Twitter, almost all of our development happens in a single monolithic git repository (aka a “monorepo”) that is shared across the entire company and >30GB in size. Internally, we refer to this as the “source” monorepo. We have an entire org within Twitter Platform (called Engineering Effectiveness) that is responsible for managing the tooling to support monorepo development.
Engineering Effectiveness provides a Managed Development Environment offering that provides this tool environment on MacOS laptops. It includes our custom git version for large-scale git repos, arcanist for our Phabricator-based code review system, kubectl and aurora CLI for Kubernetes and Mesos deployments, and many other tools and configurations. Almost all developers at Twitter bootstrap the monorepo repository locally to their MacOS laptops and use this local Managed Development Environment suite to conduct typical software development workflows.
To bring this integrated development experience to Twitter Notebooks, in a remote and Linux-based runtime, our team did a significant amount of work while following a “Remote Workspaces” mindset. This ranged from things as intrinsic as workload environment personalization (for example, ensuring that $USER and effective UIDs are consistently mapped in remote workloads) to partnering with tool-owning teams in Engineering Effectiveness to expose Linux-compatible development tools and processes for inclusion in our runtime environments.
The result of this initiative has been a mostly complete parity match with the laptop-based developer experience, with the benefit of server-grade hardware and datacenter-locality. Currently, any notebook customer can bootstrap a shallow copy of our monorepo in about two minutes and then begin working with all of the tooling they would expect to find on their laptops. For example, modifying code, committing it, going through code review and iteration, landing their change in the monorepo, and then deploying it.
These capabilities have been a boon for our DS and ML engineers, who routinely push around heavy-weight data and application payloads as part of experimentation and iteration. Twitter Notebook also helps avoid context-switching between local machines and notebook environments. With almost all of our staff working remotely during the pandemic and relying on home internet connections, the network-locality and stability properties that Twitter Notebooks have afforded have led to notable productivity improvements in our common workflows.
We are continuing to follow a “Remote Workspace” mindset, promoting, for example, technologies such as IDE Remoting using VS Code Remote. We’ll talk about these efforts in subsequent posts.
Now armed with a complete Twitter development environment, we also wanted to empower our customers to directly leverage live sources within a notebook kernel for rapid iteration and experimentation. Some of our customers prefer to have a standard pre-loaded set of Twitter code and 3rd-party dependencies, while others need to load bespoke libraries and dependencies from the codebase. To satisfy the needs of different customers, we built different types of customized kernels for Twitter Notebook.
Twitter Notebook supports three Python kernels: PyCX (short for “Python-Cortex”), pex, and pip. The Python kernels are all IPython-based.Each kernel has different default dependencies and different custom magic commands and scripts for adding additional dependencies. Twitter Notebook also offers a Scala kernel for Scalding and other Scala development at Twitter.
The PyCX kernel is a Cortex-managed standard Python environment for common DS and ML tasks. It uses a “batteries included” approach by bundling all of the commonly used third-party and internal DS and ML libraries in a large monolithic environment. This enables customers to import necessary dependencies without having to explicitly install and declare dependencies themselves. This kernel has continuous releases that track and reflect code and version changes in the Twitter monorepo.
For our customers who do not have their own code or dependencies to load, this kernel gives a straightforward environment to start their development. They don’t need to worry about dependency installation and can start developing right away with common libraries such as TensorFlow and TFX, PyTorch, XGBoost and many others.
The pex kernel gives customers full control and responsibility for their kernel environment in pex-based scenarios. Twitter’s monorepo uses pants, a build system like Bazel and Gradle, to bundle Python code and dependencies into hermetic executables called pex (Python EXecutable) files. With the pex kernel, customers can directly interoperate with pants (and the pex CLI) to live-load pex environments for use in notebook development.
To support this live-loading, we developed a small suite of IPython magic commands:
Each of these magics provide Python developers the flexibility they need to work on incremental development in notebook environments, alongside the Twitter monorepo, in tighter iteration loops. By using these magics, developers do not need, for example, to rebuild images or kernels to achieve the same results.
We recently open-sourced these magics in collaboration with Toolchain Labs for all to use. We also anticipate extending these plugins to support Bazel as part of Twitter’s multi-year Bazel migration.
For traditional Python development cases, we also provide a simple pip-managed kernel. It is similar to the standard Python kernel in Jupyter Notebook, but provides venv-based isolation and multi-environment support within the same notebook.
This kernel is intended for customers who wish to install and manage traditional Python distributions directly from internally accessible indexes without being limited to the third-party dependency versions available in Twitter’s monorepo.
Scalding is a widely used Scala-based data processing framework at Twitter. While PySpark is also available, our customers sometimes need to use Scalding to process data so that it is easier to read and write. In addition, some Scala developers at Twitter use notebooks for fast prototyping.
To meet these needs, contributors from various Twitter teams built a custom Scala kernel in Twitter Notebook. The Scala kernel is based on Ammonite and offers similar magic commands to the pex kernel for live-loading Scala dependencies from Twitter’s monorepo, including Scalding libraries.
At Twitter, we use Kerberos to authenticate to many backend systems. This authentication is essential to performing various tasks, such as reading and writing from git, posting code reviews, launching Spark jobs, and accessing HDFS and other internal storage or other systems. Much of Twitter’s tooling needs a valid Kerberos ticket to perform these sorts of tasks. For production cases, we rely on Kerberos keytabs which are only issued for service accounts. For human users, passwords are the only way to authenticate and cannot be stored as shared secrets.
Initially, customers could manually activate Kerberos by running kinit in a Twitter Notebook terminal and manually typing their password. However, this proved to be a cumbersome UX. To make the experience more seamless, we built a JupyterLab front-end extension that is bundled with Twitter Notebook.
Now, when a customer creates a new Twitter Notebook instance and opens its interface, a pop-up asks them to enter their Kerberos credentials for authentication, which can be quickly auto-filled using a password manager:
After the customer is authenticated successfully, the extension displays the Kerberos ticket validation time in JupyterLab’s status bar.
Once the Kerberos ticket expires, the extension will turn red and automatically prompt the customer to re-auth to maintain a valid Kerberos ticket.
For DS and ML use cases, Twitter also heavily uses Google Cloud services, which rely on an alternative authentication scheme. At the compute layer, when Twitter Notebook runs on Google Kubernetes Engine, it integrates with Workload Identity for automatic authentication for Google Cloud services. This ensures that customers do not need to explicitly establish authentication when working with Google Cloud Platform (GCP) systems. We also integrated Twitter Notebook with Twitter’s internal secret distribution system which allows for arbitrary credential storage for credentials like GCP service account keys.
Historically, DS and ML teams have had to access several disparate data storage systems to get the data they need. Until recently, most data was stored in BigQuery, HDFS, and Vertica and could be accessed with tools such as Presto, Spark, or Hive.
Without high-level data libraries to execute queries or launch Spark clusters, many folks would copy and paste their custom utility functions into notebooks to perform data operations. The custom utility functions in notebooks made code less maintainable and more error-prone. So we designed a library to take care of repetitive data operations such as authentication, configuration, and query execution.
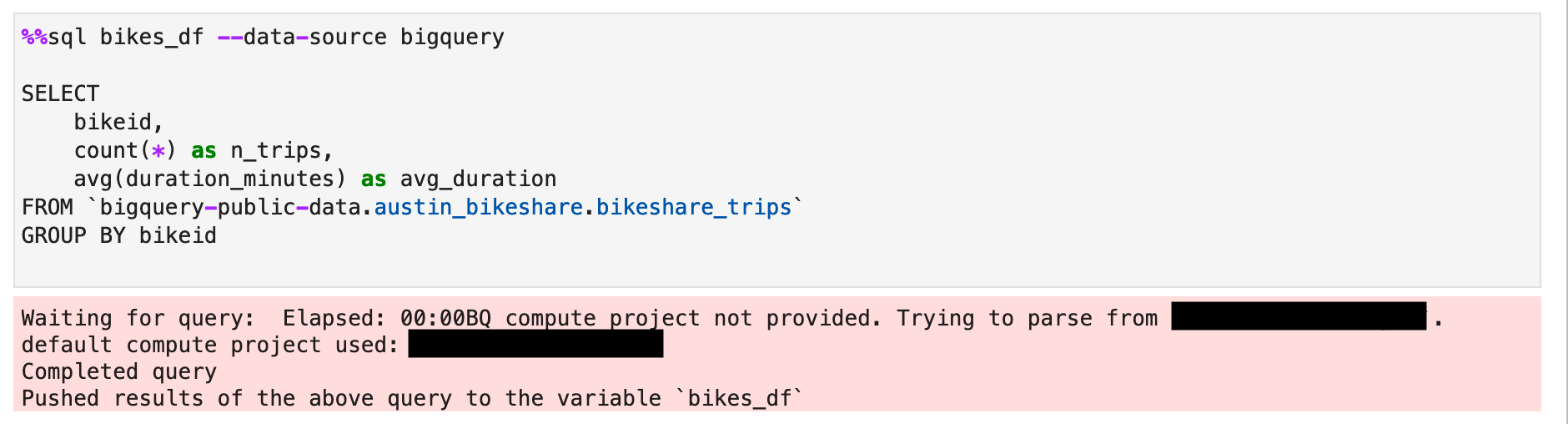
The Data Science Effectiveness team led the implementation of a simple interface to access the different SQL stores in Twitter Notebook. As more people utilized this library, we continuously added more functionality, such as BigQuery support and magic commands. For example, today, customers can execute the following cell to run a SQL query in a notebook and get a DataFrame of results back:
This magic is designed to take SQL queries directly in the cell without any additional code. It is available by default in the PyCX kernel, so customers do not need to declare any dependencies or imports.
When it comes to data analysis, the JupyterLab platform offers the flexibility to process data after retrieving it, unlike other tools such as business intelligence (BI) software. However, in the context of visualization, the tradeoff between a Jupyterlab Notebook and most BI tools is interactivity, which is more difficult and time-consuming to do in a notebook. Most existing Python visualization libraries generate static charts or do not configure commonly-used interactions such as filters.
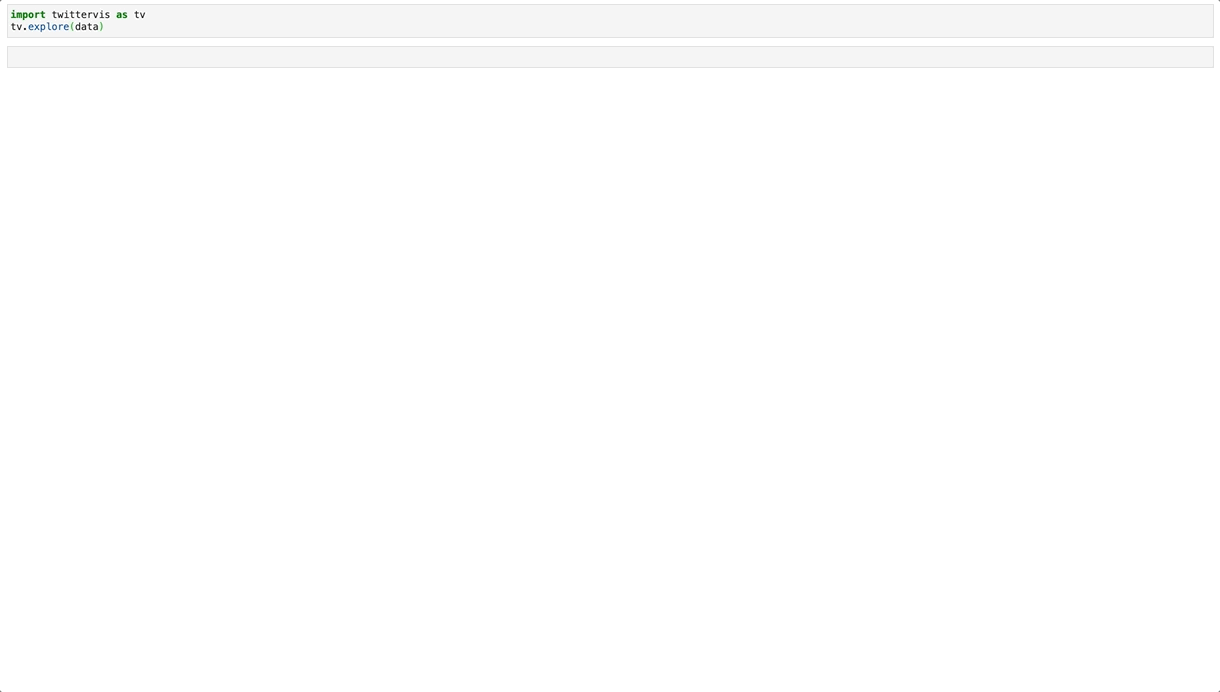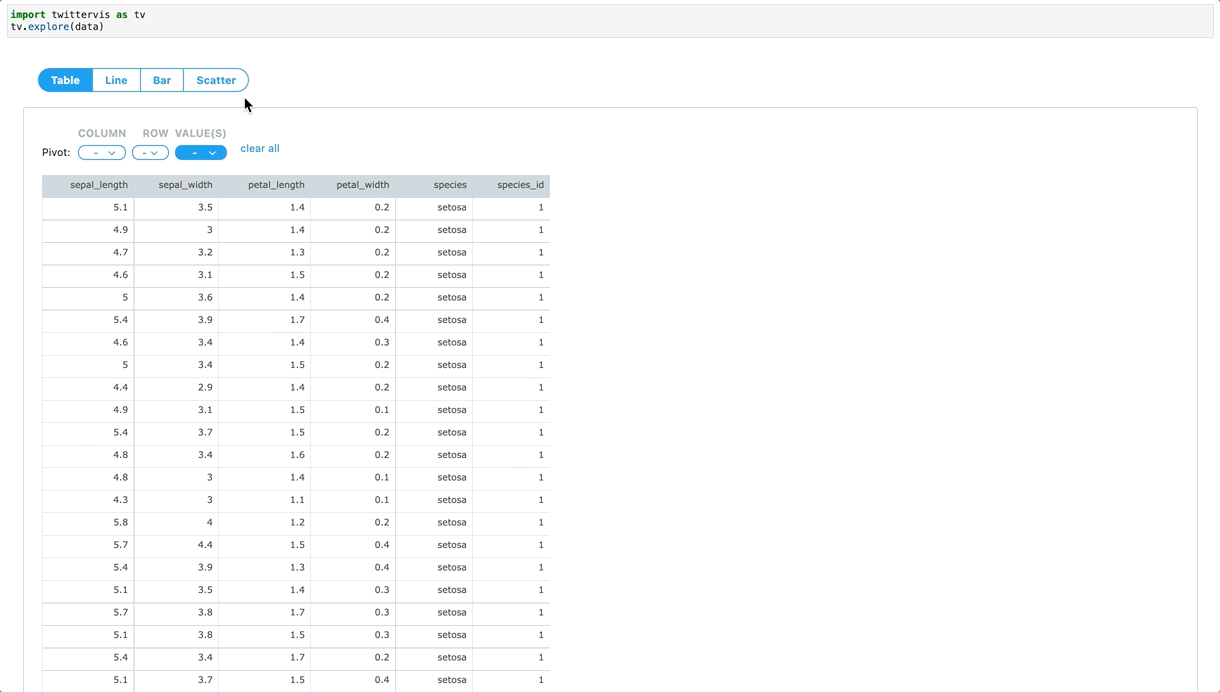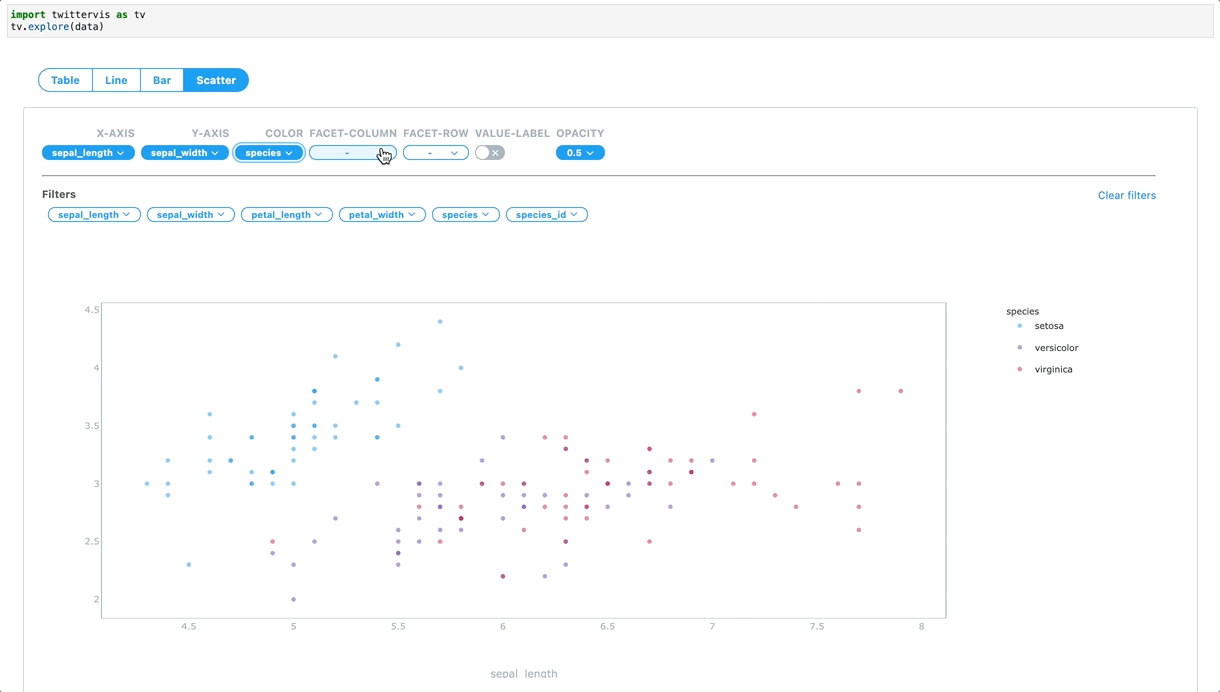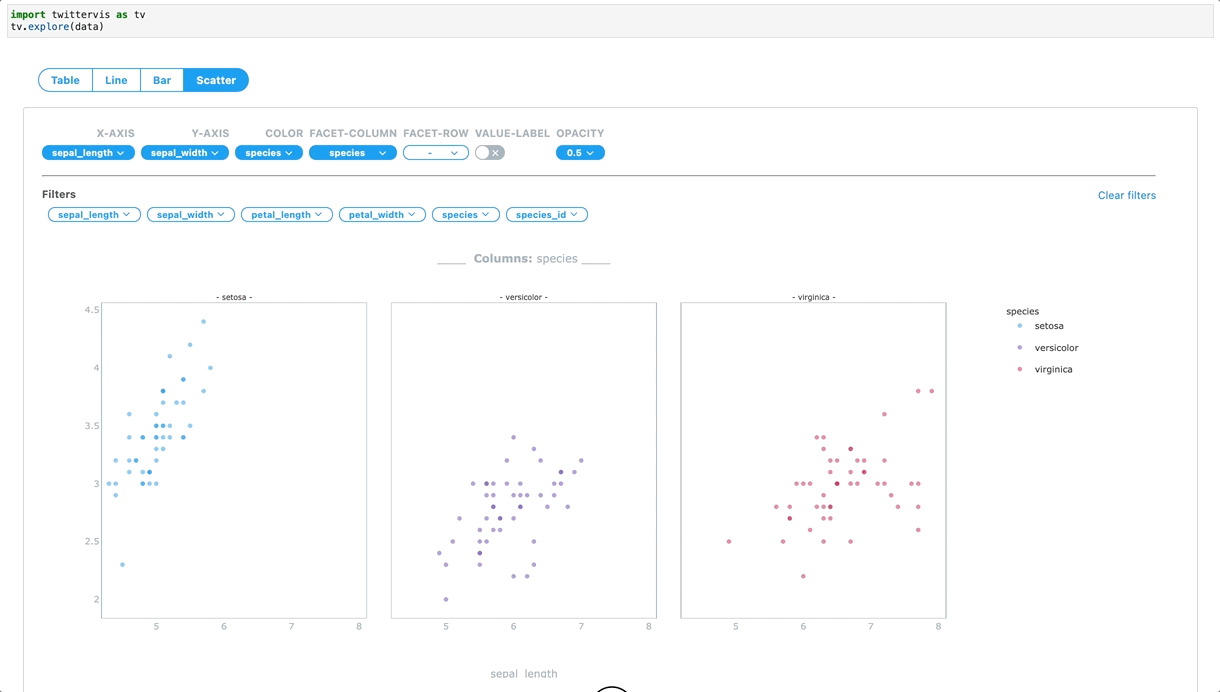
To make it faster and reproducible to go from a DataFrame to an interactive visualization, the Twitter Visualizations, Insights and Science (VIS) team developed TwitterVIS, a JupyterLab extension. TwitterVIS Data Explorer provides UI-based chart configurations and interactive chart views that can easily be shared in a published notebook. Data Explorer allows customers to quickly slice and dice data, and share data insights with minimal code. We abstracted the data transformation logic so that a customer can call a single function with a pandas DataFrame as an input.
Data Explorer, which exposes user-facing Python API endpoints, is the first custom ipywidget we have added to the TwitterVIS JupyterLab extension. We leveraged Twitter’s internal custom React components and also extended other open-source libraries in the Javascript and Python ecosystem, like Plotly. The ipywidget and extension framework gives our team the flexibility to focus on improving visualization creation at Twitter in the JupyterLab ecosystem. We are excited about developing more bespoke and interactive visualization systems that address specific data problems at Twitter.
At Twitter, we took the original Jupyter Notebook runtime and created a number of features such as authentication, flexible dependency management, tools to improve data access, access to source code, and enhanced data visualization. Subsequently, Twitter Notebook has drastically streamlined workflows for data scientists, applied researchers, and ML engineers.
As Twitter Notebook adoption increased, we added even more features and enhancements such as notebook storage, parameterized notebook jobs, improved performance and reliability, notebook sharing, Kubeflow support and much more. We hope to talk more about these features in subsequent blog posts. Stay tuned!
Twitter Notebook would not have been possible if not for the individual contributions and community behind it.
We would like to thank the following people for their contributions to the effort: Kris Wilson, Josh Hamet, Xiao Zhu, Mariko Wakabayashi, Lakshmi Doddi, Kunal Trivedi, Tural Badirkhanli, Aaron Gonazales, Sayan Sanyal, Mia Feng, Melba Madrigal Filous, Nikhil Devnani, Vishal Krishna, Redwan Rahman, Fred Dai, Nikhil Goyal, Shashank Singh, Rae Davis
We would like to thank our partners and supporters: Sameer Sundresh, Drew Gassaway, James Meador, John Sirois, Stu Hood, Benjy Weinberger, Todd Doughty
And a special thanks to our leadership for supporting the effort: Devin Goodsell, Bill Darrow, Ari Font, Derek Lyon, Richard Rabbat, Sandeep Pandey, Parag Agrawal
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.