
Flying faster with Twitter Heron
By
Tuesday, 2 June 2015
We process billions of events on Twitter every day. As you might guess, analyzing these events in real time presents a massive challenge. Our main system for such analysis has been Storm, a distributed stream computation system we’ve open-sourced. But as the scale and diversity of Twitter data has increased, our requirements have evolved. So we’ve designed a new system, Heron — a real-time analytics platform that is fully API-compatible with Storm. We introduced it yesterday at SIGMOD 2015.
Our rationale and approach
A real-time streaming system demands certain systemic qualities to analyze data at a large scale. Among other things, it needs to: process of billions of events per minute; have sub-second latency and predictable behavior at scale; in failure scenarios, have high data accuracy, resiliency under temporary traffic spikes and pipeline congestions; be easy to debug; and simple to deploy in a shared infrastructure.
To meet these needs we considered several options, including: extending Storm; using an alternative open source system; developing a brand new one. Because several of our requirements demanded changing the core architecture of Storm, extending it would have required longer development cycles. Other open source streaming processing frameworks didn’t perfectly fit our needs with respect to scale, throughput and latency. And these systems aren’t compatible with the Storm API – and adapting a new API would require rewriting several topologies and modifying higher level abstractions, leading to a lengthy migration process. So we decided to build a new system that meets the requirements above and is backward-compatible with the Storm API.
The highlights of Heron
When developing Heron, our main goals were to increase performance predictability, improve developer productivity and ease manageability. We made strategic decisions about how to architect the various components of the system to operate at Twitter scale.
The overall architecture for Heron is shown here in Figure 1 and Figure 2. Users employ the Storm API to create and submit topologies to a scheduler. The scheduler runs each topology as a job consisting of several containers. One of the containers runs the topology master, responsible for managing the topology. The remaining containers each run a stream manager responsible for data routing, a metrics manager that collects and reports various metrics and a number of processes called Heron instances which run the user-defined spout/bolt code. These containers are allocated and scheduled by scheduler based on resource availability across the nodes in the cluster. The metadata for the topology, such as physical plan and execution details, are kept in Zookeeper.
 Figure 1. Heron Architecture
Figure 1. Heron Architecture
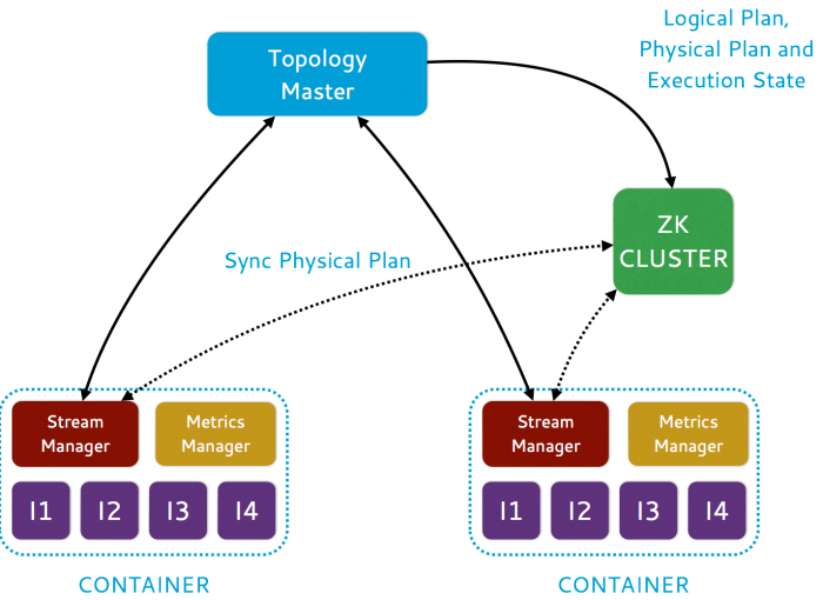 Figure 2. Topology Architecture
Figure 2. Topology Architecture
Specifically, Heron includes these features:
Off the shelf scheduler: By abstracting out the scheduling component, we’ve made it easy to deploy on a shared infrastructure running various scheduling frameworks like Mesos, YARN, or a custom environment.
Handling spikes and congestion: Heron has a back pressure mechanism that dynamically adjusts the rate of data flow in a topology during execution, without compromising data accuracy. This is particularly useful under traffic spikes and pipeline congestions.
Easy debugging: Every task runs in process-level isolation, which makes it easy to understand its behavior, performance and profile. Furthermore, the sophisticated UI of Heron topologies, shown in Figure 3 below, enables quick and efficient troubleshooting for issues.

 Figure 3. Heron UI showing logical plan, physical plan and status of a topology
Figure 3. Heron UI showing logical plan, physical plan and status of a topology
Compatibility with Storm: Heron provides full backward compatibility with Storm, so we can preserve our investments with that system. No code changes are required to run existing Storm topologies in Heron, allowing for easy migration.
Scalability and latency: Heron is able to handle large-scale topologies with high throughput and low latency requirements. Furthermore, the system can handle a large number of topologies.
Heron performance
We compared the performance of Heron with Twitter’s production version of Storm, which was forked from an open source version in October 2013, using word count topology. This topology counts the distinct words in a stream generated from a set of 150,000 words.

Figure 4. Throughput with acks enabled
 Figure 5. Latency with acks enabled
Figure 5. Latency with acks enabled
As shown in Figure 4, the topology throughput increases linearly for both Storm and Heron. However for Heron, the throughput is 10–14x higher than that of Storm in all experiments. Similarly, the end-to-end latency, shown in Figure 5, increases far more gradually for Heron than it does for Storm. Heron latency is 5-15x lower than Storm’s latency.
Beyond this, we have run topologies which scale to hundreds of machines, many of which handle sources that generate millions of events per second, without issues. Also with Heron, numerous topologies that aggregate data every second are able to achieve sub-second latencies. In these cases, Heron is able to achieve this with less resource consumption than Storm.
Heron at Twitter
At Twitter, Heron is used as our primary streaming system, running hundreds of development and production topologies. Since Heron is efficient in terms of resource usage, after migrating all Twitter’s topologies to it we’ve seen an overall 3x reduction in hardware, causing a significant improvement in our infrastructure efficiency.
What’s next?
We would like to collaborate and share lessons learned with the Storm community as well as other real-time stream processing system communities in order to further develop these programs. Our first step towards doing this was sharing our research paper on Heron at SIGMOD 2015. In this paper, you’ll find more details about our motivations for designing Heron, the system’s features and performance, and how we’re using it on Twitter.
Acknowledgements
Heron would not have been possible without the work of Sanjeev Kulkarni, Maosong Fu, Nikunj Bhagat, Sailesh Mittal, Vikas R. Kedigehalli, Siddarth Taneja (@staneja), Zhilan Zweiger, Christopher Kellogg, Mengdie Hu (@MengdieH) and Michael Barry.
We would also like to thank the Storm community for teaching us numerous lessons and for moving the state of distributed real-time processing systems forward.
References
[1] Twitter Heron: Streaming at Scale, Proceedings of ACM SIGMOD Conference, Melbourne, Australia, June 2015
[2] Storm@Twitter, Proceedings of ACM SIGMOD Conference, Snowbird, Utah, June 2014
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.