
Push our limits - reliability testing at Twitter
By
Tuesday, 2 September 2014
At Twitter, we strive to prepare for sustained traffic as well as spikes - some of which we can plan for, some of which comes at unexpected times or in unexpected ways. To help us prepare for these varied types of traffic, we continuously run tests against our infrastructure to ensure it remains a scalable and highly available system.
Our Site Reliability Engineering (SRE) team has created a framework to perform different types of load and stress tests. We test different stages of a service life cycle in different environments (e.g., a release candidate service in a staging environment). These tests help us anticipate how our services will handle traffic spikes and ensure we are ready for such events.
Additionally, these tests help us to be more confident that the loosely coupled distributed services that power Twitter’s products are highly available and responsive at all times and under any circumstance.
As part of our deploy process before releasing a new version of a service, we run a load test to check and validate the performance regressions of the service to estimate how many requests a single instance can handle.
While load testing a service in a staging environment is a good release practice, it does not provide insight into how the overall system behaves when it’s overloaded. Services under load fail due to a variety of causes including GC pressure, thread safety violations and system bottlenecks (CPU, network).
Below are the typical steps we follow to evaluate a service’s performance.
Performance evaluation
We evaluate performance in several ways for different purposes; these might be broadly categorized:
In staging
In production
In this blog, we are primarily focusing on our stress testing framework, challenges, lessons learned, and future work.
Framework
We usually don’t face the typical performance testing problems such as collecting services’ metrics, allocating resources to generate the load or implementing a load generator. Obviously, any part of your system at scale could get impacted, but some are more resilient and some require more testing. Even though we are still focusing on the items mentioned above, in regards to this blog and this type of work, we are focusing on system complexity and scalability. As part of our reliability testing, we generate distributed multi-datacenter load to analyze the impact and determine the bottlenecks.
Our stress-test framework is written in Scala and leverages Iago to create load generators that run on Mesos. Its load generators send requests to the Twitter APIs to simulate Tweet creation, message creation, timeline reading and other types of traffic. We simulate patterns from past events such as New Year’s Eve, the Super Bowl, the Grammys, the State of the Union, NBA Finals, etc.
The framework is flexible and integrated with the core services of Twitter infrastructure. We can easily launch jobs that are capable of generating large traffic spikes or a high volume of sustained traffic with minor configuration changes. The configuration file defines the required computational resources, transactions rate, transactions logs, the test module to use, and the targeted service. Figure 1 below shows an example of a launcher configuration file:
new ParrotLauncherConfig {
// Aurora Specification
role = "limittesting"
jobName = "limittesting"
serverDiskInMb = 4096
feederDiskInMb = 4096
mesosServerNumCpus = 4.0
mesosFeederNumCpus = 4.0
mesosServerRamInMb = 4096
mesosFeederRamInMb = 4096
numInstances = 2
// Target systems address
victimClusterType = "sdzk"
victims = "/service/web"
// Test specification
hadoopConfig = "/etc/hadoop/conf"
log = "hdfs://hadoop-nn/limittesting/logs.txt"
duration = 10
timeUnit = "MINUTES"
requestRate = 1000
// Testing Module
imports = "import com.twitter.loadtest.Eagle"
responseType = "HttpResponse"
loadTest = "new EagleService(service.get)"
}
The framework starts by launching a job in Aurora, the job scheduler for Mesos. It registers itself in Zookeeper, and publishes into the Twitter observability stack (Viz) and distributed tracing system (Zipkin). This seamless integration lets us monitor the test execution. We can measure test resource usage, transaction volume, transaction time, etc. If we want to increase the traffic volume, we only need a few clicks to change a variable.
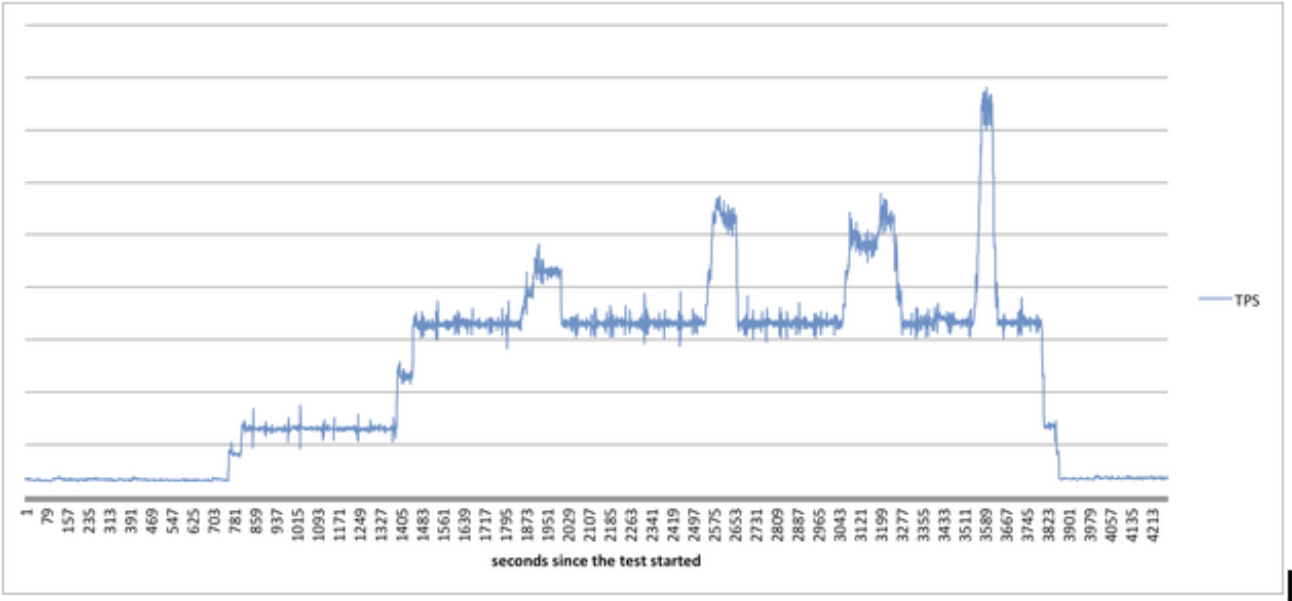
Figure 2: Load generated during a stress test
Challenges
Comparing the performance characteristics of test runs is complicated. As we continuously integrate and deliver changes across all services, it gets harder to identify a baseline to compare against. The test’s environment changes many times between test runs due to many factors such as new service builds and releases. The inconsistency in test environments makes it difficult to determine the change that introduced the bottlenecks.
If a regression is identified, we study what could contribute to it including, but not limited to, how services behave under upstream and downstream failures, and changes in traffic patterns. In some cases, detecting the root cause can be challenging. The anomaly we detect might not be the root cause, but rather a side effect of upstream or downstream issues. Finding the root cause between thousands of changes across many services is a time consuming process and might require lots of experiments and analysis.
Generating the test traffic against a single or multiple data centers requires careful planning and a test case design. Many factors need to be taken into consideration (like cache hit ratio). A cache miss for a tweet read can trigger a cache fill which in turn triggers multiple backend read requests to fill the data. Because things like a cache miss is much more expensive than a cache hit, the generated test traffic must respect these factors to get accurate tests results that match production traffic patterns.
Since our platform is real-time, it’s expected for us to observe extra surges of traffic at any point. The two more frequent kinds of load we have seen: heavy traffic during a special event for a few minutes or hours, and spikes that happen in a second or two when users share a moment. Simulating the spikes that last for a few seconds while monitoring the infrastructure to detect anomalies in real time is a complicated problem, and we are actively working on improving our approach.
Lesson learned
Our initial focus was on overloading the entire Tweet creation path to find limits in specific internal services, verify capacity plans, and understand the overall behavior under stress. We expected to identify weaknesses in the stack, adjust capacity and implement safety checks to protect minor services from upstream problems. However, we quickly learned this approach wasn’t comprehensive. Many of our services have unique architectures that make load testing complicated. We had to focus on prioritizing our efforts, review the main call paths, then design and cover the major scenarios.
An example is our internal web crawler service that assigns site crawling tasks to a specific set of machines in a cluster. The service does this for performance reasons since those machines have higher probability of having an already-established connection to the target site. This same service replicates its already-crawled sites to the other data centers to save computing resources and outbound internet bandwidth.
Addressing all of these steps complicated the collection of links, their types and their distribution during the test modeling. The distribution of links among load generators throughout the test was a problem because these were real production websites.
In response to those challenges, we designed a system that distributes links across all our load generators in a way that guarantees no more than N links of any website are crawled per second across the cluster. We had to specify the link types and distribution carefully. We might have overwhelmed the internal systems if most of the links were invalid, spammy or contain malware. Additionally, we could have overwhelmed the external systems if all links were for a single website. The stack’s overall behavior changes as the percentage of each category changes. We had to find the right balance to design a test that covered all possible scenarios. These custom procedures repeat every time we model new tests.
We started our testings methodologies by focusing on specific site features such as tweet write and read paths. Our first approach was to simulate high volume of sustained tweets creation and reads. Due to the real-time nature of our platform, variation of spikes, and types of traffic we observe, we continuously expand our framework to cover additional features such as users retweeted Tweets, favorited Tweets, conversations, etc. The variety of our features (Tweets, Tweet with media, searches, Discover, timeline views, etc) requires diversity in our approach in order to ensure the results of our test simulations are complete and accurate.
Twitter’s internal services have mechanisms to protect themselves and their downstreams. For example, a service will start doing in-process caching to prevent cache overwhelming or will raise special exceptions to trigger upstream retry/backoff logic. This complicates test execution because the cache shields downstream services from the load. In fact, when in-process cache kicks in, the service’s overall latency decreases since it no longer requires a round trip to the distributed caches. We had to work around such defence mechanisms by creating multiple tests models around a single test scenario. One test verifies the in-process cache has kicked in; another test simulates the service’s behavior without the in-process cache. This process required changes across the stack to pass and respect special testing flags. After going through that process, we learned to design and architect services with reliability testing in mind to simplify and speed up future tests’ modeling and design.
Future work
Since Twitter is growing rapidly and our services are changing continuously, our strategies and framework should as well. We continue to improve and in some case redesign our performance testing strategy and frameworks. We are automating the modeling, design, execution of our stress tests, and making the stress-testing framework context-aware so it’s self driven and capable of targeting a specific or N datacenters. If this sounds interesting to you, we could use your help — join the flock!
Special thanks to Ali Alzabarah for leading the efforts to improve and expand our stress-test framework and his hard work and dedication to this blog.
Many thanks to a number of folks across @twittereng, specifically — James Waldrop, Tom Howland, Steven Salevan, Dmitriy Ryaboy and Niranjan Baiju. In addition, thanks to Joseph Smith, Michael Leinartas, Larry Hosken, Stephanie Dean and David Barr for their contributions to this blog post.
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.