
Building a Faster Ruby Garbage Collector
Friday, 4 March 2011
Since late 2009, much of www.twitter.com has run on Ruby Enterprise Edition (REE), a modified version of the standard MRI 1.8.7 Ruby interpreter. At the time, we worked with the REE team to integrate some third-party patches that allowed us to tune the garbage collector for long-lived workloads. We knew this was not a perfect choice, but a switch to a new runtime (even MRI 1.9x) would introduce compatibility problems, and testing indicated that alternative runtimes are not necessarily faster for our workload. Nevertheless, the CPU cost of REE remained too high.
To address this problem, we decided to explore options for optimizing the REE runtime. We called this effort Project Kiji, after the Japanese bird.
Our performance measurements revealed that even after our patches, the Ruby runtime uses a significant fraction of the CPU for running the garbage collector on twitter.com. This is largely because MRI’s garbage collector uses a single heap:
We needed to make the garbage collector more efficient but had limited options. We couldn’t easily change the runtime’s stop-the world-process because internally it relies on being single-threaded. Neither could we implement a real generational collector because our interpreter relies on objects staying at the same address in memory.
While we could not change the location of an allocated object, we assumed we could allocate the objects in a different location, depending on their expected lifetime. So, first, we separated the live objects into transient objects and long-lived objects. Next, we added another heap to Ruby and called it “longlife” heap.
According to the current implementation, Kiji has two heaps:
In the new configuration, AST (Abstract Syntax Tree) nodes occur in longlife heaps. They are a parsed representation of the Ruby programs’ source code construct (such as name, type, expression, statement, or declaration). Once loaded, they tend to stick in memory, and are largely immutable. They also occupy a large amount of memory: in twitter.com’s runtime, they account for about 60% of live objects at any given time. By placing the AST nodes in a separate longlife heap and running an infrequent garbage collection only on this heap, we saw a significant performance gain: the time the CPU spends in garbage collection reduced from 18.5% to 14%.
With infrequent collection, the system retains some garbage in memory, which increases overall memory use. We experimented with various scheduling strategies for longlife garbage collection that balanced the tradeoff between CPU usage and memory usage. We finally selected a strategy that triggers a collection scheduled to synchronize with the 8th collection cycle of the ordinary heap if an allocation occurs in the longlife heap. If the longlife heap does not receive an allocation, subsequent collections on the longlife heap occur after the 16th, 32nd, 64th collection cycle and so on, with each occurrence increasing exponentially.
A second heap improved garbage collection but we needed to ensure that the objects in the longlife heap continued to keep alive those objects they referenced in the ordinary heap. Due to a separation in heaps, we were now processing the majority of our ordinary heap collections without a longlife collection. Therefore, ordinary objects—reachable only through longlife objects—would not be marked as live and could, mistakenly, be swept as garbage. We needed to maintain a set of “remembered objects” or boundary objects that would live in the ordinary heap but were directly referenced by objects living in the longlife heap.
This proved to be a far greater challenge than originally expected. At first we added objects to the remembered set whenever we constructed an AST node. However, the AST nodes are not uniformly immutable. Following a parse, the Ruby interpreter tends to rewrite them immediately to implement small optimizations on them. This frequently rewrites the pointers between objects. We overcame this problem by implementing an algorithm that is similar to the mark phase, except that it is not recursive and only discovers direct references from the longlife to the ordinary heap. We run the algorithm at ordinary collection time when we detect that prior changes have occurred in the longlife heap. The run decreases in frequency over time; the longer the process runs, the more the amount of loaded code that stagnates. In other words, we are consciously optimizing for long-running processes.
An additional optimization ensures that if an ordinary object points to a longlife object, the marking never leaves the ordinary heap during the mark phase. This is because all outgoing pointers from the longlife heap to the ordinary heap are already marked as remembered objects. The mark algorithm running through the longlife heap reference chains does not mark any new objects in the ordinary heap.
The graph below shows the performance curves of the twitter.com webapp on various Ruby interpreter variants on a test machine with a synthetic load (not indicative of our actual throughput). We took out-of-the-box Ruby MRI 1.8.7p248, REE 2010.02 (on which Kiji is based), and Kiji. In addition, we tested REE and Kiji in two modes: one with the default settings, the other with GC_MALLOC_LIMIT tuned to scale back speculative collection. We used httperf to stress the runtimes with increasing numbers of requests per second, and measured the rate of successful responses per second. As you can see, the biggest benefit comes from the GC tuning, but Kiji’s two-heap structure also creates a noticeable edge over standard REE.

We have also measured the CPU percentage spent in the GC for these variants, this time with actual production traffic. We warmed up the runtimes first, then explicitly shut off allocations in the longlife heap once it was unlikely that any genuinely long-lived AST nodes would be generated. The results are below.
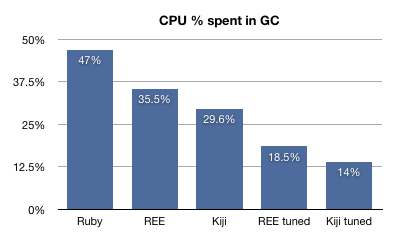
With Kiji, the garbage collector now consumes a smaller portion of the CPU for Ruby processes, and more importantly, enables additional improvements. As we identify additional objects to move to the longlife heap, we can further decrease the overall CPU usage. The theoretical floor is about 5% of total CPU time spent in the GC. We will be posting updates with new results.
A major source of inspiration was the patch by Narihiro Nakamura (available here). Narihiro’s patch is a proof-of-concept; it handles few AST nodes. It is also written as a patch for MRI 1.9, and we needed to cross-port it to REE, which is a derivative of MRI 1.8.7. We substantially extended Narihiro’s work to include algorithmic boundary set calculation and stop the ordinary mark from leaving the ordinary heap. We also ensured our solution integrated well with REE’s strategy for avoiding copy-on-write of objects in forked process in the mark phase. These changes delivered significant gains.
We have released the Kiji REE branch on GitHub, and hope that a future version will be suitable for merging into REE itself. In our case, switching to Kiji brought a 13% increase in the number of requests twitter.com can serve per second.
The following engineers at Twitter contributed to the REE improvements: Rob Benson, Brandon Mitchell, Attila Szegedi, and Evan Weaver.
— Attila (@asz)
Did someone say … cookies?
X and its partners use cookies to provide you with a better, safer and
faster service and to support our business. Some cookies are necessary to use
our services, improve our services, and make sure they work properly.
Show more about your choices.